
Grundlagen des relationalen Datenbankdesigns

Die meisten Datenbankprobleme werden nicht durch schlechte Abfragen verursacht – sie entstehen durch ein schlechtes Schema. Wenn Ihre Tabellen von Anfang an schlecht strukturiert sind, kann auch noch so cleveres SQL dies nicht vollständig kompensieren. Dieser Artikel behandelt die Kernprinzipien des relationalen Datenbankdesigns: wie Sie Tabellen strukturieren, Schlüssel definieren, Beziehungen modellieren und Constraints verwenden, um Ihre Daten zuverlässig zu halten.
Wichtigste Erkenntnisse
- Eine relationale Datenbank speichert Daten in Tabellen, die durch Schlüssel verknüpft sind, nicht durch Duplizierung von Informationen
- Primärschlüssel identifizieren Zeilen eindeutig; Fremdschlüssel drücken Beziehungen zwischen Tabellen aus
- 1:n-Beziehungen verwenden einen Fremdschlüssel auf der „n”-Seite, während n:m-Beziehungen eine Verknüpfungstabelle erfordern
- Normalisierung (1NF, 2NF, 3NF) reduziert Redundanz und verhindert Datenanomalien, wobei bewusste Denormalisierung manchmal gerechtfertigt ist
- Datenbank-Constraints (
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,CHECK) sind Ihre letzte Verteidigungslinie für Datenintegrität
Was eine relationale Datenbank tatsächlich ist
Eine relationale Datenbank speichert Daten in Tabellen – strukturierten Rastern aus Zeilen und Spalten. Jede Tabelle repräsentiert ein einzelnes Thema oder eine Entität, wie users, orders oder products. Jede Zeile ist ein Datensatz. Jede Spalte ist ein Attribut dieses Datensatzes.
Die Stärke des relationalen Modells liegt darin, Tabellen miteinander zu verknüpfen, anstatt Daten über sie hinweg zu duplizieren. Das Konzept stammt aus dem relationalen Modell, das Edgar F. Codd 1970 vorgeschlagen hat und das noch immer die theoretische Grundlage moderner SQL-Datenbanken bildet.
Primärschlüssel und Fremdschlüssel: Das Fundament relationaler Schemata
Jede Tabelle benötigt einen Primärschlüssel – eine Spalte (oder Kombination von Spalten), die jede Zeile eindeutig identifiziert. Ein guter Primärschlüssel ist:
- Eindeutig über alle Zeilen hinweg
- Niemals null
- Stabil – er sollte sich nach der Zuweisung nicht ändern
Die meisten modernen SQL-Datenbanken unterstützen Identity-Spalten (automatisch inkrementierende Ganzzahlen), die eindeutige Bezeichner automatisch generieren. Viele Systeme unterstützen auch UUID-basierte Schlüssel, die oft durch eingebaute Datenbankfunktionen oder Standardwerte generiert werden. Beide sind je nach Kontext valide Optionen. Automatisch inkrementierende Ganzzahlen sind einfach und effizient. UUIDs eignen sich besser für verteilte Systeme, in denen mehrere Quellen unabhängig voneinander Datensätze generieren.
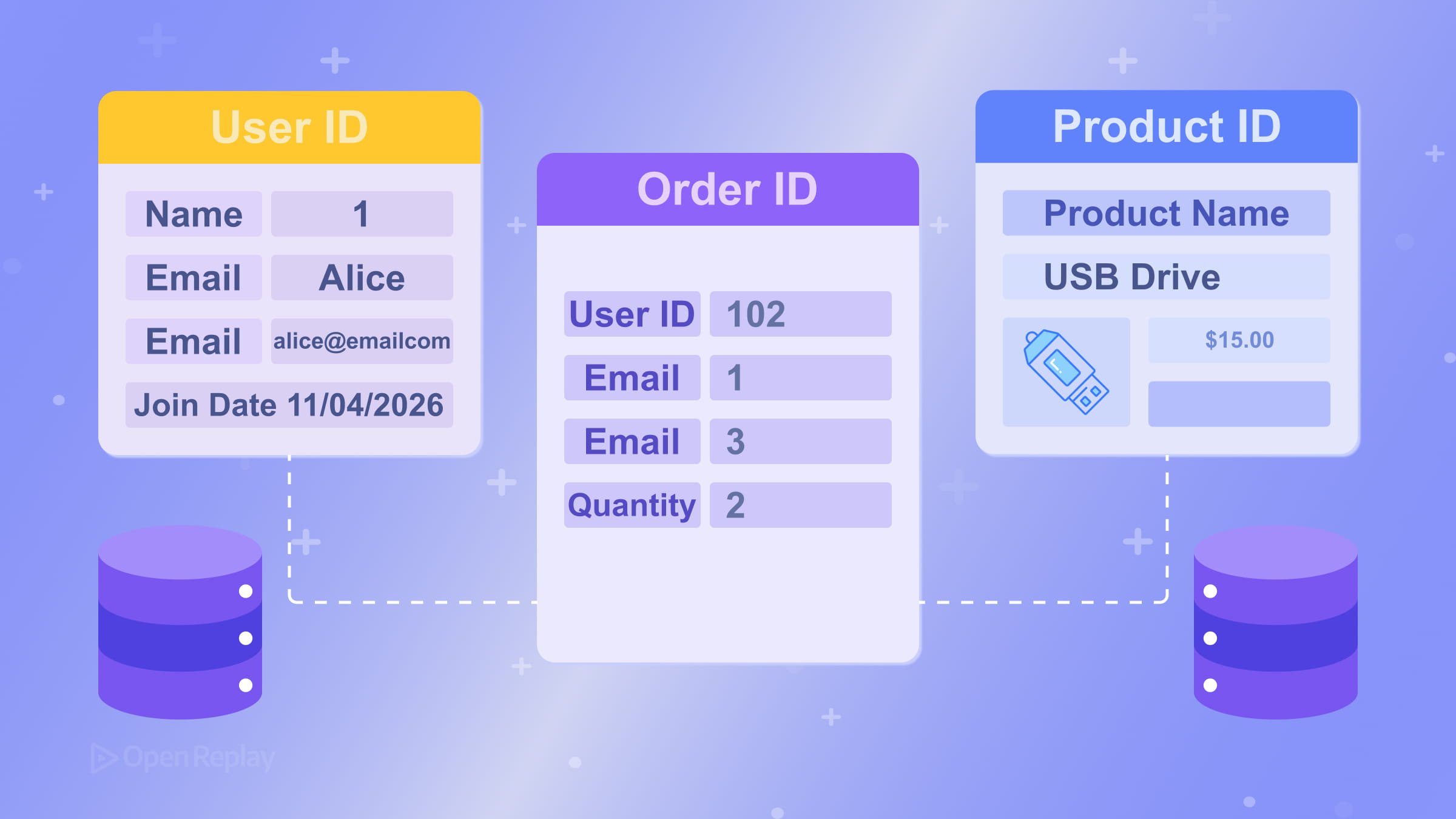
Ein Fremdschlüssel ist eine Spalte in einer Tabelle, die auf den Primärschlüssel einer anderen verweist. So werden Beziehungen zwischen Tabellen ausgedrückt. Beispielsweise könnte eine orders-Tabelle eine customer_id-Spalte haben, die auf customers.id verweist. Die Datenbank kann diese Verknüpfung erzwingen und verwaiste Datensätze verhindern. Ein konkretes Beispiel finden Sie in der PostgreSQL-Dokumentation zu Fremdschlüssel-Constraints.
Modellierung von Beziehungen: 1:n und n:m
Die häufigste Beziehung im relationalen Datenbankdesign ist 1:n (one-to-many): Ein Kunde hat viele Bestellungen, ein Autor hat viele Beiträge. Sie modellieren dies, indem Sie den Fremdschlüssel auf der „n”-Seite platzieren.
n:m-Beziehungen (many-to-many) – wie Studenten, die sich für Kurse einschreiben – erfordern eine Verknüpfungstabelle (auch assoziative Tabelle oder Brückentabelle genannt). Anstatt zu versuchen, mehrere Werte in einer einzelnen Spalte zu speichern, erstellen Sie eine dritte Tabelle (enrollments) mit Fremdschlüsseln, die auf sowohl students als auch courses verweisen. Dies hält das Schema sauber und abfragbar.

Discover how at OpenReplay.com.
Datenbanknormalisierung erklärt
Datenbanknormalisierung ist der Prozess der Strukturierung von Tabellen zur Reduzierung von Redundanz und zur Verhinderung von Datenanomalien. Die drei praktischsten Normalformen sind:
- 1NF (Erste Normalform): Jede Zelle enthält einen Wert – keine kommagetrennten Listen, keine sich wiederholenden Spaltengruppen
- 2NF (Zweite Normalform): Jede Nicht-Schlüsselspalte hängt vom gesamten Primärschlüssel ab, nicht nur von einem Teil davon (dies gilt hauptsächlich für Tabellen mit zusammengesetzten Primärschlüsseln)
- 3NF (Dritte Normalform): Nicht-Schlüsselspalten hängen nur vom Primärschlüssel ab – nicht voneinander
Normalisierung ist eine Richtlinie, kein Gesetz. Stark normalisierte Schemata sind einfacher zu warten, können aber mehr Joins erfordern. Einige Teams denormalisieren gezielt bestimmte Tabellen für lesintensive Workloads. Das richtige Gleichgewicht hängt von Ihren Abfragemustern und Leistungsanforderungen ab. Eine detailliertere Übersicht über die Theorie hinter Datenbanknormalisierung ist auf Wikipedia verfügbar.
Durchsetzung von Integrität mit Constraints
Validierung auf Anwendungsebene allein reicht nicht aus. Wenn mehrere Services in Ihre Datenbank schreiben oder jemand eine direkte SQL-Abfrage ausführt, werden Ihre anwendungsseitigen Prüfungen vollständig umgangen. Datenbank-Constraints sind Ihre letzte Verteidigungslinie:
PRIMARY KEY– erzwingt Eindeutigkeit und Nicht-Null beim BezeichnerFOREIGN KEY– stellt sicher, dass referenzierte Zeilen tatsächlich existierenUNIQUE– verhindert doppelte Werte in einer Spalte (nützlich für E-Mails, Benutzernamen)NOT NULL– verhindert fehlende Werte, wenn ein Feld erforderlich istCHECK– validiert, dass ein Wert eine Bedingung erfüllt (z. B.price > 0)
Die meisten modernen SQL-Datenbanken unterstützen auch generierte Spalten – Werte, die automatisch aus anderen Spalten berechnet werden – was redundante Logik in Ihrer Anwendungsschicht reduzieren kann. Die Implementierungen variieren zwischen den Engines (PostgreSQL, MySQL, SQL Server handhaben diese jeweils unterschiedlich), aber das Konzept ist weitgehend verfügbar. PostgreSQL dokumentiert beispielsweise generierte Spalten in seiner offiziellen Dokumentation.
Ein praktisches Schema-Beispiel
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);Dieses Beispiel verwendet PostgreSQL-SQL-Syntax. Es erzwingt referenzielle Integrität, verhindert Null-E-Mails und validiert, dass Bestellsummen nicht negativ sind – alles auf Datenbankebene.
Beachten Sie, dass GENERATED ALWAYS AS IDENTITY Standard-SQL ist (unterstützt in PostgreSQL 10+, Oracle 12c+ und DB2). Wenn Sie MySQL verwenden, würden Sie stattdessen AUTO_INCREMENT verwenden. In SQL Server lautet das Äquivalent IDENTITY(1,1). Details finden Sie in der PostgreSQL-Dokumentation zu Identity-Spalten.
Fazit
Gutes relationales Datenbankdesign läuft auf eine Idee hinaus: Jede Tabelle sollte eine Sache repräsentieren, und jedes Datenelement sollte an genau einem Ort leben. Wenden Sie dies konsequent an, verwenden Sie Constraints, um zu erzwingen, wie die Daten aussehen müssen, und Ihr Schema bleibt wartbar, während Ihre Anwendung wächst. Die hier behandelten Prinzipien – Primär- und Fremdschlüssel, Normalisierung, Beziehungsmodellierung und Constraint-Durchsetzung – bilden das Fundament, auf dem jede zuverlässige Datenbank aufgebaut ist.
Häufig gestellte Fragen (FAQs)
Verwenden Sie UUIDs, wenn Datensätze über mehrere Datenbanken oder Services hinweg generiert werden, die ohne Schlüsselkollisionen zusammengeführt werden müssen. Automatisch inkrementierende Ganzzahlen sind einfacher, benötigen weniger Speicherplatz und sind schneller für die Indizierung. Für die meisten Einzeldatenbank-Anwendungen funktionieren Ganzzahlen gut. Wählen Sie UUIDs, wenn Sie global eindeutige Bezeichner in verteilten oder mandantenfähigen Architekturen benötigen.
Beginnen Sie mit der dritten Normalform (3NF) als Baseline. Wenn jede Nicht-Schlüsselspalte ausschließlich vom Primärschlüssel abhängt und Sie keine wiederholten Daten über Zeilen hinweg haben, sind Sie auf einem guten Weg. Wenn Abfragen aufgrund übermäßiger Joins zu langsam werden, erwägen Sie selektive Denormalisierung bei bestimmten leseintensiven Tabellen, anstatt die Normalisierung vollständig aufzugeben.
Ohne Fremdschlüssel-Constraints kann die Datenbank verwaiste Datensätze nicht verhindern. Sie könnten am Ende Bestellungen haben, die auf nicht mehr existierende Kunden verweisen, oder Einschreibungszeilen, die auf gelöschte Kurse zeigen. Anwendungscode kann Randfälle übersehen, insbesondere wenn mehrere Services oder manuelle Abfragen Daten ändern. Fremdschlüssel fangen diese Probleme auf Datenbankebene ab.
Ja, bewusste Denormalisierung ist eine gängige und valide Praxis für leseintensive Workloads. Der Schlüssel liegt darin, dies absichtlich zu tun und die Kompromisse zu dokumentieren. Denormalisierte Tabellen sind schneller abzufragen, aber schwieriger zu warten, da Updates zu duplizierten Daten propagiert werden müssen. Verwenden Sie sie selektiv dort, wo die Abfrageleistung es erfordert, nicht als standardmäßige Designentscheidung.
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..
