Harnais LLM : Pourquoi le wrapper compte plus que le modèle
Les harness LLM, pas seulement les modèles, déterminent le succès des agents. Orchestration, outils, contexte et vérification.

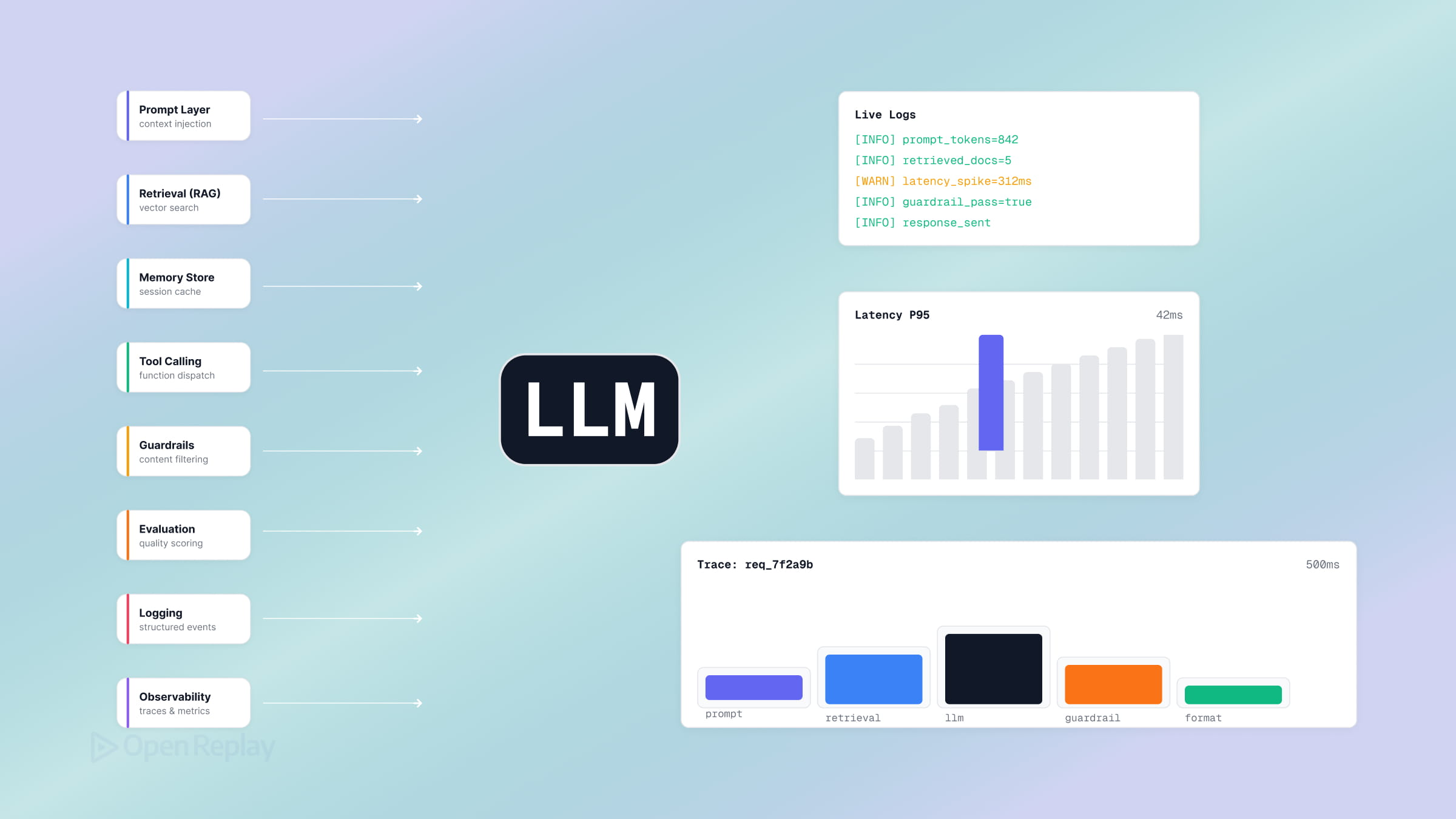
Le harnais désigne l’ensemble du code, de la configuration et de la logique d’exécution qui ne constitue pas le modèle lui-même — la boucle d’orchestration, les outils, la mémoire, la gestion du contexte, l’état, la gestion des erreurs, les garde-fous et les vérifications qui, ensemble, déterminent si un agent réussit ou échoue. Si vous avez déjà déployé une fonctionnalité LLM avec le SDK OpenAI ou Anthropic et observé des boucles infinies, des appels d’outils hallucinés ou des oublis de ce que l’utilisateur a dit trois tours plus tôt, vous avez déjà atteint les limites d’un harnais trop léger — et la plupart du temps, le modèle n’était pas en cause.
Cet article vous propose un modèle mental précis du harnais, les preuves qu’il génère plus de variance dans les résultats que le choix du modèle, un harnais JS/TS exécutable que vous pouvez lire de bout en bout, et quatre décisions que l’équipe frontend possède réellement lors du déploiement d’une fonctionnalité IA intégrée au produit.
Points clés
- Le harnais est l’ensemble du code, de la configuration et de la logique d’exécution qui ne constitue pas le modèle ; Vivek Trivedy de LangChain le formule ainsi : « si vous n’êtes pas le modèle, vous êtes le harnais. »
- L’équipe v0 de Vercel a supprimé 80 % des outils de son agent et a observé le taux de réussite des tâches passer de 80 % à 100 %, l’utilisation moyenne des tokens chuter de 37 % — sans changer le modèle.
- Sur le classement CORE-Bench Hard de Princeton HAL, Claude Opus 4.5 obtient 42,22 % avec CORE-Agent et 77,78 % avec Claude Code — un écart de 35,56 points dû uniquement au scaffold, sur le même modèle.
- Le débat harnais-vs-modèle n’est pas tranché : SWE-Atlas de Scale AI montre que les effets du scaffold varient selon le modèle, tandis que METR a constaté que Claude Code et Codex n’étaient pas statistiquement meilleurs que ses propres scaffolds par défaut dans une évaluation de l’horizon temporel.
- Tout harnais doit comporter au moins une vérification déterministe — un test, un validateur de schéma, une regex — avant de retourner un résultat à l’utilisateur.
Qu’est-ce qu’un harnais d’agent ?
Un harnais d’agent est le système logiciel complet enveloppant un appel LLM : la boucle d’orchestration qui décide quand appeler le modèle, les outils que le modèle peut invoquer, la mémoire et le contexte auxquels il a accès, l’état qu’il conserve entre les tours, ainsi que les garde-fous et les vérifications qui contrôlent ses sorties. La formule canonique vient de Vivek Trivedy de LangChain : « si vous n’êtes pas le modèle, vous êtes le harnais. » Le modèle produit des tokens ; le harnais est tout ce qui transforme ces tokens en une fonctionnalité fiable.
Le modèle mental le plus clair pour appréhender cette relation provient de l’essai de Beren Millidge de 2023, qui cadre les systèmes LLM scaffoldés comme des ordinateurs en langage naturel : le LLM correspond au CPU, le prompt et la fenêtre de contexte correspondent à la RAM (rapide mais limitée), et la mémoire externe comme une base de données vectorielle correspond à un stockage de type disque. Les outils jouent le rôle de pilotes de périphériques qui interagissent avec le monde extérieur, et le harnais est le système d’exploitation qui coordonne l’ensemble. Un CPU sans système d’exploitation ne calcule rien d’utile. Le modèle est nécessaire, mais pas suffisant.
La terminologie dans ce domaine est foisonnante ; voici comment la fixer une bonne fois pour toutes. Le modèle est le LLM — des poids et une API. Le harnais (parfois appelé scaffold) est le code environnant. L’agent est le comportement émergent : une entité orientée vers un objectif, utilisant des outils et capable d’autocorrection, avec laquelle l’utilisateur interagit. Le cours Agents de Hugging Face définit un agent comme un système qui utilise un modèle d’IA pour interagir avec son environnement et atteindre un objectif défini par l’utilisateur. Quand quelqu’un dit « j’ai construit un agent », il a construit un harnais et l’a connecté à un modèle. L’annonce par Anthropic du Claude Agent SDK décrit lui-même le Claude Code SDK comme « le harnais d’agent qui propulse Claude Code ».
Pourquoi le wrapper compte-t-il plus que le modèle ?

Discover how at OpenReplay.com.
Le wrapper compte plus que le modèle parce que le même modèle, derrière un harnais différent, produit des résultats radicalement différents — et ces écarts sont importants, reproductibles et mesurés sur des benchmarks publics. Le point de données le plus probant : l’équipe v0 de Vercel a supprimé 80 % des outils de son agent et a observé le taux de réussite des tâches passer de 80 % à 100 %, l’utilisation moyenne des tokens chuter de 37 %, et une requête en cas de pire scénario passer de 724 secondes à 141 — sans changer le modèle. La correction était entièrement dans le harnais : moins d’outils, mieux ciblés.
Deux autres résultats vont dans le même sens. LangChain a indiqué avoir fait passer son agent de codage d’une position hors du top 30 au top 5 sur Terminal-Bench 2.0 en modifiant uniquement le harnais autour d’un modèle inchangé, selon son propre article. Et sur le classement CORE-Bench Hard de Princeton HAL, Claude Opus 4.5 obtient 42,22 % avec le scaffold CORE-Agent et 77,78 % avec Claude Code — un écart de 35,56 points sur le même modèle, le classement faisant également état de 95,5 % lors de la validation manuelle de l’exécution Claude Code.
| Étude | Modèle modifié ? | Harnais modifié ? | Avant | Après |
|---|---|---|---|---|
| Vercel v0 | Non | Oui (−80 % d’outils) | 80 % de réussite | 100 % de réussite, −37 % de tokens |
| LangChain / Terminal-Bench 2.0 | Non | Oui | Hors Top 30 | Top 5 |
| Princeton CORE-Bench Hard | Non (Opus 4.5) | Oui (scaffold) | 42,22 % | 77,78 % |
Le débat n’est pas tranché, et le simplifier à l’excès nuit à la crédibilité. SWE-Atlas de Scale AI compare les scaffolds d’agents de codage propriétaires avec le mini-SWE-agent minimal et montre que les effets du scaffold varient selon le modèle, les scaffolds natifs produisant des améliorations notables par rapport à la base minimale. Par ailleurs, METR a constaté que Claude Code et Codex n’étaient pas statistiquement meilleurs que ses propres scaffolds par défaut dans une évaluation de l’horizon temporel. Les deux effets sont réels ; celui qui domine dépend du régime de tâches. La lecture honnête, comme MongoDB le formule, est que « le LLM est la plus petite partie » — mais les gains du harnais ne sont pas illimités, et un modèle puissant sur une tâche simple plafonne ce que le scaffolding peut récupérer.
Quels sont les composants d’un harnais LLM ?
Un harnais de production se décompose en huit composants, chacun représentant un point de défaillance potentiel pour un wrapper trop léger : la boucle d’orchestration, les outils, la mémoire, la gestion du contexte, la construction du prompt, l’état, la gestion des erreurs, et les garde-fous avec boucles de vérification.
Boucle d’orchestration. La boucle implémente le cycle Pensée–Action–Observation (le pattern ReAct) : appeler le modèle, vérifier s’il a demandé un outil, exécuter l’outil, réinjecter le résultat, répéter jusqu’à ce que le modèle réponde ou qu’un garde-fou se déclenche. Comme l’analyse de rétro-ingénierie de Claude Code par Vikash Rungta le formule, le runtime est une « boucle stupide » où toute l’intelligence réside dans le modèle et où le harnais ne fait que gérer les tours. Mécaniquement, c’est une boucle while avec un plafond de tours.
Outils. Les outils sont les mains de l’agent — des fonctions exposées au modèle sous forme de schémas (nom, description, types de paramètres). La couche d’outils gère l’enregistrement, la validation des arguments, l’exécution et le formatage des résultats en observations lisibles par le modèle. Un outil search_docs dans un widget d’aide est un outil ; get_order_status en est un autre.
Mémoire. La mémoire à court terme correspond à la conversation en cours ; la mémoire à long terme persiste entre les sessions. Dans un widget de chat, la mémoire à court terme est le tableau de messages que vous rejouez à chaque tour ; la mémoire à long terme peut être un résumé par utilisateur que vous chargez au démarrage de la session.
Gestion du contexte. La ressource rare est la fenêtre de contexte, et le mode de défaillance est la dégradation du contexte — la qualité se dégrade quand la fenêtre se remplit de tokens à faible valeur informative. Selon les recommandations d’Anthropic en matière d’ingénierie du contexte, l’objectif est le plus petit ensemble de tokens à haute valeur informative. Stratégies : la compaction (résumer les anciens tours) et la récupération à la demande (récupérer au moment opportun plutôt que de précharger).
Construction du prompt. Le harnais assemble l’entrée de manière hiérarchique : prompt système, définitions des outils, mémoire, historique de la conversation, message courant. L’ordre compte ; le contexte important doit figurer au début et à la fin de la fenêtre.
État. L’état est ce qui survit entre les tours et les pannes — la position de l’agent dans une tâche multi-étapes, les sorties intermédiaires, les points de contrôle. Un widget de chat qui « oublie » la contrainte exprimée plus tôt par l’utilisateur a un problème d’état, pas un problème de modèle.
Gestion des erreurs. Une tâche de 10 étapes avec 99 % de réussite par étape n’a qu’environ 90 % de réussite de bout en bout, car les erreurs se cumulent. Le pattern clé : retourner une erreur d’outil au modèle comme observation pour qu’il puisse s’autocorriger, plutôt que de lever une exception et interrompre l’exécution.
Garde-fous et boucles de vérification. Les garde-fous contraignent ce que l’agent peut faire ; les boucles de vérification contrôlent ce qu’il a produit. L’article sur l’ingénierie des harnais de Martin Fowler et Birgitta Böckeler cadre la vérification comme des guides (feedforward — orienter avant d’agir) et des capteurs (feedback — observer et s’autocorriger), répartis en contrôles computationnels (déterministes : tests, linters) et inférentiels (LLM-as-judge).
Comment construire un harnais d’agent en JavaScript ?
Un harnais minimal mais complet est une boucle ReAct avec un plafond de tours, un outil bien ciblé, un gestionnaire d’erreur-comme-observation, et une vérification déterministe. L’exemple ci-dessous utilise le SDK Anthropic et Zod pour la validation de schéma. La vérification est la partie que la plupart des wrappers légers omettent — sans elle, l’agent n’a aucun moyen de savoir qu’il se trompe.
import Anthropic from "@anthropic-ai/sdk";
import { z } from "zod";
const client = new Anthropic();
// One tool, narrowly scoped. Fewer tools = fewer spurious calls.
const tools: Anthropic.Tool[] = [
{
name: "get_order_status",
description: "Look up the status of an order by its numeric ID.",
input_schema: {
type: "object",
properties: { orderId: { type: "number" } },
required: ["orderId"],
},
},
];
// Deterministic verification: the model's tool input must match this schema.
const OrderArgs = z.object({ orderId: z.number().int().positive() });
async function runOrder(orderId: number) {
// Stand-in for a real lookup.
return { orderId, status: "shipped", eta: "2026-03-04" };
}
export async function harness(userMessage: string) {
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: userMessage },
];
// Max-turns guard: the single most important safety rail against looping.
for (let turn = 0; turn < 6; turn++) {
const res = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: "You are an order-status assistant. Use tools when asked about orders.",
tools,
messages,
});
const toolUse = res.content.find(
(b): b is Anthropic.ToolUseBlock => b.type === "tool_use"
);
if (!toolUse) return res.content; // No tool call → the model answered.
messages.push({ role: "assistant", content: res.content });
let observation: string;
const parsed = OrderArgs.safeParse(toolUse.input);
if (!parsed.success) {
// Verification failed: return the error AS an observation, don't throw.
observation = `Invalid arguments: ${parsed.error.message}`;
} else {
try {
observation = JSON.stringify(await runOrder(parsed.data.orderId));
} catch (e) {
observation = `Tool error: ${(e as Error).message}`; // also an observation
}
}
messages.push({
role: "user",
content: [{ type: "tool_result", tool_use_id: toolUse.id, content: observation }],
});
}
return [{ type: "text", text: "Could not complete the request." }];
}Quatre choix de conception dans ces ~50 lignes portent l’essentiel de la fiabilité. La boucle for avec un plafond de tours est à la fois la boucle d’orchestration et le garde-fou anti-boucle infinie. L’outil unique maintient le schéma d’outils compact. Le safeParse de Zod est la vérification déterministe qui intercepte les arguments hallucinés avant qu’ils n’atteignent votre backend. Et les échecs de validation comme les erreurs d’exécution sont retournés comme observations, sans lever d’exception — permettant ainsi au modèle de se corriger plutôt que d’interrompre l’exécution. Les mécaniques d’utilisation des outils d’Anthropic sont documentées dans le guide d’utilisation des outils ; la boucle équivalente avec le SDK OpenAI utilise tool_calls et des messages role: "tool".
Pourquoi les développeurs frontend possèdent-ils plus du harnais qu’ils ne le pensent ?
Les développeurs frontend possèdent déjà un harnais dès lors qu’ils déploient un widget de chat IA, un assistant de recherche intégré au produit ou une interface copilote — ce sont simplement des harnais plus légers que les harnais agentiques. La plupart des défaillances dont se plaignent les utilisateurs (boucles infinies, appels d’outils hallucinés, contexte oublié, contraintes ignorées) sont des défaillances du harnais, pas du modèle. Quand une équipe frontend déploie une fonctionnalité IA, le choix du modèle n’est qu’une décision parmi d’autres, et les décisions relatives au harnais — périmètre des outils, contexte à conserver, ce qu’il faut vérifier — reçoivent généralement moins d’attention à la conception qu’elles ne le méritent.
La correspondance est directe. Un utilisateur qui voit l’assistant « régénérer » la même mauvaise réponse observe une boucle d’orchestration sans vérification. Un utilisateur dont la contrainte exprimée disparaît deux tours plus tard observe un problème d’état et de gestion du contexte. Un appel d’outil qui se déclenche avec un argument erroné et retourne une réponse confuse est l’absence d’une vérification de schéma — exactement l’étape safeParse décrite ci-dessus. Aucun de ces problèmes ne se résout en changeant de modèle. Ils se résolvent en resserrant le wrapper que vous possédez déjà.
Quelle épaisseur doit avoir mon harnais ? Quatre décisions appartenant aux équipes frontend
Une équipe frontend qui déploie une fonctionnalité IA intégrée au produit contrôle réellement quatre décisions de harnais : le périmètre des outils, la stratégie de contexte, les boucles de vérification et l’épaisseur du harnais. La liste plus large à l’échelle du domaine — agent unique vs. multi-agents, ReAct vs. plan-and-execute, permissions, exécution durable, gouvernance de flotte — se situe à des couches d’infrastructure que la plupart des widgets de chat n’atteignent jamais.
-
Périmètre des outils — commencez avec moins de 10 outils et étendez à contrecœur. Donner à un agent plus d’outils qu’il n’en a besoin dégrade systématiquement les performances, car chaque schéma d’outil supplémentaire consomme du contexte et augmente la probabilité d’un appel parasite. Le résultat de Vercel est la preuve centrale : supprimer 80 % des outils a tout amélioré.
-
Stratégie de contexte — compaction et récupération à la demande plutôt que remplissage de la fenêtre. Ne préchargez pas toute la base de connaissances dans le prompt. Résumez les anciens tours lorsque vous approchez de la limite de la fenêtre, et récupérez les documents à la demande. Les recommandations d’Anthropic en matière d’ingénierie du contexte définissent l’objectif comme le plus petit ensemble de tokens à haute valeur informative.
-
Boucles de vérification — tout harnais doit comporter au moins une vérification déterministe avant de retourner un résultat à l’utilisateur. Un validateur de schéma, une regex, un test unitaire — quelque chose que le harnais peut exécuter sans dépendre du jugement du modèle lui-même. Sans cela, l’agent n’a aucun moyen de savoir qu’il se trompe. Selon la distinction computationnel/inférentiel de Böckeler, commencez par une vérification computationnelle peu coûteuse ; ajoutez un LLM-as-judge uniquement lorsque la correction sémantique l’exige.
-
Épaisseur du harnais — commencez léger, n’ajoutez de la structure que lorsqu’un pattern de défaillance se répète. Ne préconstruisez pas une orchestration pour des défaillances que vous n’avez pas encore observées. Ajoutez une nouvelle tentative, un garde-fou ou une étape de vérification uniquement lorsqu’une défaillance spécifique apparaît plus d’une fois.
Observer les replays de session d’une fonctionnalité IA en production est l’un des moyens les plus rapides de lire la qualité du harnais à partir du comportement des utilisateurs, car les signatures diagnostiques sont visibles sans aucune télémétrie au niveau du modèle. La reformulation répétée de la même demande signale un contexte perdu ou une boucle de vérification qui ne se déclenche jamais. L’abandon en milieu de tâche multi-étapes se trace souvent jusqu’à une erreur d’outil silencieuse qui remonte comme une réponse vague. Le comportement copier-puis-modifier signale une lacune de vérification — une sortie qui a passé les contrôles du harnais mais a échoué aux critères de l’utilisateur. Les clics répétés sur « régénérer » ou « réessayer » sont la signature d’un harnais en boucle qui ne peut pas détecter son propre état d’échec.
Vers où se dirige la conception des harnais ?
Les modèles sont désormais post-entraînés avec leurs harnais dans la boucle — comme LangChain le note dans sa discussion sur l’architecture des harnais d’agents, des produits comme Claude Code et Codex combinent l’entraînement du modèle et la conception du harnais dans un cycle de rétroaction — ce qui signifie que le harnais n’est plus un wrapper interchangeable mais une partie co-évoluée de la surface du produit. Pour les développeurs, cela implique que le harnais devient une partie du produit que vous concevez, et non un adaptateur générique que vous pouvez transposer d’un modèle à l’autre sans modification.
Cela vous donne un test de pérennité clair, tiré de la métaphore du scaffolding : si votre conception monte en puissance proprement avec un modèle plus fort — même harnais, meilleurs résultats — elle est solide. Si elle nécessite plus de scaffolding pour compenser à mesure que le modèle s’améliore, le harnais masque un problème de modèle ou de tâche que vous devriez corriger ailleurs. Le scaffolding, comme celui de la construction, est censé être retiré quand la structure tient d’elle-même.
La prochaine fois que votre fonctionnalité IA boucle, oublie ou retourne quelque chose de manifestement faux avec assurance, auditez le harnais avant d’auditer le modèle. Commencez par les quatre décisions ci-dessus — périmètre des outils, stratégie de contexte, une vérification déterministe et l’épaisseur — et ajoutez la plus petite quantité de structure qui fait cesser la défaillance de se reproduire.
FAQ
Quelle est la différence entre un harnais et un scaffold ?
Les deux termes sont utilisés de manière interchangeable en pratique ; ils désignent tous deux l'ensemble du code, de la configuration et de la logique d'exécution entourant le modèle qui ne constitue pas le modèle lui-même. « Scaffold » est le terme le plus courant dans la littérature des benchmarks, comme la comparaison CORE-Agent vs. scaffold Claude Code de Princeton, tandis que « harnais » est privilégié dans les contextes de production et de SDK. Vivek Trivedy de LangChain efface la distinction avec la règle : si vous n'êtes pas le modèle, vous êtes le harnais.
Dois-je retourner une erreur d'outil au modèle ou la lever dans mon harnais ?
Retournez l'erreur au modèle comme observation plutôt que de la lever. Lever une exception interrompt l'exécution ; retourner l'erreur comme résultat d'outil permet au modèle de voir ce qui s'est mal passé et de s'autocorriger au tour suivant. Cela est important car les erreurs se cumulent dans les tâches multi-étapes, où une tâche de 10 étapes avec 99 % de réussite par étape tombe à environ 90 % de réussite de bout en bout. Les échecs de validation de schéma comme les exceptions d'exécution doivent être interceptés et réinjectés comme observations, jamais comme exceptions non gérées.
Ajouter plus d'outils améliore-t-il les performances de l'agent ?
Non, ajouter plus d'outils dégrade systématiquement les performances au-delà d'un certain seuil. Chaque schéma d'outil consomme des tokens de la fenêtre de contexte et augmente la probabilité d'un appel d'outil parasite ou incorrect. L'équipe v0 de Vercel a supprimé 80 % des outils de son agent et a observé le taux de réussite des tâches passer de 80 % à 100 % et l'utilisation moyenne des tokens chuter de 37 % sur le même modèle. La règle pratique est de commencer avec moins de 10 outils et d'étendre uniquement lorsqu'un manque réel apparaît.
Puis-je interchanger les modèles dans le même harnais sans modification ?
De moins en moins. Comme LangChain le note dans sa discussion sur l'architecture des harnais d'agents, des produits comme Claude Code et Codex combinent l'entraînement du modèle et la conception du harnais dans un cycle de rétroaction. Cela fait du harnais une partie co-évoluée de la surface du produit plutôt qu'un adaptateur générique. Un test de pérennité utile est de vérifier si votre conception monte en puissance proprement avec un modèle plus fort sur le même harnais ; si elle nécessite plus de scaffolding pour compenser à mesure que le modèle s'améliore, le harnais masque un problème plus profond.


