
Cómo transmitir datos al navegador con Fetch

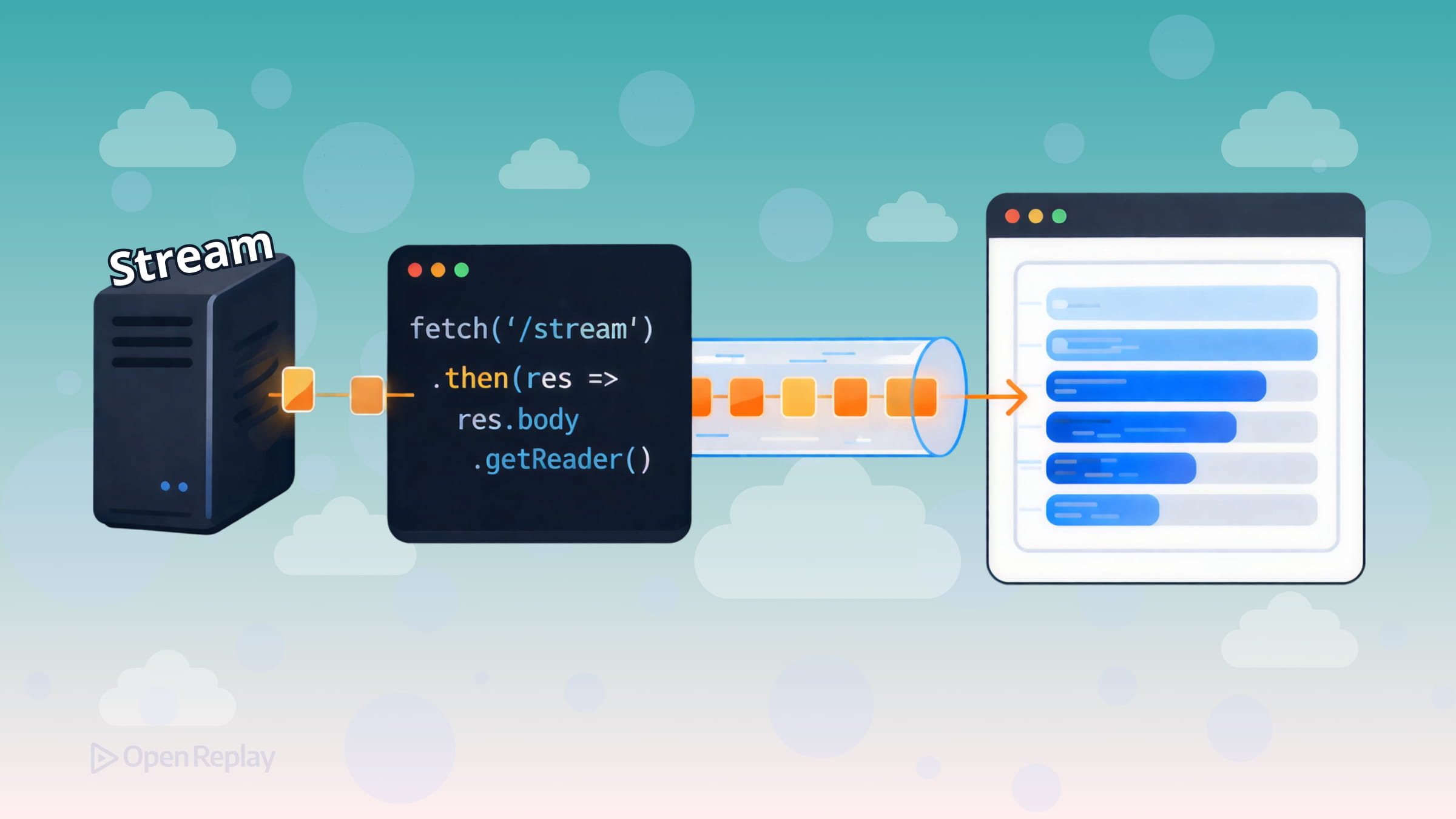
La mayoría de los tutoriales sobre la API Fetch muestran el mismo patrón: llamar a fetch(), esperar la respuesta, llamar a .json() o .text(), listo. Esto funciona bien para cargas útiles pequeñas. Pero cuando tu servidor está generando datos de forma progresiva—piensa en respuestas de IA, registros en vivo o conjuntos de datos grandes—esperar la respuesta completa antes de tocar un solo byte es un problema real.
La buena noticia: la API Fetch ya admite la transmisión incremental de datos en el navegador. Aquí te mostramos cómo usarla.
Puntos clave
- El
response.bodyde la API Fetch expone unReadableStream, lo que te permite procesar datos fragmento por fragmento a medida que llegan en lugar de esperar la carga útil completa. - Usa
response.body.getReader()con unTextDecoderpara obtener la mayor compatibilidad entre navegadores al leer respuestas transmitidas. - Los fragmentos de red no respetan los límites de los mensajes—debes almacenar en búfer y dividir las líneas incompletas tú mismo al analizar formatos estructurados como JSON delimitado por saltos de línea.
- Siempre empareja las transmisiones de larga duración con un
AbortControllerpara poder cancelar las solicitudes de forma limpia cuando los usuarios naveguen fuera de la página.
Por qué importa la transmisión de respuestas con la API Fetch
Cuando llamas a response.json() o response.text(), el navegador debe recibir todo el cuerpo de la respuesta antes de resolver la promesa. Para un archivo de registro de 50MB o un endpoint de completado de IA lento, eso significa que tu aplicación no puede procesar ni renderizar ninguna parte de la respuesta hasta que llegue el último byte.
La transmisión te permite procesar datos a medida que llegan—mostrando el primer fragmento a los usuarios mientras el resto aún está en tránsito. Eso es una mejora significativa en el rendimiento percibido.
Cómo funciona el ReadableStream de la API Fetch
Cada respuesta de fetch() expone un ReadableStream en response.body. En lugar de esperar la carga útil completa, adjuntas un lector y extraes fragmentos a medida que llegan de la red.
El enfoque más ampliamente compatible es response.body.getReader():
const response = await fetch('/api/stream')
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`)
}
const reader = response.body.getReader()
const decoder = new TextDecoder()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(decoder.decode(value, { stream: true }))
}Cada value es un Uint8Array de bytes sin procesar. TextDecoder convierte esos bytes en una cadena. Pasa { stream: true } para que el decodificador maneje correctamente los caracteres multibyte que podrían estar divididos entre los límites de los fragmentos.
Nota sobre la iteración asíncrona: Es posible que hayas visto
for await (const chunk of response.body). Esta sintaxis es más limpia pero no es compatible con Safari a partir de la versión 18.x, por lo que el buclegetReader()anterior es la opción más segura para producción. Consulta la compatibilidad actual de los navegadores en https://caniuse.com/wf-async-iterable-streams.
Decodificación de flujos de texto con TextDecoderStream
Si prefieres un enfoque estilo pipeline, TextDecoderStream maneja la decodificación automáticamente:
const response = await fetch('/api/stream')
const reader = response.body
.pipeThrough(new TextDecoderStream())
.getReader()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(value) // ya es una cadena
}Esto es más limpio cuando se encadenan múltiples pasos de transformación.

Discover how at OpenReplay.com.
Consideraciones prácticas para la transmisión en el navegador con Fetch
Los límites de los fragmentos son arbitrarios. Los fragmentos de red no se alinean con líneas o mensajes. Si estás analizando JSON delimitado por saltos de línea o eventos SSE, necesitas almacenar en búfer las líneas incompletas y dividir en \n tú mismo.
Los flujos solo se pueden consumir una vez. Adjuntar un lector con getReader() bloquea el flujo a ese lector, y una vez que se ha leído cualquier dato, el cuerpo queda alterado y no se puede consumir nuevamente. Si necesitas el cuerpo en dos lugares, llama a response.clone() antes de leer:
const response = await fetch('/api/data')
const clone = response.clone()
// Lee el original como un flujo
const reader = response.body.getReader()
// Usa el clon normalmente en otro lugar
const text = await clone.text()Cancela flujos con AbortController. Los flujos de larga duración deben ser cancelables—especialmente cuando los usuarios naveguen fuera de la página:
const controller = new AbortController()
const response = await fetch('/api/stream', {
signal: controller.signal
})
// Cancelar cuando sea necesario
controller.abort()Esto evita que el navegador continúe recibiendo datos que nadie está leyendo.
Conclusión
La transmisión en el navegador con Fetch está bien soportada y es práctica hoy en día. El patrón principal es sencillo: obtén un lector de response.body, itera con reader.read(), decodifica bytes con TextDecoder y maneja los límites de los fragmentos en tu propio búfer. Agrega un AbortController para la limpieza, y ten en cuenta que los cuerpos de respuesta solo se pueden consumir una vez cuando necesites los datos en múltiples lugares. Eso es todo lo que necesitas para construir experiencias de datos incrementales y receptivas en el navegador.
Preguntas frecuentes
La transmisión con Fetch funciona con cualquier método HTTP que devuelva un cuerpo de respuesta, incluyendo POST, PUT y PATCH. El ReadableStream en response.body se comporta de manera idéntica independientemente del método utilizado. El servidor solo necesita enviar una respuesta fragmentada o en streaming para que la lectura incremental sea significativa.
Necesitas mantener un búfer de cadena. Agrega cada fragmento decodificado al búfer, luego divide por caracteres de salto de línea. Procesa cada línea completa como JSON y mantén el segmento incompleto final en el búfer para el siguiente fragmento. Esto tiene en cuenta el hecho de que los fragmentos de red pueden dividir un objeto JSON en dos lecturas.
Sí. Puedes consumir un endpoint SSE a través de la transmisión con Fetch analizando manualmente el formato text/event-stream de los fragmentos. Esto te da más control sobre los encabezados, la autenticación y los métodos de solicitud en comparación con la API EventSource, que solo admite solicitudes GET y ofrece personalización limitada de encabezados.
Si la conexión se interrumpe o el flujo genera un error, la promesa devuelta por reader.read() será rechazada. Envuelve tu bucle de lectura en un bloque try-catch para que tu aplicación pueda manejar el fallo de manera elegante, notificar al usuario o reintentar la solicitud si es apropiado.
Complete picture for complete understanding
Capture every clue your frontend is leaving so you can instantly get to the root cause of any issue with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data.
Check our GitHub repo and join the thousands of developers in our community.
