
Les bases de la conception de bases de données relationnelles

La plupart des problèmes de bases de données ne sont pas causés par de mauvaises requêtes — ils sont causés par un mauvais schéma. Si vos tables sont mal structurées dès le départ, aucune quantité de SQL astucieux ne compensera pleinement. Cet article couvre les principes fondamentaux de la conception de bases de données relationnelles : comment structurer les tables, définir les clés, modéliser les relations et utiliser les contraintes pour maintenir la fiabilité de vos données.
Points clés à retenir
- Une base de données relationnelle stocke les données dans des tables liées par des clés, et non en dupliquant les informations entre elles
- Les clés primaires identifient de manière unique les lignes ; les clés étrangères expriment les relations entre les tables
- Les relations un-à-plusieurs utilisent une clé étrangère du côté « plusieurs », tandis que les relations plusieurs-à-plusieurs nécessitent une table de jonction
- La normalisation (1NF, 2NF, 3NF) réduit la redondance et prévient les anomalies de données, bien qu’une dénormalisation délibérée soit parfois justifiée
- Les contraintes de base de données (
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,CHECK) constituent votre dernière ligne de défense pour l’intégrité des données
Ce qu’est réellement une base de données relationnelle
Une base de données relationnelle stocke les données dans des tables — des grilles structurées de lignes et de colonnes. Chaque table représente un sujet ou une entité unique, comme users, orders ou products. Chaque ligne est un enregistrement. Chaque colonne est un attribut de cet enregistrement.
La puissance du modèle relationnel provient de la liaison des tables entre elles plutôt que de la duplication des données. Le concept provient du modèle relationnel proposé par Edgar F. Codd en 1970, qui constitue encore aujourd’hui le fondement théorique des bases de données SQL modernes.
Clés primaires et clés étrangères : le fondement des schémas relationnels
Chaque table a besoin d’une clé primaire — une colonne (ou une combinaison de colonnes) qui identifie de manière unique chaque ligne. Une bonne clé primaire est :
- Unique pour toutes les lignes
- Jamais nulle
- Stable — elle ne devrait pas changer après avoir été attribuée
La plupart des bases de données SQL modernes prennent en charge les colonnes d’identité (entiers auto-incrémentés) qui génèrent automatiquement des identifiants uniques. De nombreux systèmes prennent également en charge les clés basées sur UUID, souvent générées via des fonctions ou des valeurs par défaut intégrées à la base de données. Les deux sont des choix valables selon votre contexte. Les entiers auto-incrémentés sont simples et efficaces. Les UUID sont mieux adaptés aux systèmes distribués où plusieurs sources génèrent des enregistrements de manière indépendante.
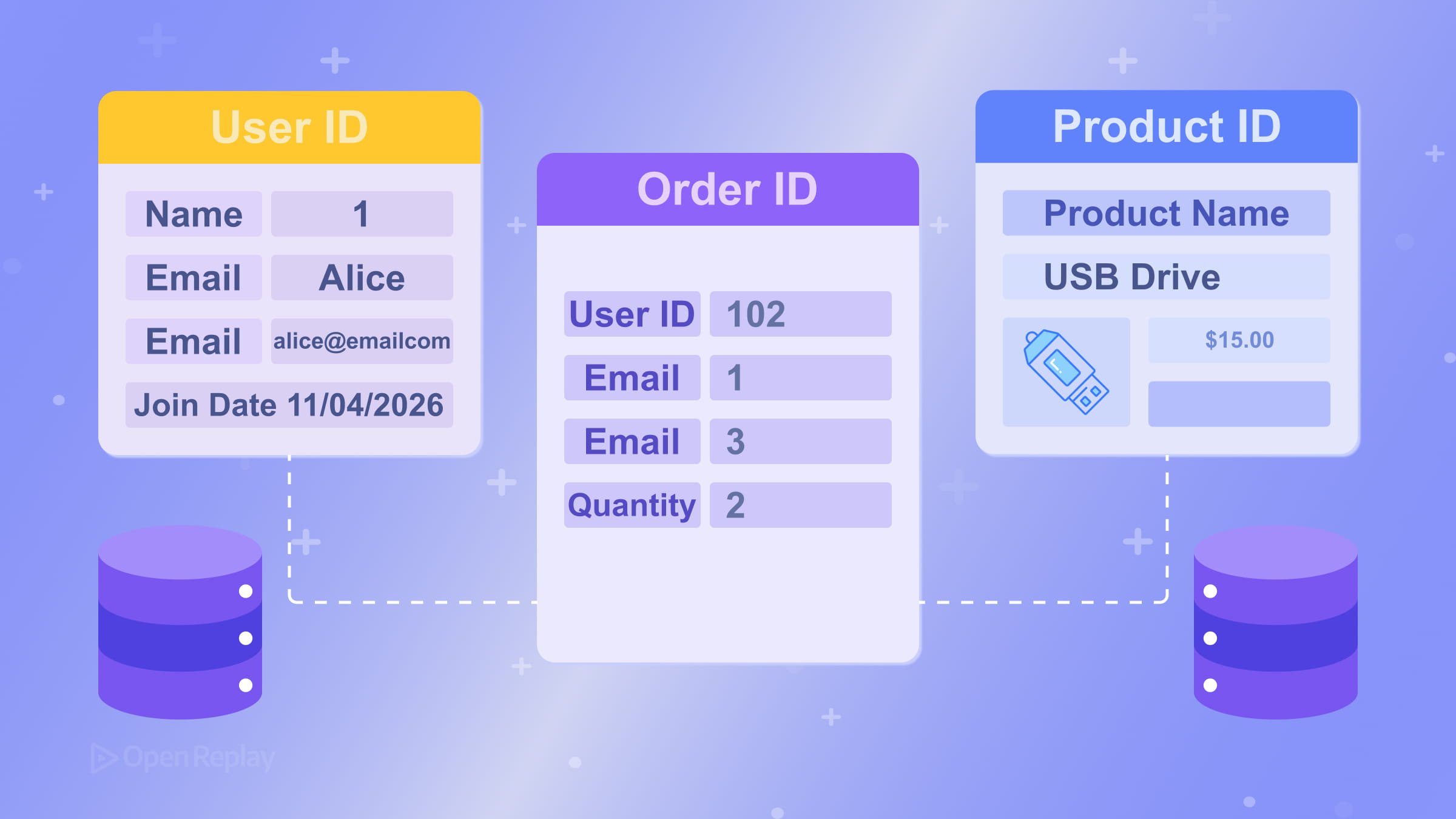
Une clé étrangère est une colonne dans une table qui référence la clé primaire d’une autre table. C’est ainsi que les relations entre les tables sont exprimées. Par exemple, une table orders peut avoir une colonne customer_id qui référence customers.id. La base de données peut imposer ce lien, empêchant ainsi les enregistrements orphelins. Consultez la documentation PostgreSQL sur les contraintes de clés étrangères pour un exemple concret.
Modélisation des relations : un-à-plusieurs et plusieurs-à-plusieurs
La relation la plus courante dans la conception de bases de données relationnelles est un-à-plusieurs : un client a plusieurs commandes, un auteur a plusieurs articles. Vous modélisez cela en plaçant la clé étrangère du côté « plusieurs ».
Les relations plusieurs-à-plusieurs — comme les étudiants s’inscrivant à des cours — nécessitent une table de jonction (également appelée table associative ou table de liaison). Au lieu d’essayer de stocker plusieurs valeurs dans une seule colonne, vous créez une troisième table (enrollments) avec des clés étrangères pointant à la fois vers students et courses. Cela maintient le schéma propre et interrogeable.

Discover how at OpenReplay.com.
La normalisation de bases de données expliquée
La normalisation de bases de données est le processus de structuration des tables pour réduire la redondance et prévenir les anomalies de données. Les trois formes normales les plus pratiques sont :
- 1NF (Première forme normale) : chaque cellule contient une seule valeur — pas de listes séparées par des virgules, pas de groupes de colonnes répétitifs
- 2NF (Deuxième forme normale) : chaque colonne non-clé dépend de la clé primaire entière, et non d’une partie seulement (cela s’applique principalement aux tables avec des clés primaires composites)
- 3NF (Troisième forme normale) : les colonnes non-clés dépendent uniquement de la clé primaire — pas les unes des autres
La normalisation est une ligne directrice, pas une loi. Les schémas fortement normalisés sont plus faciles à maintenir mais peuvent nécessiter davantage de jointures. Certaines équipes dénormalisent intentionnellement des tables spécifiques pour les charges de travail à forte lecture. Le bon équilibre dépend de vos modèles de requêtes et de vos exigences de performance. Un aperçu plus détaillé de la théorie derrière la normalisation de bases de données est disponible sur Wikipedia.
Application de l’intégrité avec les contraintes
La validation au niveau de l’application seule ne suffit pas. Si plusieurs services écrivent dans votre base de données, ou si quelqu’un exécute une requête SQL directe, vos vérifications côté application sont entièrement contournées. Les contraintes de base de données constituent votre dernière ligne de défense :
PRIMARY KEY— impose l’unicité et la non-nullité sur l’identifiantFOREIGN KEY— garantit que les lignes référencées existent réellementUNIQUE— empêche les valeurs en double dans une colonne (utile pour les emails, les noms d’utilisateur)NOT NULL— empêche les valeurs manquantes lorsqu’un champ est requisCHECK— valide qu’une valeur respecte une condition (par exemple,price > 0)
La plupart des bases de données SQL modernes prennent également en charge les colonnes générées — des valeurs calculées automatiquement à partir d’autres colonnes — ce qui peut réduire la logique redondante dans votre couche applicative. Les implémentations varient selon les moteurs (PostgreSQL, MySQL, SQL Server gèrent chacun cela différemment), mais le concept est largement disponible. Par exemple, PostgreSQL documente les colonnes générées dans sa documentation officielle.
Un exemple de schéma pratique
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);Cet exemple utilise la syntaxe SQL de style PostgreSQL. Il impose l’intégrité référentielle, empêche les emails nuls et valide que les totaux des commandes sont non négatifs — tout cela au niveau de la base de données.
Notez que GENERATED ALWAYS AS IDENTITY est du SQL standard (pris en charge dans PostgreSQL 10+, Oracle 12c+ et DB2). Si vous utilisez MySQL, vous utiliseriez AUTO_INCREMENT à la place. Dans SQL Server, l’équivalent est IDENTITY(1,1). Consultez la documentation PostgreSQL sur les colonnes d’identité pour plus de détails.
Conclusion
Une bonne conception de base de données relationnelle se résume à une idée : chaque table doit représenter une seule chose, et chaque élément de données doit résider à un seul endroit. Appliquez cela de manière cohérente, utilisez des contraintes pour imposer ce à quoi les données doivent ressembler, et votre schéma restera maintenable à mesure que votre application se développe. Les principes abordés ici — clés primaires et étrangères, normalisation, modélisation des relations et application des contraintes — constituent le fondement sur lequel repose toute base de données fiable.
FAQ
Utilisez des UUID lorsque les enregistrements sont générés dans plusieurs bases de données ou services qui doivent fusionner sans collisions de clés. Les entiers auto-incrémentés sont plus simples, plus petits en termes de stockage et plus rapides pour l'indexation. Pour la plupart des applications à base de données unique, les entiers fonctionnent bien. Choisissez les UUID lorsque vous avez besoin d'identifiants globalement uniques dans des architectures distribuées ou multi-locataires.
Commencez par la troisième forme normale (3NF) comme référence. Si chaque colonne non-clé dépend uniquement de la clé primaire et que vous n'avez pas de données répétées entre les lignes, vous êtes en bonne voie. Si les requêtes deviennent trop lentes en raison de jointures excessives, envisagez une dénormalisation sélective sur des tables spécifiques à forte lecture plutôt que d'abandonner complètement la normalisation.
Sans contraintes de clés étrangères, la base de données ne peut pas empêcher les enregistrements orphelins. Vous pourriez vous retrouver avec des commandes référençant des clients qui n'existent plus, ou des lignes d'inscription pointant vers des cours supprimés. Le code applicatif peut manquer des cas limites, en particulier lorsque plusieurs services ou requêtes manuelles modifient les données. Les clés étrangères détectent ces problèmes au niveau de la base de données.
Oui, la dénormalisation délibérée est une pratique courante et valable pour les charges de travail à forte lecture. La clé est de le faire intentionnellement et de documenter les compromis. Les tables dénormalisées sont plus rapides à interroger mais plus difficiles à maintenir car les mises à jour doivent se propager aux données dupliquées. Utilisez-la de manière sélective là où les performances des requêtes l'exigent, et non comme choix de conception par défaut.
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..
