LLM-Harnesses: Warum der Wrapper wichtiger ist als das Modell
Nicht nur das Modell zählt: LLM-Harnesses bestimmen den Agentenerfolg. Orchestrierung, Tools, Kontext und Verifikation im Fokus.

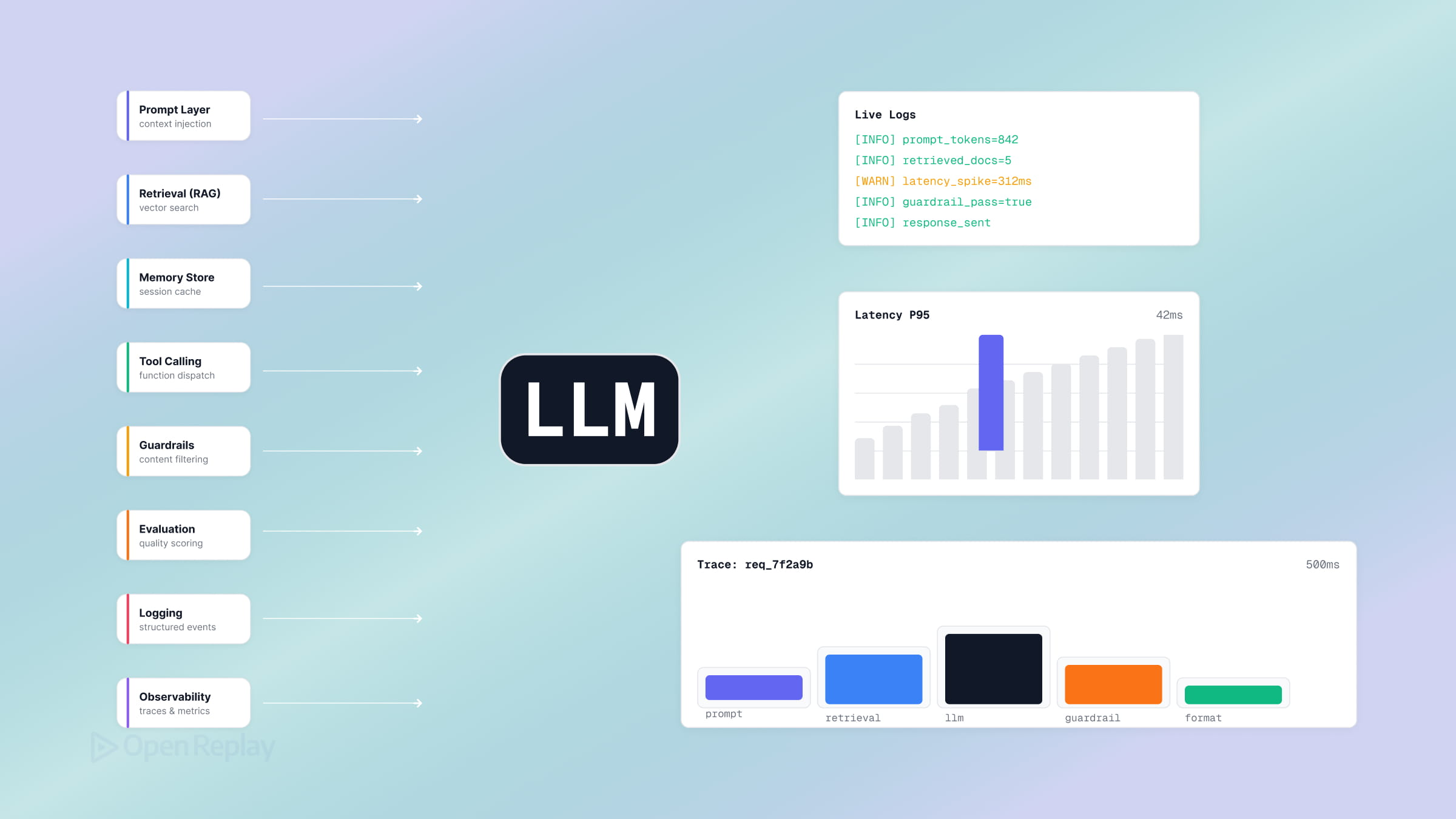
Der Harness umfasst jeden Code-Abschnitt, jede Konfiguration und jede Ausführungslogik, die nicht das Modell selbst ist – die Orchestrierungsschleife, Tools, Memory, Context Management, State, Error Handling, Guardrails und Verifikationsprüfungen, die gemeinsam darüber entscheiden, ob ein Agent erfolgreich ist oder scheitert. Wer ein LLM-Feature mit dem OpenAI- oder Anthropic-SDK ausgeliefert hat und beobachtet hat, wie es in Schleifen läuft, Tool-Calls halluziniert oder vergisst, was der Nutzer drei Turns zuvor gesagt hat, hat bereits die Grenzen eines dünnen Harness erreicht – und meistens war das Modell nicht das Problem.
Dieser Artikel liefert ein präzises mentales Modell für den Harness, Belege dafür, dass er mehr Ergebnisvarianz erzeugt als die Modellwahl, einen lauffähigen JS/TS-Harness, den man von Anfang bis Ende lesen kann, sowie vier Entscheidungen, die ein Frontend-Team beim Ausliefern eines produktinternen KI-Features tatsächlich selbst trifft.
Wichtigste Erkenntnisse
- Der Harness umfasst jeden Code-Abschnitt, jede Konfiguration und jede Ausführungslogik, die nicht das Modell selbst ist; LangChains Vivek Trivedy formuliert es so: „Wenn du nicht das Modell bist, bist du der Harness.”
- Das v0-Team von Vercel löschte 80 % der Tools seines Agents und beobachtete, wie die Task-Erfolgsrate von 80 % auf 100 % stieg und der durchschnittliche Token-Verbrauch um 37 % sank – ohne das Modell zu ändern.
- Auf dem CORE-Bench-Hard-Leaderboard von Princeton HAL erzielt Claude Opus 4.5 mit CORE-Agent 42,22 % und mit Claude Code 77,78 % – ein scaffold-bedingter Unterschied von 35,56 Prozentpunkten beim selben Modell.
- Die Debatte Harness vs. Modell ist nicht abgeschlossen: Scale AIs SWE-Atlas zeigt, dass Scaffold-Effekte je nach Modell variieren, während METR feststellte, dass Claude Code und Codex in einer Time-Horizon-Evaluation gegenüber den eigenen Standard-Scaffolds keine statistisch signifikante Verbesserung zeigten.
- Jeder Harness benötigt mindestens eine deterministische Prüfung – einen Test, einen Schema-Validator, einen regulären Ausdruck – bevor er eine Ausgabe an den Nutzer zurückgibt.
Was ist ein Agent-Harness?
Ein Agent-Harness ist das vollständige Softwaresystem, das einen LLM-Aufruf umhüllt: die Orchestrierungsschleife, die entscheidet, wann das Modell aufgerufen wird, die Tools, die das Modell aufrufen kann, der Memory- und Kontext-Inhalt, den es sieht, der State, den es zwischen Turns trägt, sowie die Guardrails und Verifikationsprüfungen, die seine Ausgabe kontrollieren. Die kanonische Formel stammt von LangChains Vivek Trivedy: „Wenn du nicht das Modell bist, bist du der Harness.” Das Modell produziert Tokens; der Harness ist alles, was diese Tokens in ein zuverlässiges Feature verwandelt.
Das klarste mentale Modell für diese Beziehung liefert Beren Millidge’s Essay von 2023, der scaffolded LLM-Systeme als Natural-Language-Computer beschreibt: Das LLM entspricht der CPU, Prompt und Kontextfenster entsprechen dem RAM (schnell, aber begrenzt), und externer Memory wie eine Vektordatenbank entspricht einem festplattenähnlichen Speicher. Tools fungieren als Gerätetreiber, die die Außenwelt erreichen, und der Harness ist das Betriebssystem, das alles koordiniert. Eine CPU ohne Betriebssystem berechnet nichts Nützliches. Das Modell ist notwendig, aber nicht hinreichend.
Die Terminologie in diesem Bereich ist weitläufig – daher eine klare Abgrenzung. Das Modell ist das LLM – Gewichte und eine API. Der Harness (manchmal auch Scaffold genannt) ist der umgebende Code. Der Agent ist das emergente Verhalten: eine zielorientierte, Tool-nutzende, selbstkorrigierende Einheit, mit der der Nutzer interagiert. Der Hugging Face Agents Course definiert einen Agenten als ein System, das ein KI-Modell nutzt, um mit seiner Umgebung zu interagieren und ein nutzerdefiniertes Ziel zu erreichen. Wenn jemand sagt „Ich habe einen Agenten gebaut”, hat er einen Harness gebaut und ihn auf ein Modell gerichtet. Anthropics eigene Ankündigung des Claude Agent SDK beschreibt das Claude Code SDK als „den Agent-Harness, der Claude Code antreibt.”
Warum ist der Wrapper wichtiger als das Modell?

Discover how at OpenReplay.com.
Der Wrapper ist wichtiger als das Modell, weil dasselbe Modell hinter einem anderen Harness grundlegend unterschiedliche Ergebnisse liefert – und diese Unterschiede sind groß, reproduzierbar und auf öffentlichen Benchmarks gemessen. Der stärkste Einzelbeleg: Das v0-Team von Vercel löschte 80 % der Tools seines Agents und beobachtete, wie die Task-Erfolgsrate von 80 % auf 100 % stieg, der durchschnittliche Token-Verbrauch um 37 % sank und eine Worst-Case-Anfrage von 724 Sekunden auf 141 Sekunden fiel – ohne das Modell zu ändern. Die Lösung lag vollständig im Harness: weniger, besser abgegrenzte Tools.
Zwei weitere Ergebnisse weisen in dieselbe Richtung. LangChain berichtete, seinen Coding-Agenten durch ausschließliche Änderung des Harness bei unverändertem Modell von außerhalb der Top 30 auf die Top 5 des Terminal-Bench 2.0 gehoben zu haben, wie aus dem eigenen Bericht hervorgeht. Und auf dem CORE-Bench-Hard-Leaderboard von Princeton HAL erzielt Claude Opus 4.5 mit dem CORE-Agent-Scaffold 42,22 % und mit Claude Code 77,78 % – ein Unterschied von 35,56 Prozentpunkten beim selben Modell, wobei das Leaderboard für den Claude-Code-Lauf auch 95,5 % unter manueller Validierung ausweist.
| Studie | Modell geändert? | Harness geändert? | Vorher | Nachher |
|---|---|---|---|---|
| Vercel v0 | Nein | Ja (−80 % Tools) | 80 % Erfolg | 100 % Erfolg, −37 % Tokens |
| LangChain / Terminal-Bench 2.0 | Nein | Ja | Außerhalb Top 30 | Top 5 |
| Princeton CORE-Bench Hard | Nein (Opus 4.5) | Ja (Scaffold) | 42,22 % | 77,78 % |
Die Debatte ist nicht abgeschlossen, und eine Vereinfachung schadet der Glaubwürdigkeit. Scale AIs SWE-Atlas vergleicht First-Party-Coding-Agent-Scaffolds mit dem minimalen Mini-SWE-Agent und zeigt, dass Scaffold-Effekte je nach Modell variieren, wobei native Scaffolds gegenüber der minimalen Baseline nennenswerte Verbesserungen erzielen. Gleichzeitig stellte METR fest, dass Claude Code und Codex in einer Time-Horizon-Evaluation gegenüber den eigenen Standard-Scaffolds keine statistisch signifikante Verbesserung zeigten. Beide Effekte sind real; welcher dominiert, hängt vom jeweiligen Aufgabenbereich ab. Die ehrliche Lesart, wie MongoDB es formuliert, lautet: „Das LLM ist der kleinste Teil” – aber Harness-Gewinne sind nicht unbegrenzt, und ein starkes Modell bei einer schwachen Aufgabe begrenzt dennoch, was Scaffolding ausgleichen kann.
Was sind die Komponenten eines LLM-Harness?
Ein produktionsreifer Harness lässt sich in acht Komponenten aufteilen, von denen jede eine potenzielle Schwachstelle eines dünnen Wrappers darstellt: Orchestrierungsschleife, Tools, Memory, Context Management, Prompt-Konstruktion, State, Error Handling sowie Guardrails mit Verifikationsschleifen.
Orchestrierungsschleife. Die Schleife implementiert den Thought–Action–Observation-Zyklus (das ReAct-Muster): das Modell aufrufen, prüfen, ob es ein Tool angefordert hat, das Tool ausführen, das Ergebnis zurückspeisen, wiederholen, bis das Modell antwortet oder ein Guard auslöst. Wie Vikash Rungtas Reverse-Engineering-Analyse von Claude Code es beschreibt, ist die Laufzeit eine „dumb loop”, bei der die gesamte Intelligenz im Modell liegt und der Harness lediglich Turns verwaltet. Technisch gesehen handelt es sich um eine while-Schleife mit einer Turn-Obergrenze.
Tools. Tools sind die Hände des Agents – Funktionen, die dem Modell als Schemas (Name, Beschreibung, Parametertypen) zugänglich gemacht werden. Die Tool-Schicht übernimmt Registrierung, Argumentvalidierung, Ausführung und die Formatierung von Ergebnissen zurück in modelllesbare Observations. Ein search_docs-Tool in einem Help-Widget ist ein Tool; ebenso get_order_status.
Memory. Kurzzeit-Memory ist die aktuelle Konversation; Langzeit-Memory persistiert über Sessions hinweg. In einem Chat-Widget ist Kurzzeit-Memory das Message-Array, das pro Turn wiedergegeben wird; Langzeit-Memory könnte eine nutzerspezifische Zusammenfassung sein, die beim Session-Start geladen wird.
Context Management. Die knappe Ressource ist das Kontextfenster, und das Fehlermuster ist Context Rot – die Qualität verschlechtert sich, wenn das Fenster mit rauscharmen Tokens gefüllt wird. Gemäß Anthropics Context-Engineering-Leitfaden ist das Ziel die kleinstmögliche Menge hochrelevanter Tokens. Strategien: Compaction (alte Turns zusammenfassen) und Just-in-Time-Retrieval (bei Bedarf abrufen statt vorab laden).
Prompt-Konstruktion. Der Harness assembliert den Input hierarchisch: System-Prompt, Tool-Definitionen, Memory, Konversationsverlauf, aktuelle Nachricht. Die Reihenfolge ist entscheidend; wichtiger Kontext gehört an den Anfang und das Ende des Fensters.
State. State ist das, was über Turns und Abstürze hinaus erhalten bleibt – die Position des Agents in einer mehrstufigen Aufgabe, Zwischenergebnisse, Checkpoints. Ein Chat-Widget, das die früher geäußerte Einschränkung des Nutzers „vergisst”, hat ein State- und Context-Management-Problem, kein Modellproblem.
Error Handling. Eine 10-stufige Aufgabe mit 99 % Erfolg pro Schritt hat nur ~90 % End-to-End-Erfolg, weil sich Fehler kumulieren. Das entscheidende Muster: einen Tool-Fehler als Observation an das Modell zurückgeben, damit es sich selbst korrigieren kann, anstatt eine Exception zu werfen und den Lauf abzubrechen.
Guardrails und Verifikationsschleifen. Guardrails schränken ein, was der Agent tun darf; Verifikationsschleifen prüfen, was er produziert hat. Martin Fowlers und Birgitta Böckelers Harness-Engineering-Writeup rahmt Verifikation als Guides (Feedforward – vor dem Handeln steuern) und Sensors (Feedback – beobachten und selbst korrigieren) ein, aufgeteilt in computational (deterministisch: Tests, Linter) und inferential (LLM-as-Judge) Controls.
Wie baue ich einen Agent-Harness in JavaScript?
Ein minimaler, aber vollständiger Harness ist eine ReAct-Schleife mit einer Turn-Obergrenze, einem gut abgegrenzten Tool, einem Error-as-Observation-Handler und einer deterministischen Verifikationsprüfung. Das folgende Beispiel verwendet das Anthropic SDK und Zod zur Schema-Validierung. Die Verifikationsprüfung ist der Teil, den die meisten dünnen Wrapper auslassen – ohne sie hat der Agent keine Möglichkeit zu erkennen, dass er falsch liegt.
import Anthropic from "@anthropic-ai/sdk";
import { z } from "zod";
const client = new Anthropic();
// One tool, narrowly scoped. Fewer tools = fewer spurious calls.
const tools: Anthropic.Tool[] = [
{
name: "get_order_status",
description: "Look up the status of an order by its numeric ID.",
input_schema: {
type: "object",
properties: { orderId: { type: "number" } },
required: ["orderId"],
},
},
];
// Deterministic verification: the model's tool input must match this schema.
const OrderArgs = z.object({ orderId: z.number().int().positive() });
async function runOrder(orderId: number) {
// Stand-in for a real lookup.
return { orderId, status: "shipped", eta: "2026-03-04" };
}
export async function harness(userMessage: string) {
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: userMessage },
];
// Max-turns guard: the single most important safety rail against looping.
for (let turn = 0; turn < 6; turn++) {
const res = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: "You are an order-status assistant. Use tools when asked about orders.",
tools,
messages,
});
const toolUse = res.content.find(
(b): b is Anthropic.ToolUseBlock => b.type === "tool_use"
);
if (!toolUse) return res.content; // No tool call → the model answered.
messages.push({ role: "assistant", content: res.content });
let observation: string;
const parsed = OrderArgs.safeParse(toolUse.input);
if (!parsed.success) {
// Verification failed: return the error AS an observation, don't throw.
observation = `Invalid arguments: ${parsed.error.message}`;
} else {
try {
observation = JSON.stringify(await runOrder(parsed.data.orderId));
} catch (e) {
observation = `Tool error: ${(e as Error).message}`; // also an observation
}
}
messages.push({
role: "user",
content: [{ type: "tool_result", tool_use_id: toolUse.id, content: observation }],
});
}
return [{ type: "text", text: "Could not complete the request." }];
}Vier Designentscheidungen in diesen ~50 Zeilen tragen den Großteil der Zuverlässigkeit. Die for-Schleife mit Turn-Obergrenze ist die Orchestrierungsschleife und gleichzeitig der Anti-Looping-Guard. Das einzelne Tool hält das Tool-Schema klein. Das Zod-safeParse ist die deterministische Verifikationsprüfung, die halluzinierte Argumente abfängt, bevor sie das Backend erreichen. Und sowohl Validierungsfehler als auch Laufzeitfehler werden als Observations zurückgegeben, nicht geworfen – damit das Modell sich selbst korrigieren kann, anstatt dass der Lauf abbricht. Anthropics Tool-Use-Mechanismen sind im Tool-Use-Leitfaden dokumentiert; die äquivalente Schleife mit dem OpenAI SDK verwendet tool_calls und role: "tool"-Nachrichten.
Warum besitzen Frontend-Entwickler mehr vom Harness, als sie denken?
Frontend-Entwickler besitzen bereits einen Harness, sobald sie ein KI-Chat-Widget, einen produktinternen Such-Assistenten oder eine Copilot-UI ausliefern – es sind lediglich dünnere Harnesses als die agentischen. Die meisten Fehler, über die Nutzer klagen (Schleifen, halluzinierte Tool-Calls, vergessener Kontext, ignorierte Einschränkungen), sind Harness-Fehler, keine Modellfehler. Wenn ein Frontend-Team ein KI-Feature ausliefert, ist die Modellwahl eine Entscheidung unter vielen, und die Harness-Entscheidungen – Tool-Scope, welcher Kontext mitgeführt wird, was verifiziert wird – erhalten in der Regel weniger Design-Review, als sie verdienen.
Die Zuordnung ist direkt. Ein Nutzer, der beobachtet, wie der Assistent dieselbe falsche Antwort „regeneriert”, sieht eine Orchestrierungsschleife ohne Verifikation. Ein Nutzer, dessen geäußerte Einschränkung zwei Turns später verschwunden ist, sieht eine State- und Context-Management-Lücke. Ein Tool-Call, der mit einem ungültigen Argument ausgelöst wird und eine verwirrende Antwort zurückgibt, ist eine fehlende Schema-Prüfung – genau der safeParse-Schritt von oben. Keines dieser Probleme wird durch den Austausch des Modells behoben. Sie werden behoben, indem der Wrapper, den man bereits besitzt, enger gefasst wird.
Wie dick sollte mein Harness sein? Vier Entscheidungen, die Frontend-Teams selbst treffen
Ein Frontend-Team, das ein produktinternes KI-Feature ausliefert, kontrolliert tatsächlich vier Harness-Entscheidungen: Tool-Scoping, Context-Strategie, Verifikationsschleifen und Harness-Dicke. Die breitere feldweite Liste – Single vs. Multi-Agent, ReAct vs. Plan-and-Execute, Berechtigungen, Durable Execution, Fleet Governance – liegt auf Infrastrukturebenen, die die meisten Chat-Widgets nie erreichen.
-
Tool-Scoping – mit weniger als 10 Tools beginnen und nur zögerlich erweitern. Einem Agenten mehr Tools zu geben als nötig, verschlechtert die Performance zuverlässig, weil jedes zusätzliche Tool-Schema Kontext verbraucht und die Wahrscheinlichkeit eines unbeabsichtigten Aufrufs erhöht. Vercels Ergebnis ist der tragende Beleg: Das Entfernen von 80 % der Tools verbesserte alles.
-
Context-Strategie – Compaction und Just-in-Time-Retrieval statt Window-Stuffing. Die gesamte Wissensbasis nicht vorab in den Prompt laden. Alte Turns zusammenfassen, wenn die Fenstergrenze naht, und Dokumente bei Bedarf abrufen. Anthropics Context-Engineering-Leitfaden definiert das Ziel als die kleinstmögliche hochrelevante Token-Menge.
-
Verifikationsschleifen – jeder Harness benötigt mindestens eine deterministische Prüfung, bevor er eine Ausgabe an den Nutzer zurückgibt. Ein Schema-Validator, ein regulärer Ausdruck, ein Unit-Test – irgendetwas, das der Harness ausführen kann, ohne auf das eigene Urteil des Modells angewiesen zu sein. Ohne diese Prüfung hat der Agent keine Möglichkeit zu erkennen, dass er falsch liegt. Gemäß Böckelers computational/inferential-Aufteilung sollte mit einer günstigen Computational-Prüfung begonnen werden; ein LLM-as-Judge wird nur hinzugefügt, wenn semantische Korrektheit es erfordert.
-
Harness-Dicke – dünn beginnen und Struktur nur hinzufügen, wenn ein Fehlermuster wiederholt auftritt. Keine Orchestrierung für Fehler vorbauen, die noch nicht aufgetreten sind. Einen Retry, einen Guardrail oder einen Verifikationsschritt hinzufügen, wenn ein spezifischer Fehler mehr als einmal auftritt.
Session-Replays eines KI-Features in der Produktion zu beobachten ist einer der schnellsten Wege, die Harness-Qualität am Nutzerverhalten abzulesen, da die diagnostischen Muster ohne jegliche modellseitige Telemetrie sichtbar sind. Wiederholtes Umformulieren derselben Anfrage signalisiert verlorenen Kontext oder eine Verifikationsschleife, die nie auslöst. Abbrüche mitten in einer mehrstufigen Aufgabe lassen sich oft auf einen verschluckten Tool-Fehler zurückführen, der als vage Antwort erscheint. Copy-then-Edit-Verhalten signalisiert eine Verifikationslücke – Ausgaben, die die Harness-Prüfungen bestanden haben, aber die Erwartungen des Nutzers verfehlen. Wiederholtes Klicken auf „Regenerieren” oder „Erneut versuchen” ist das charakteristische Muster einer loopenden Harness, die ihren eigenen Fehlerzustand nicht erkennen kann.
Wohin entwickelt sich das Harness-Design?
Modelle werden heute mit ihren Harnesses im Trainingsloop post-trainiert – wie LangChain in seiner Diskussion zur Agent-Harness-Architektur anmerkt, kombinieren Produkte wie Claude Code und Codex Modelltraining und Harness-Design in einem Feedback-Zyklus – was bedeutet, dass der Harness kein austauschbarer Wrapper mehr ist, sondern ein ko-evolvierter Teil der Produktoberfläche. Die Implikation für Entwickler ist, dass der Harness zu einem Teil des Produkts wird, das man gestaltet, und nicht zu einem generischen Adapter, den man unverändert von einem Modell auf ein anderes übertragen kann.
Das liefert einen klaren Zukunftssicherheitstest, abgeleitet aus der Scaffolding-Metapher: Wenn das Design mit einem stärkeren Modell sauber skaliert – gleicher Harness, bessere Ergebnisse – ist es solide. Wenn es mehr Scaffolding benötigt, um mit einem verbesserten Modell zu kompensieren, maskiert der Harness ein Modell- oder Aufgabenproblem, das anderswo behoben werden sollte. Scaffolding, wie das bauliche, soll abgebaut werden, sobald die Struktur für sich selbst steht.
Wenn das KI-Feature das nächste Mal in Schleifen läuft, vergisst oder etwas selbstsicher Falsches zurückgibt, sollte zunächst der Harness auditiert werden, bevor das Modell auditiert wird. Mit den vier oben genannten Entscheidungen beginnen – Tool-Scope, Context-Strategie, eine deterministische Prüfung und Dicke – und die kleinstmögliche Menge an Struktur hinzufügen, die dafür sorgt, dass der Fehler nicht mehr wiederkehrt.
FAQs
Was ist der Unterschied zwischen einem Harness und einem Scaffold?
Die Begriffe werden in der Praxis synonym verwendet; beide bezeichnen jeden Code-Abschnitt, jede Konfiguration und jede Ausführungslogik, die das Modell umgibt und nicht das Modell selbst ist. 'Scaffold' ist der gebräuchlichere Begriff in der Benchmark-Literatur, etwa beim Vergleich von Princetons CORE-Agent- und Claude-Code-Scaffold, während 'Harness' in Produktions- und SDK-Kontexten bevorzugt wird. LangChains Vivek Trivedy hebt die Unterscheidung mit der Regel auf: Wenn du nicht das Modell bist, bist du der Harness.
Sollte ich einen Tool-Fehler an das Modell zurückgeben oder ihn in meinem Harness werfen?
Den Fehler als Observation an das Modell zurückgeben, anstatt ihn zu werfen. Ein Throw beendet den Lauf; den Fehler als Tool-Result zurückzugeben ermöglicht es dem Modell zu sehen, was schiefgelaufen ist, und sich im nächsten Turn selbst zu korrigieren. Das ist wichtig, weil sich Fehler bei mehrstufigen Aufgaben kumulieren: Eine 10-stufige Aufgabe mit 99 % Erfolg pro Schritt fällt auf etwa 90 % End-to-End-Erfolg. Sowohl Schema-Validierungsfehler als auch Laufzeit-Exceptions sollten abgefangen und als Observations zurückgespeist werden – niemals als unbehandelte Throws.
Verbessert das Hinzufügen weiterer Tools die Agent-Performance?
Nein, das Hinzufügen weiterer Tools verschlechtert die Performance ab einem bestimmten Punkt zuverlässig. Jedes Tool-Schema verbraucht Kontextfenster-Tokens und erhöht die Wahrscheinlichkeit eines unbeabsichtigten oder falschen Tool-Calls. Das v0-Team von Vercel löschte 80 % der Tools seines Agents und beobachtete, wie die Task-Erfolgsrate von 80 % auf 100 % stieg und der durchschnittliche Token-Verbrauch um 37 % sank – beim selben Modell. Die praktische Regel lautet: mit weniger als 10 Tools beginnen und nur dann erweitern, wenn eine echte Lücke erkennbar wird.
Kann ich Modelle im selben Harness ohne Änderungen austauschen?
Zunehmend nicht mehr. Wie LangChain in seiner Diskussion zur Agent-Harness-Architektur anmerkt, kombinieren Produkte wie Claude Code und Codex Modelltraining und Harness-Design in einem Feedback-Zyklus. Das macht den Harness zu einem ko-evolvierten Teil der Produktoberfläche und nicht zu einem generischen Adapter. Ein nützlicher Zukunftssicherheitstest ist, ob das Design mit einem stärkeren Modell auf demselben Harness sauber skaliert; wenn es mehr Scaffolding benötigt, um mit einem verbesserten Modell zu kompensieren, maskiert der Harness ein tieferliegendes Problem.


