
Fundamentos del Diseño de Bases de Datos Relacionales

La mayoría de los problemas de bases de datos no son causados por consultas deficientes, sino por un esquema mal diseñado. Si tus tablas están mal estructuradas desde el inicio, ninguna cantidad de SQL ingenioso compensará completamente el problema. Este artículo cubre los principios fundamentales del diseño de bases de datos relacionales: cómo estructurar tablas, definir claves, modelar relaciones y usar restricciones para mantener tus datos confiables.
Puntos Clave
- Una base de datos relacional almacena datos en tablas vinculadas por claves, no duplicando información entre ellas
- Las claves primarias identifican de manera única las filas; las claves foráneas expresan relaciones entre tablas
- Las relaciones uno-a-muchos usan una clave foránea en el lado “muchos”, mientras que las relaciones muchos-a-muchos requieren una tabla de unión
- La normalización (1FN, 2FN, 3FN) reduce la redundancia y previene anomalías de datos, aunque la desnormalización deliberada a veces está justificada
- Las restricciones de base de datos (
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,CHECK) son tu última línea de defensa para la integridad de datos
Qué es Realmente una Base de Datos Relacional
Una base de datos relacional almacena datos en tablas — cuadrículas estructuradas de filas y columnas. Cada tabla representa un único tema o entidad, como users, orders o products. Cada fila es un registro. Cada columna es un atributo de ese registro.
El poder del modelo relacional proviene de vincular tablas entre sí en lugar de duplicar datos a través de ellas. El concepto se origina del modelo relacional propuesto por Edgar F. Codd en 1970, que aún forma la base teórica de las bases de datos SQL modernas.
Claves Primarias y Claves Foráneas: La Base de los Esquemas Relacionales
Cada tabla necesita una clave primaria — una columna (o combinación de columnas) que identifica de manera única cada fila. Una buena clave primaria es:
- Única en todas las filas
- Nunca nula
- Estable — no debería cambiar después de ser asignada
La mayoría de las bases de datos SQL modernas soportan columnas de identidad (enteros auto-incrementales) que generan identificadores únicos automáticamente. Muchos sistemas también soportan claves basadas en UUID, a menudo generadas mediante funciones integradas de la base de datos o valores predeterminados. Ambas son opciones válidas dependiendo de tu contexto. Los enteros auto-incrementales son simples y eficientes. Los UUID son más adecuados para sistemas distribuidos donde múltiples fuentes generan registros de forma independiente.
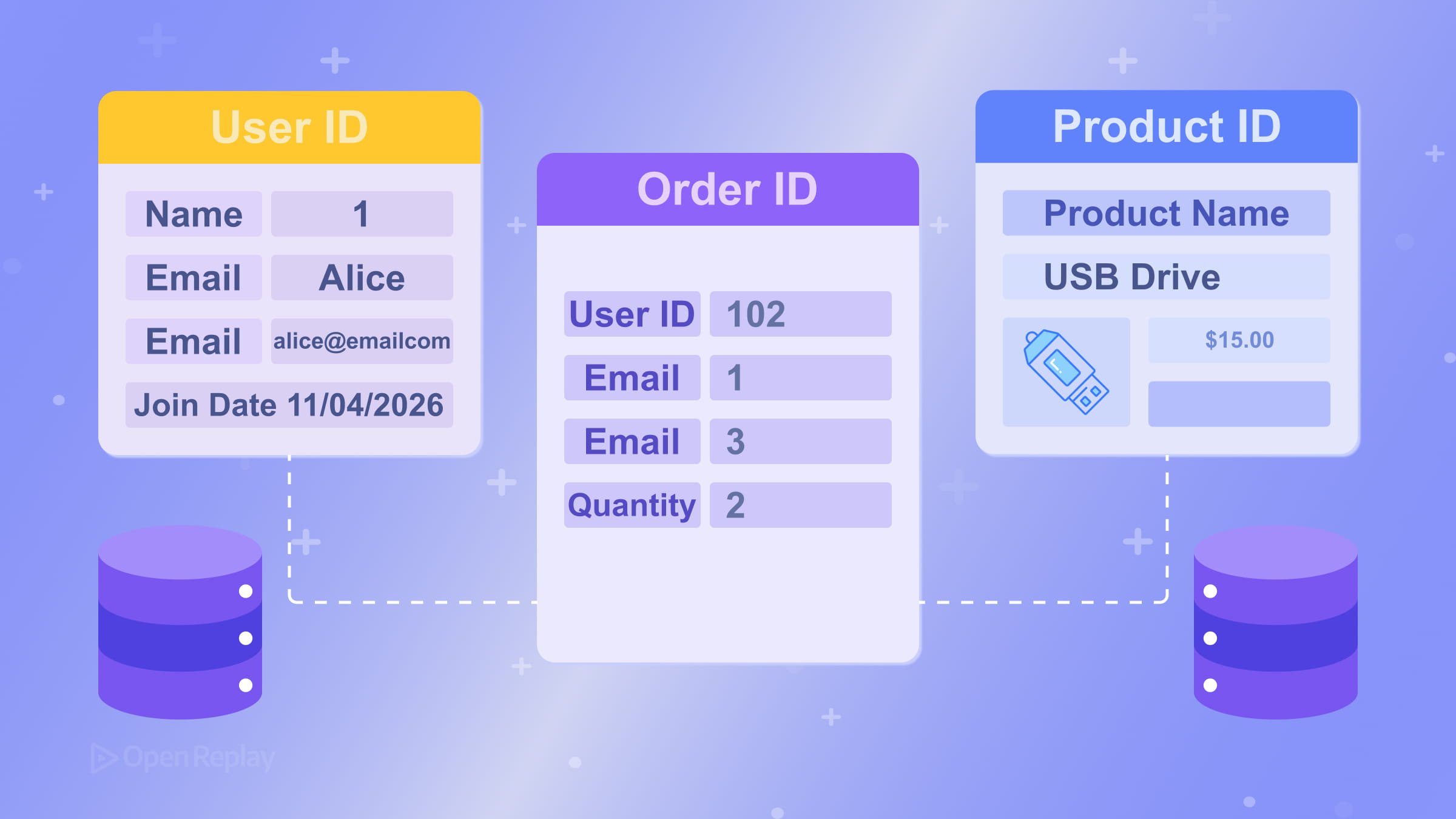
Una clave foránea es una columna en una tabla que referencia la clave primaria de otra. Así es como se expresan las relaciones entre tablas. Por ejemplo, una tabla orders podría tener una columna customer_id que referencia customers.id. La base de datos puede hacer cumplir este vínculo, previniendo registros huérfanos. Consulta la documentación de PostgreSQL sobre restricciones de claves foráneas para un ejemplo concreto.
Modelado de Relaciones: Uno-a-Muchos y Muchos-a-Muchos
La relación más común en el diseño de bases de datos relacionales es uno-a-muchos: un cliente tiene muchos pedidos, un autor tiene muchas publicaciones. Esto se modela colocando la clave foránea en el lado “muchos”.
Las relaciones muchos-a-muchos — como estudiantes inscribiéndose en cursos — requieren una tabla de unión (también llamada tabla asociativa o puente). En lugar de intentar almacenar múltiples valores en una sola columna, creas una tercera tabla (enrollments) con claves foráneas que apuntan tanto a students como a courses. Esto mantiene el esquema limpio y consultable.

Discover how at OpenReplay.com.
Normalización de Bases de Datos Explicada
La normalización de bases de datos es el proceso de estructurar tablas para reducir la redundancia y prevenir anomalías de datos. Las tres formas normales más prácticas son:
- 1FN (Primera Forma Normal): Cada celda contiene un valor — sin listas separadas por comas, sin grupos de columnas repetidas
- 2FN (Segunda Forma Normal): Cada columna no-clave depende de la clave primaria completa, no solo de parte de ella (esto aplica principalmente a tablas con claves primarias compuestas)
- 3FN (Tercera Forma Normal): Las columnas no-clave dependen solo de la clave primaria — no entre sí
La normalización es una guía, no una ley. Los esquemas altamente normalizados son más fáciles de mantener pero pueden requerir más joins. Algunos equipos desnormalizan intencionalmente tablas específicas para cargas de trabajo con mucha lectura. El equilibrio correcto depende de tus patrones de consulta y requisitos de rendimiento. Una descripción más detallada de la teoría detrás de la normalización de bases de datos está disponible en Wikipedia.
Aplicación de Integridad con Restricciones
La validación a nivel de aplicación por sí sola no es suficiente. Si múltiples servicios escriben en tu base de datos, o alguien ejecuta una consulta SQL directa, tus verificaciones a nivel de aplicación se omiten por completo. Las restricciones de base de datos son tu última línea de defensa:
PRIMARY KEY— impone unicidad y no-nulo en el identificadorFOREIGN KEY— asegura que las filas referenciadas realmente existanUNIQUE— previene valores duplicados en una columna (útil para correos electrónicos, nombres de usuario)NOT NULL— previene valores faltantes donde un campo es requeridoCHECK— valida que un valor cumpla una condición (ej.,price > 0)
La mayoría de las bases de datos SQL modernas también soportan columnas generadas — valores calculados automáticamente a partir de otras columnas — que pueden reducir la lógica redundante en tu capa de aplicación. Las implementaciones varían entre motores (PostgreSQL, MySQL, SQL Server cada uno maneja estos de manera diferente), pero el concepto está ampliamente disponible. Por ejemplo, PostgreSQL documenta las columnas generadas en su documentación oficial.
Un Ejemplo Práctico de Esquema
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);Este ejemplo usa sintaxis SQL estilo PostgreSQL. Impone integridad referencial, previene correos electrónicos nulos y valida que los totales de pedidos sean no negativos — todo a nivel de base de datos.
Ten en cuenta que GENERATED ALWAYS AS IDENTITY es SQL estándar (soportado en PostgreSQL 10+, Oracle 12c+ y DB2). Si estás usando MySQL, usarías AUTO_INCREMENT en su lugar. En SQL Server, el equivalente es IDENTITY(1,1). Consulta la documentación de PostgreSQL sobre columnas de identidad para más detalles.
Conclusión
El buen diseño de bases de datos relacionales se reduce a una idea: cada tabla debe representar una cosa, y cada pieza de datos debe vivir en exactamente un lugar. Aplica esto consistentemente, usa restricciones para hacer cumplir cómo deben verse los datos, y tu esquema se mantendrá mantenible a medida que tu aplicación crezca. Los principios cubiertos aquí — claves primarias y foráneas, normalización, modelado de relaciones y aplicación de restricciones — forman la base sobre la cual se construye cada base de datos confiable.
Preguntas Frecuentes
Usa UUID cuando los registros se generen en múltiples bases de datos o servicios que necesiten fusionarse sin colisiones de claves. Los enteros auto-incrementales son más simples, ocupan menos espacio de almacenamiento y son más rápidos para indexar. Para la mayoría de aplicaciones de una sola base de datos, los enteros funcionan bien. Elige UUID cuando necesites identificadores únicos globales en arquitecturas distribuidas o multi-tenant.
Comienza con la tercera forma normal (3FN) como tu línea base. Si cada columna no-clave depende únicamente de la clave primaria y no tienes datos repetidos entre filas, estás en buen camino. Si las consultas se vuelven demasiado lentas debido a joins excesivos, considera la desnormalización selectiva en tablas específicas con mucha lectura en lugar de abandonar completamente la normalización.
Sin restricciones de clave foránea, la base de datos no puede prevenir registros huérfanos. Podrías terminar con pedidos que referencian clientes que ya no existen, o filas de inscripción que apuntan a cursos eliminados. El código de aplicación puede pasar por alto casos límite, especialmente cuando múltiples servicios o consultas manuales modifican datos. Las claves foráneas detectan estos problemas a nivel de base de datos.
Sí, la desnormalización deliberada es una práctica común y válida para cargas de trabajo con mucha lectura. La clave es hacerlo intencionalmente y documentar los compromisos. Las tablas desnormalizadas son más rápidas de consultar pero más difíciles de mantener porque las actualizaciones deben propagarse a los datos duplicados. Úsalo selectivamente donde el rendimiento de consultas lo demande, no como una elección de diseño predeterminada.
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..
