
À l'intérieur de l'AST : Comment les outils comprennent le code

Chaque fois qu’ESLint signale un problème avant même que vous n’exécutiez votre code, ou que Prettier reformate une fonction désordonnée au moment où vous enregistrez, quelque chose de précis se produit en coulisses. Ces outils ne lisent pas votre code source comme du texte. Ils le lisent comme un arbre structuré. Comprendre cet arbre — l’Arbre de Syntaxe Abstraite (AST) — explique comment fonctionne pratiquement chaque outil moderne de développement.
Points clés à retenir
- Un AST est une représentation arborescente de la structure de votre code, souvent dépouillée des détails superficiels comme les espaces blancs et les parenthèses de regroupement.
- Les linters, formateurs et compilateurs fonctionnent tous en analysant le code source pour produire un AST, en le parcourant et en appliquant des règles ou des transformations à chaque nœud.
- Le patron visiteur est l’approche dominante : les outils enregistrent des gestionnaires pour des types de nœuds spécifiques et réagissent lors du parcours de l’arbre.
- Un Arbre de Syntaxe Concret (CST) conserve chaque token, ce qui le rend mieux adapté aux éditeurs nécessitant une analyse incrémentale et des représentations haute-fidélité.
- Les outils basés sur Rust comme Biome et Oxc utilisent le même modèle analyser-parcourir-agir, mais poussent les performances bien au-delà de ce que de nombreux parseurs basés sur JavaScript peuvent atteindre.
Qu’est-ce qu’un Arbre de Syntaxe Abstraite ?
Lorsqu’un outil analyse votre code source, il passe par deux étapes.
D’abord, un lexer (ou tokenizer) décompose le texte brut en tokens : mots-clés, identifiants, opérateurs, ponctuation. Ensuite, un parser prend ces tokens et construit un arbre qui représente la structure grammaticale de votre code.
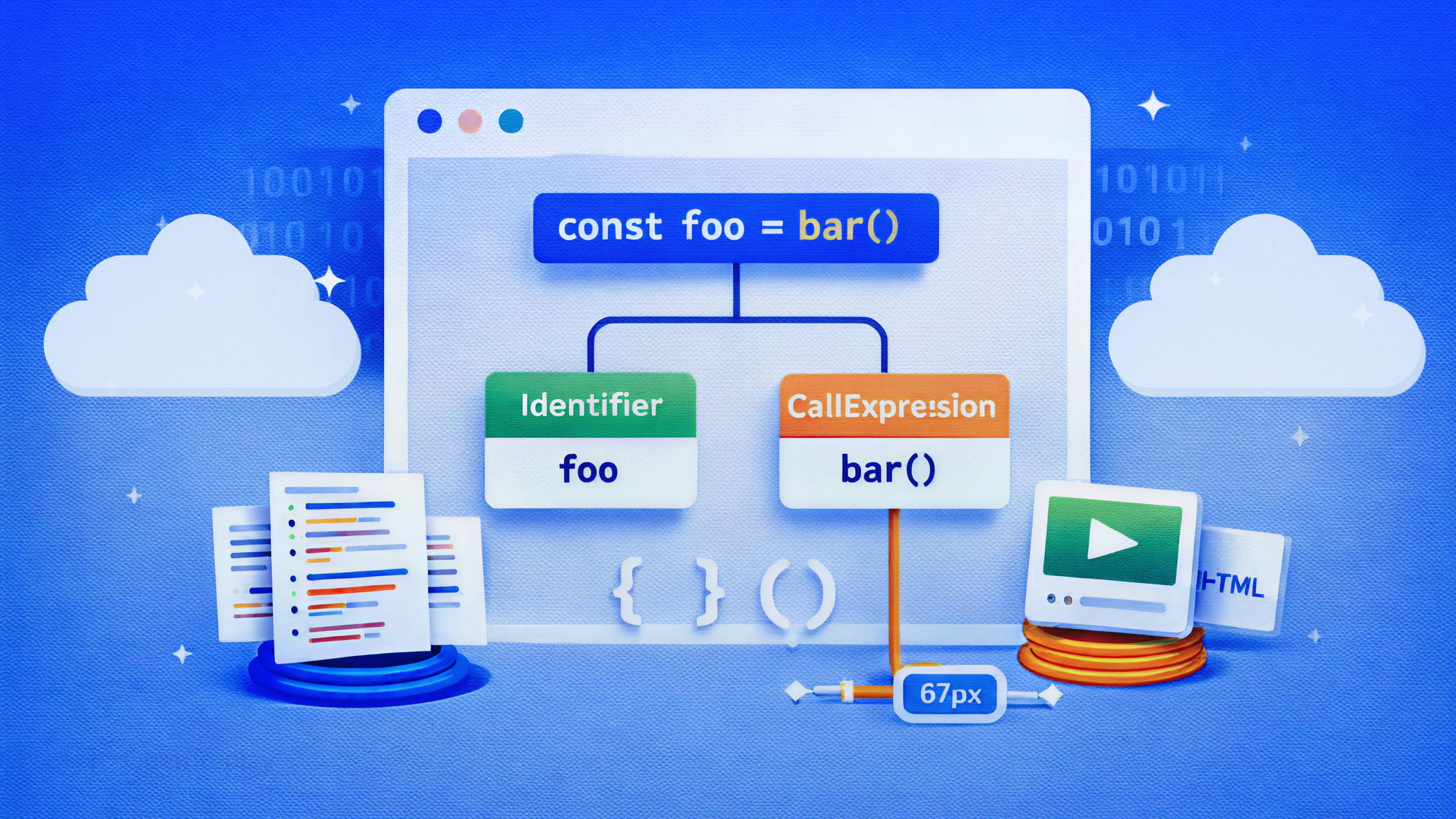
Cet arbre est l’AST. Il est qualifié d’« abstrait » car il omet souvent les détails superficiels — espaces blancs, la plupart de la ponctuation et les parenthèses utilisées uniquement pour le regroupement — tout en conservant ce qui est sémantiquement significatif.
Prenons cette ligne :
const x = 5 + 3Un parser produit quelque chose comme ceci :
{
"type": "VariableDeclaration",
"kind": "const",
"declarations": [{
"type": "VariableDeclarator",
"id": { "type": "Identifier", "name": "x" },
"init": {
"type": "BinaryExpression",
"operator": "+",
"left": { "type": "Literal", "value": 5 },
"right": { "type": "Literal", "value": 3 }
}
}]
}Chaque nœud possède un type. Les nœuds enfants sont imbriqués dans les nœuds parents. L’ensemble du programme devient un arbre enraciné dans un nœud Program.
Vous pouvez explorer cela directement en utilisant AST Explorer, qui vous permet de coller n’importe quel code JavaScript ou TypeScript et d’inspecter l’arbre résultant en temps réel.
Comment les linters et formateurs utilisent les AST
Une fois qu’un outil dispose de l’AST, il peut faire quelque chose d’utile : le parcourir.
La plupart des outils utilisent le patron visiteur. Vous enregistrez une fonction pour un type de nœud spécifique, et le moteur de parcours appelle cette fonction chaque fois qu’il rencontre un nœud correspondant.
ESLint fonctionne exactement de cette manière. Chaque règle de lint est un objet visiteur. Lorsqu’ESLint parcourt l’AST, il appelle les gestionnaires de règles pertinents à chaque nœud. Une règle qui interdit == en faveur de === écoute simplement les nœuds BinaryExpression et vérifie la propriété operator.
Babel utilise la même approche pour la transformation de code. Il analyse le source en AST, applique des transformations basées sur des visiteurs qui modifient les nœuds, puis imprime l’arbre modifié pour restituer le code source. C’est ainsi qu’il compile la syntaxe JavaScript moderne en équivalents plus anciens.
Prettier adopte un angle différent. Il analyse le code en AST, supprime tout le formatage original et réimprime l’arbre selon ses propres règles de mise en page. L’AST est la source de vérité — pas le texte original.

Discover how at OpenReplay.com.
AST vs CST : Quand la structure compte davantage
Un AST omet les tokens qui sont syntaxiquement requis mais sémantiquement redondants. Un Arbre de Syntaxe Concret (CST) conserve la structure syntaxique complète du code source, en préservant les tokens et leurs positions.
Tree-sitter produit un arbre de syntaxe concret optimisé pour l’analyse incrémentale. Parce qu’il peut mettre à jour uniquement la portion de l’arbre affectée par une modification, il est bien adapté à la coloration syntaxique, au pliage de code et à l’édition structurelle dans les éditeurs modernes comme Neovim et Zed.
Le passage vers une analyse haute performance
Les nouveaux outils de l’écosystème JavaScript poussent les performances d’analyse beaucoup plus loin. Des projets comme Biome et Oxc sont implémentés en Rust et construisent leurs propres parseurs et représentations AST à partir de zéro.
Ils gèrent le linting et le formatage à des vitesses qui surpassent souvent les parseurs basés sur JavaScript, tout en prenant en charge la syntaxe moderne comme les attributs d’import et les fonctionnalités récentes de TypeScript.
Le modèle sous-jacent est le même — analyser vers un arbre, le parcourir, appliquer une analyse ou une transformation — mais l’implémentation est optimisée pour l’échelle.
Conclusion
Que vous écriviez une règle ESLint personnalisée, construisiez un codemod avec jscodeshift, ou essayiez simplement de comprendre pourquoi un outil se comporte comme il le fait, l’AST est le bon endroit où regarder. C’est la représentation structurée sur laquelle repose chaque outil de développement sérieux. Une fois que vous savez lire un arbre de syntaxe, le comportement des linters, formateurs et compilateurs cesse de ressembler à de la magie.
FAQ
Pas pour une utilisation quotidienne. Ces outils fonctionnent directement avec des paramètres par défaut sensés. Mais si vous voulez écrire des règles de lint personnalisées, construire des codemods ou déboguer un comportement d'outil inattendu, comprendre comment les AST représentent votre code vous donne un modèle mental clair de ce que l'outil fait réellement à chaque étape.
Un AST supprime les tokens syntaxiquement requis mais sémantiquement redondants comme les virgules, les crochets et les espaces blancs. Un CST conserve la structure syntaxique complète du code source. Les CST sont préférés dans les éditeurs et IDE où la représentation haute-fidélité et l'analyse incrémentale sont importantes, tandis que les AST sont généralement utilisés par les linters, compilateurs et formateurs.
Le moyen le plus simple est AST Explorer sur astexplorer.net. Collez n'importe quel extrait JavaScript ou TypeScript, choisissez un parser comme acorn, babel ou typescript, et l'outil affiche l'arbre complet en temps réel. Il prend également en charge d'autres langages et vous permet d'expérimenter avec des transformations directement dans le navigateur.
Rust donne à ces outils un contrôle direct sur l'allocation et la disposition de la mémoire, évite les pauses de garbage collection et compile vers du code natif hautement optimisé. Cela signifie que l'analyse, le parcours et l'analyse s'exécutent tous beaucoup plus rapidement, ce qui devient particulièrement perceptible dans les grandes bases de code avec des milliers de fichiers.
Understand every bug
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
