Autorisation côté client vs côté serveur : pourquoi les deux sont indispensables
Autorisation côté client vs côté serveur dans React et Next.js : imposez les permissions côté serveur, gardez le client pour l UX et évitez les 403.

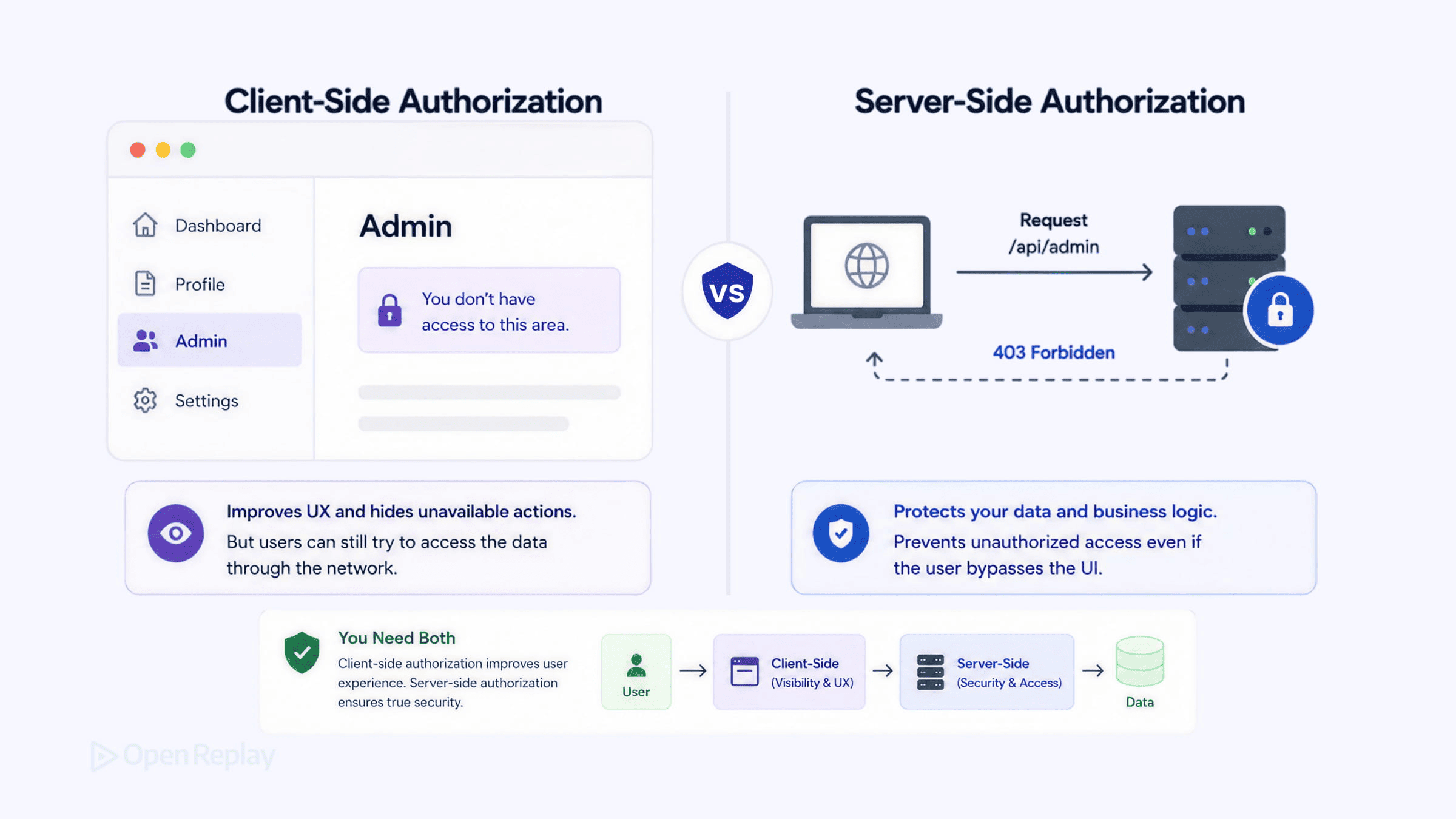
L’autorisation côté client est la logique d’accès qui s’exécute dans le navigateur et détermine ce que les utilisateurs voient ; l’autorisation côté serveur est la logique d’accès qui s’exécute sur le serveur et décide de ce qui se passe réellement — et aucun contrôle d’interface ne modifie ce que le serveur acceptera. Ce sont deux responsabilités distinctes à deux frontières de confiance différentes, et négliger l’une ou l’autre entraîne une défaillance spécifique et prévisible : les contrôles uniquement côté client peuvent être contournés par quiconque ouvre les DevTools, et les contrôles uniquement côté serveur laissent les utilisateurs cliquer sur des boutons qui renvoient des erreurs 403 sans qu’ils comprennent pourquoi.
Si vous avez déployé une application React ou Next.js dans laquelle les vérifications de rôle se trouvent dans des blocs if (user.role === 'admin'), vous avez déjà écrit de l’autorisation côté client — vous n’êtes peut-être simplement pas sûr de l’emplacement de la véritable frontière de sécurité. Cet article trace cette frontière avec précision : pourquoi le client n’est pas fiable, pourquoi le serveur est le seul gardien qui compte, à quoi servent légitimement les contrôles côté client, et comment maintenir la cohérence des deux couches à l’aide d’un identifiant de permission unique appliqué des deux côtés.
Points clés à retenir
- Le client est un environnement non fiable : n’importe quel utilisateur peut ouvrir les DevTools, modifier la variable contenant son rôle et observer les rendus conditionnels réagir en conséquence — les décisions d’autorisation doivent donc être appliquées côté serveur, au niveau d’une passerelle ou dans une fonction serverless (OWASP Authorization Cheat Sheet).
- L’autorisation côté client existe pour l’expérience utilisateur, pas pour la sécurité : elle masque les boutons, protège les routes et n’affiche que les éléments de menu pertinents, afin que les utilisateurs n’arrivent jamais dans une impasse.
- L’état des permissions côté frontend est un cache de ce que le serveur autorisera ; lorsque les deux divergent, vous obtenez soit un workflow exploitable (l’interface affiche un bouton que le serveur rejette avec un 403), soit une fonctionnalité cachée (le serveur autorise une action que l’interface ne présente jamais).
- Utilisez des identifiants de permission comme
tasks:deletedans les deux couches, plutôt que des comparaisons de noms de rôle commerole === 'admin'— les noms de permission survivent aux restructurations de rôles et correspondent à l’unité que le serveur applique réellement. - Un 401 signifie non authentifié et doit rediriger vers la page de connexion ; un 403 signifie authentifié mais non autorisé et doit afficher un état de refus de permission (RFC 9110 §15.5.2, §15.5.4).
Le client est un environnement non fiable
Chaque vérification de rôle dans votre JavaScript s’exécute dans un environnement que l’utilisateur contrôle : il peut ouvrir les DevTools, trouver la variable contenant son rôle, la définir sur 'admin' et observer les rendus conditionnels réagir — seule la réponse du serveur à sa prochaine requête ne change pas. C’est le fait fondamental qui rend l’autorisation côté client insuffisante à elle seule. Le navigateur exécute votre code, mais l’utilisateur possède le navigateur et peut réécrire n’importe quoi entre le chargement de la page et la prochaine requête réseau.
L’OWASP Authorization Cheat Sheet énonce la règle pratique directement : les contrôles d’accès côté client peuvent améliorer l’expérience utilisateur, mais les décisions d’autorisation doivent être appliquées côté serveur, au niveau d’une passerelle ou dans une fonction serverless — car la logique côté client est facile à contourner. Ce cadre conceptuel est antérieur aux SPA modernes ; le guide Static Apps sur l’authentification le formulait ainsi : « l’utilisateur final peut exécuter du code arbitraire côté client sans autorisation préalable. »
Un contournement via les DevTools en 30 secondes
La démonstration la plus claire de l’échec de l’autorisation uniquement côté client consiste à la contourner soi-même. Cette manipulation est reproductible dans n’importe quel navigateur avec les DevTools, contre toute application React qui stocke le rôle dans l’état d’un composant plutôt que de le dériver à chaque requête depuis un token vérifié par le serveur :
- Connectez-vous en tant qu’utilisateur ordinaire (non administrateur). Le panneau d’administration est masqué — votre composant effectue le rendu
{user.role === 'admin' && <AdminPanel />}etuser.rolevaut'user'. - Ouvrez les DevTools et localisez l’état du composant contenant
user. Avec React DevTools, vous pouvez inspecter et modifier l’état des hooks directement ; sans cet outil, tout chemin de code qui expose l’objet utilisateur à une référence mutable fonctionne. - Définissez
rolesur'admin'. React effectue un nouveau rendu. Le panneau d’administration apparaît dans le DOM. - Cliquez sur le bouton de suppression exposé par le panneau. La requête est envoyée.
- Si le serveur applique l’autorisation, il lit l’identité depuis votre token — pas depuis votre état client modifié — et renvoie
403 Forbidden. Les données n’ont pas été modifiées.
L’attaque réussit à l’étape 3 (l’interface change) et échoue à l’étape 5 (le serveur rejette la requête) uniquement si un contrôle serveur existe. Sans contrôle serveur, l’étape 4 modifie des données réelles. Le contournement fonctionne précisément parce que le rôle réside dans un état client mutable ; il ne fonctionne pas lorsque le serveur redérive l’autorisation depuis un token vérifié à chaque requête.
Le serveur est le seul gardien qui compte

Discover how at OpenReplay.com.
Les décisions d’autorisation qui modifient des données ou exposent des ressources protégées doivent être prises et appliquées sur le serveur, car le serveur est le seul participant à la requête que l’utilisateur ne peut pas réécrire. Le backend est le gardien ultime : quelle que soit ce que le frontend affiche, masque ou désactive, l’évaluation de la requête par le serveur constitue la décision de référence. Les contrôles frontend ne remplacent pas l’application des règles côté backend.
Voici l’application côté serveur d’une permission unique, tasks:delete, sous la forme d’un Route Handler Next.js. La permission est lue depuis la session authentifiée, et non depuis ce que le client envoie dans le corps de la requête :
// app/api/tasks/[id]/route.ts — Next.js App Router
import { NextRequest, NextResponse } from 'next/server';
import { getSessionPermissions } from '@/lib/auth';
import { deleteTask } from '@/lib/tasks';
export async function DELETE(
req: NextRequest,
{ params }: { params: { id: string } },
) {
const permissions = await getSessionPermissions(req); // dérivé d'un token/session vérifié
if (!permissions.includes('tasks:delete')) {
return NextResponse.json(
{ error: 'forbidden', permission: 'tasks:delete' },
{ status: 403 },
);
}
await deleteTask(params.id);
return new NextResponse(null, { status: 204 });
}Le 403 inclut le nom de permission spécifique dans le corps de la réponse. Ce détail a son importance par la suite : il permet au client de distinguer un refus de permission de tout autre échec et d’afficher un message cohérent plutôt qu’une notification générique. Le statut 403 Forbidden est le choix sémantique correct selon la RFC 9110 §15.5.4, qui le définit comme le serveur comprenant la requête mais refusant de l’autoriser.
L’autorisation côté client est destinée à l’interface, pas au contrôle d’accès
L’autorisation côté client existe pour façonner l’interface : masquer les boutons d’administration aux non-administrateurs, protéger les routes pour que les utilisateurs n’arrivent pas sur un 403, et n’afficher que les éléments de menu pertinents. Elle améliore l’expérience en guidant les utilisateurs vers les actions qu’ils peuvent réellement effectuer — elle ne sécurise rien et ne le peut pas. Considérez le frontend comme la vitrine, pas le coffre-fort : il organise ce qui est accessible et proposé, tandis que le verrou reste côté serveur.
L’implémentation standard lit les permissions depuis le contexte et effectue un rendu conditionnel basé sur un identifiant de permission :
// components/TaskActions.tsx
'use client';
import { usePermissions } from '@/hooks/usePermissions';
export function TaskActions({ taskId }: { taskId: string }) {
const { can } = usePermissions();
return (
<div className="task-actions">
{can('tasks:delete') && (
<button onClick={() => deleteTask(taskId)}>Delete</button>
)}
</div>
);
}Notez l’identifiant : tasks:delete, et non role === 'admin'. Vérifier user.role === 'admin' couple votre interface à votre taxonomie de rôles ; vérifier can('tasks:delete') la couple à l’action que le serveur applique réellement — et le serveur ne se soucie pas du rôle qui l’a accordée. Lorsque vous scindez ultérieurement admin en admin et billing-admin, les vérifications basées sur les noms de permission restent intactes. L’OWASP Authorization Cheat Sheet recommande de séparer les rôles des permissions précisément pour cette raison. Le RBAC reste un modèle de contrôle d’accès courant pour les applications frontend ; pour la question complète du choix entre RBAC, ABAC, ACL et PBAC, la comparaison des modèles de contrôle d’accès de LogRocket la couvre bien.
Une remarque pratique : les replays de session d’interfaces avec contrôle de rôle font souvent apparaître le bref instant où un utilisateur non autorisé voit le bouton d’administration avant qu’une vérification de permission récupérée côté client se résolve et le masque — un flash d’interface non autorisée causé par l’arrivée de l’état des permissions après le premier rendu. La solution consiste à effectuer le rendu côté serveur de l’état des permissions ou à les précharger avant le rendu, ce que le pattern de transfert de la section suivante réalise par conception.
Les deux couches doivent être cohérentes : la dérive des permissions
La vue des permissions côté frontend est un cache de ce que le serveur autorisera, et les deux doivent rester synchronisés. Lorsque l’état des permissions côté frontend diverge des règles d’application côté serveur, l’un de ces deux échecs se produit : un bouton que le serveur rejettera avec un 403 (un workflow exploitable), ou une action que le serveur autorise mais que l’interface ne présente jamais (une fonctionnalité cachée). Le premier est un problème de sécurité et d’expérience utilisateur — vous affichez des affordances qui ne fonctionnent pas, et un attaquant peut étudier lesquelles le serveur honore réellement. Le second est une pure perte de fonctionnalité — les utilisateurs ne peuvent pas accéder à quelque chose auquel ils ont droit.
La façon de prévenir la dérive est structurelle : définir une source de vérité unique et alimenter les deux couches depuis celle-ci.
Le pattern de transfert
Le pattern de transfert est une architecture d’autorisation dans laquelle le serveur détient la source de vérité unique pour les permissions et le client en détient un cache — alimenté à la connexion, utilisé pour effectuer le rendu de l’interface, mais consultatif plutôt qu’autoritaire. Le circuit complet fonctionne ainsi : le serveur détermine les permissions de l’utilisateur, les envoie au client dans un format de transmission connu, le client les met en cache dans un contexte, l’interface effectue le rendu à partir du cache, l’utilisateur agit, et le serveur re-vérifie lors de la requête. Le même identifiant de permission apparaît à chaque étape.
Commencez par le format de transmission. À la connexion (ou lors du rendu initial du Server Component), le serveur émet l’ensemble des permissions :
{
"userId": "u_8123",
"permissions": ["tasks:read", "tasks:create", "tasks:delete"]
}Si vous transportez les permissions dans un JWT, elles résident comme claims dans le payload du token. Un JWT signé (un JWS) porte les claims dans un payload encodé en base64url qui est protégé en intégrité, mais pas chiffré — la signature prouve que les claims n’ont pas été altérés, mais les claims ne sont pas secrets et sont lisibles par le client. Les JWT chiffrés (JWE) sont une construction différente. Cette distinction est issue de la RFC 7519, la spécification JWT. La conséquence pratique : les claims de permission d’un JWT constituent un cache parfaitement valable pour le rendu, mais ils ne restent qu’un cache. Le serveur doit valider l’autorisation à chaque requête en utilisant la source de vérité sur laquelle repose votre architecture.
Injectez le cache dans le contexte une seule fois, idéalement depuis un Server Component afin que les données soient présentes dès le premier rendu :
// app/layout.tsx — Server Component, Next.js App Router
import { getSessionPermissions } from '@/lib/auth';
import { PermissionsProvider } from '@/hooks/usePermissions';
export default async function RootLayout({
children,
}: {
children: React.ReactNode;
}) {
const permissions = await getSessionPermissions(); // même source que celle utilisée par l'API
return (
<html lang="en">
<body>
<PermissionsProvider permissions={permissions}>
{children}
</PermissionsProvider>
</body>
</html>
);
}// hooks/usePermissions.tsx
'use client';
import { createContext, useContext } from 'react';
const PermissionsContext = createContext<string[]>([]);
export function PermissionsProvider({
permissions,
children,
}: {
permissions: string[];
children: React.ReactNode;
}) {
return (
<PermissionsContext.Provider value={permissions}>
{children}
</PermissionsContext.Provider>
);
}
export function usePermissions() {
const permissions = useContext(PermissionsContext);
return { can: (p: string) => permissions.includes(p) };
}Étant donné que getSessionPermissions() est la même fonction appelée par le Route Handler, l’interface et le gardien lisent des données identiques, et tasks:delete a la même signification des deux côtés. Charger les permissions dans un Server Component (plutôt que de les récupérer dans un useEffect côté client) signifie que l’ensemble des permissions est disponible dès le premier rendu — pas de flash d’interface incorrecte, pas de scintillement pendant la résolution d’une vérification.
React Server Components et Server Actions : la frontière est syntaxique
Dans le Next.js App Router, les termes « client » et « serveur » décrivent l’endroit où le code s’exécute, et non un appel réseau que vous effectuez manuellement — et c’est cette distinction qui fait des Server Actions un endroit légitime pour appliquer l’autorisation. Une Server Action Next.js qui effectue une vérification de permission avant de modifier des données constitue une autorisation côté serveur, quel que soit son emplacement dans l’arborescence des composants : le code s’exécute sur le serveur, l’utilisateur ne peut pas le modifier, et le contrôle ne peut pas être contourné en modifiant l’état côté client.
Dans la documentation actuelle du Next.js App Router, la directive 'use server' marque une Server Function ; une Server Function utilisée dans un contexte d’action/mutation est également appelée Server Action. La directive est le marqueur de frontière — le code sous cette directive s’exécute sur le serveur même s’il est écrit dans un fichier .tsx aux côtés de composants client :
// app/tasks/actions.ts — Next.js App Router
'use server';
import { getSessionPermissions } from '@/lib/auth';
import { deleteTask } from '@/lib/tasks';
export async function deleteTaskAction(taskId: string) {
const permissions = await getSessionPermissions(); // s'exécute sur le serveur
if (!permissions.includes('tasks:delete')) {
return { ok: false as const, error: 'forbidden', permission: 'tasks:delete' };
}
await deleteTask(taskId);
return { ok: true as const };
}Il s’agit du même contrôle tasks:delete que dans le Route Handler, dans la même position d’application. Modifier l’état côté client pour simuler role === 'admin' n’a aucun effet ici — l’action redérive les permissions depuis la session côté serveur. Les Server Actions ne suppriment pas le besoin du gardien ; elles constituent un autre endroit où le gardien réside. Consultez la documentation de la directive use server de Next.js pour la sémantique complète de la directive.
Lorsque votre SPA appelle directement une API tierce
Lorsque votre SPA appelle directement une API tierce depuis le navigateur, le tiers est votre serveur pour les besoins de l’autorisation — un prestataire de paiement, un CMS headless ou un backend-as-a-service constitue le gardien, que vous l’ayez développé ou non. La frontière d’application ne disparaît pas parce que vous n’avez pas écrit le backend ; elle se déplace vers celui qui évalue la requête. Vos contrôles côté client restent uniquement destinés à l’expérience utilisateur, et les règles d’autorisation du tiers constituent le gardien. Si vous ne pouvez pas appliquer une décision dans du code que vous contrôlez, faites transiter la requête par votre propre backend afin de pouvoir le faire.
Modes de défaillance : ce qui se passe quand on néglige une couche
Négliger l’une ou l’autre couche produit une défaillance distincte et prévisible. L’autorisation uniquement côté client est trivialement contournable ; l’autorisation uniquement côté serveur laisse les utilisateurs perplexes. Aucune des deux n’est acceptable seule.
| Couche négligée | Ce qui échoue | Qui l’exploite | Expérience utilisateur |
|---|---|---|---|
| Côté serveur (client uniquement) | L’autorisation n’est pas appliquée du tout | Tout utilisateur avec les DevTools ou curl | Semble correct — jusqu’à ce que des données soient modifiées par quelqu’un qui ne le devrait pas |
| Côté client (serveur uniquement) | L’interface affiche des actions que le serveur rejettera | Pas d’exploitation ; c’est un défaut d’expérience utilisateur | Les utilisateurs cliquent sur un bouton, reçoivent un 403, recliquent, abandonnent |
La règle est suffisamment courte pour être mémorisée : effectuez le rendu avec les permissions côté client, appliquez les règles avec les permissions côté serveur, et utilisez les mêmes identifiants de permission dans les deux. Violer la première règle et les utilisateurs cliquent sur des boutons qui renvoient des 403. Violer la seconde et tout utilisateur avec les DevTools peut s’octroyer des privilèges.
L’expérience utilisateur en cas d’échec d’autorisation : 403 vs 401
Lorsque le serveur rejette une action que l’interface pensait autorisée, le code de statut de la réponse vous indique exactement ce qu’il faut montrer à l’utilisateur. Un 401 signifie que l’utilisateur n’est pas authentifié — redirigez vers la page de connexion. Un 403 signifie qu’il est authentifié mais non autorisé — affichez un état de refus de permission, pas une erreur générique, afin que l’utilisateur comprenne pourquoi l’action a échoué. Ces sémantiques sont définies par la RFC 9110 : §15.5.2 définit le 401 Unauthorized (l’authentification est requise et a échoué ou n’a pas été fournie), et §15.5.4 définit le 403 Forbidden (le serveur a compris la requête mais refuse de l’autoriser).
async function deleteTask(taskId: string) {
const res = await fetch(`/api/tasks/${taskId}`, { method: 'DELETE' });
if (res.status === 401) {
window.location.assign('/login');
return;
}
if (res.status === 403) {
const body = await res.json();
showPermissionDenied(body.permission); // ex. : "Vous n'avez pas la permission de supprimer des tâches."
return;
}
if (!res.ok) {
showError('Une erreur est survenue. Veuillez réessayer.');
return;
}
// succès
}Traiter le 403 de manière distincte est là où la dérive client/serveur devient visible pour l’utilisateur. Les replays de session sur des réponses 403 montrent fréquemment un utilisateur cliquant sur un bouton, recevant une notification d’erreur générique, puis recliquant — signe que l’interface n’a jamais communiqué que l’action était refusée spécifiquement pour des raisons de permission. Afficher le nom de la permission depuis le corps de la réponse (le champ permission: 'tasks:delete' envoyé par le serveur) comble cet écart. La RFC définit ce que signifie le 403 ; la façon dont vous le présentez relève de votre choix, mais c’est la signification que l’interface doit refléter.
Conclusion
L’autorisation opère à deux frontières avec deux responsabilités : le client façonne l’interface, le serveur décide de ce qui se passe, et les mêmes identifiants de permission circulent dans les deux depuis une source de vérité unique côté serveur. Auditez votre propre code pour détecter les deux modes de défaillance — recherchez les vérifications de rôle ou de permission qui protègent des mutations de données sans application correspondante côté serveur (un contournement en attente de se produire), et recherchez les vérifications côté client qui ont divergé de ce que votre API renvoie (un 403 que vos utilisateurs ne peuvent pas comprendre). Partout où un contrôle modifie des données, confirmez que le serveur redérive la décision depuis une session vérifiée, et non depuis quoi que ce soit que le client puisse réécrire.
FAQ
Est-il sûr de stocker les permissions utilisateur dans un JWT si le client peut les lire ?
Oui, à condition de traiter le token comme un cache et non comme une frontière de sécurité. Un JWT signé (un JWS) porte les claims dans un payload encodé en base64url qui est protégé en intégrité mais non chiffré, de sorte que le client peut lire les permissions, mais la signature empêche toute altération. Le risque ne réside pas dans l'exposition de la liste des permissions ; il réside dans le fait de lui faire confiance. Le serveur doit valider l'autorisation à chaque requête selon le modèle d'autorisation utilisé par l'application.
Une Server Action Next.js a-t-elle besoin de son propre contrôle d'autorisation si la page a déjà protégé l'interface ?
Oui. La protection de l'interface contrôle uniquement ce qui est rendu ; elle ne protège pas la mutation. Une Server Action s'exécute sur le serveur et peut être invoquée indépendamment de la page qui l'a rendue, elle doit donc redériver les permissions depuis la session vérifiée et rejeter elle-même les appels non autorisés. La directive 'use server' marque l'endroit où le code s'exécute, pas s'il est autorisé. Traitez chaque Server Action comme un point d'application, exactement comme un Route Handler.
Quel code de statut une API doit-elle renvoyer lorsqu'un utilisateur est connecté mais ne dispose pas de la permission pour une action ?
Renvoyez 403 Forbidden, pas 401 Unauthorized. La RFC 9110 définit le 401 comme une authentification requise ayant échoué ou n'ayant pas été fournie, et le 403 comme le serveur comprenant la requête mais refusant de l'autoriser. Un utilisateur connecté sans permission est authentifié mais non autorisé, ce qui correspond précisément au 403. Le client doit rediriger vers la page de connexion sur un 401 et afficher un état de refus de permission sur un 403, afin que les deux échecs restent visuellement et comportementalement distincts.
Pourquoi vérifier 'tasks:delete' plutôt que 'role === admin' côté frontend ?
Les identifiants de permission survivent aux restructurations de rôles ; les comparaisons de noms de rôle, non. Vérifier 'role === admin' couple l'interface à votre taxonomie de rôles actuelle, de sorte que scinder admin en admin et billing-admin ultérieurement casse chaque vérification. Vérifier 'tasks:delete' couple l'interface à l'action que le serveur applique réellement, ce qui ne change pas lorsque les rôles sont réorganisés.


