
Fundamentos de Design de Banco de Dados Relacional

A maioria dos problemas de banco de dados não é causada por consultas ruins — eles são causados por um schema inadequado. Se suas tabelas estão mal estruturadas desde o início, nenhuma quantidade de SQL inteligente compensará totalmente. Este artigo aborda os princípios fundamentais do design de banco de dados relacional: como estruturar tabelas, definir chaves, modelar relacionamentos e usar constraints para manter seus dados confiáveis.
Principais Pontos
- Um banco de dados relacional armazena dados em tabelas vinculadas por chaves, não duplicando informações entre elas
- Chaves primárias identificam exclusivamente linhas; chaves estrangeiras expressam relacionamentos entre tabelas
- Relacionamentos um-para-muitos usam uma chave estrangeira no lado “muitos”, enquanto relacionamentos muitos-para-muitos exigem uma tabela de junção
- Normalização (1FN, 2FN, 3FN) reduz redundância e previne anomalias de dados, embora a desnormalização deliberada seja às vezes justificada
- Constraints de banco de dados (
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,CHECK) são sua última linha de defesa para integridade de dados
O Que Realmente É um Banco de Dados Relacional
Um banco de dados relacional armazena dados em tabelas — grades estruturadas de linhas e colunas. Cada tabela representa um único assunto ou entidade, como users, orders ou products. Cada linha é um registro. Cada coluna é um atributo desse registro.
O poder do modelo relacional vem da vinculação de tabelas entre si, em vez de duplicar dados entre elas. O conceito se origina do modelo relacional proposto por Edgar F. Codd em 1970, que ainda forma a base teórica dos bancos de dados SQL modernos.
Chaves Primárias e Chaves Estrangeiras: A Fundação dos Schemas Relacionais
Toda tabela precisa de uma chave primária — uma coluna (ou combinação de colunas) que identifica exclusivamente cada linha. Uma boa chave primária é:
- Única em todas as linhas
- Nunca nula
- Estável — não deve mudar após ser atribuída
A maioria dos bancos de dados SQL modernos suporta colunas de identidade (inteiros auto-incrementais) que geram identificadores únicos automaticamente. Muitos sistemas também suportam chaves baseadas em UUID, frequentemente geradas através de funções integradas do banco de dados ou valores padrão. Ambas são escolhas válidas dependendo do seu contexto. Inteiros auto-incrementais são simples e eficientes. UUIDs são mais adequados para sistemas distribuídos onde múltiplas fontes geram registros independentemente.
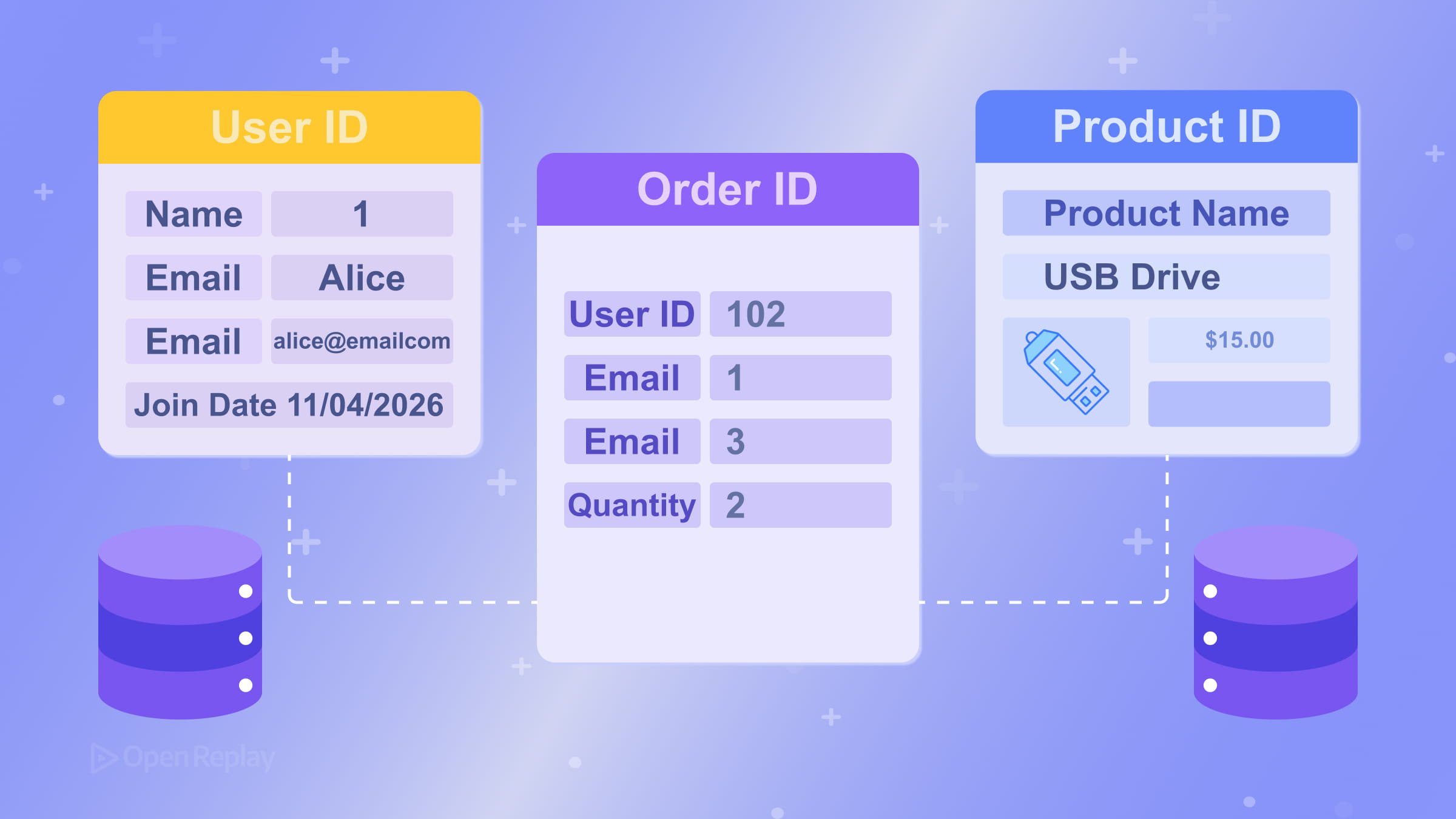
Uma chave estrangeira é uma coluna em uma tabela que referencia a chave primária de outra. É assim que os relacionamentos entre tabelas são expressos. Por exemplo, uma tabela orders pode ter uma coluna customer_id que referencia customers.id. O banco de dados pode impor esse vínculo, prevenindo registros órfãos. Consulte a documentação do PostgreSQL sobre constraints de chave estrangeira para um exemplo concreto.
Modelando Relacionamentos: Um-para-Muitos e Muitos-para-Muitos
O relacionamento mais comum no design de banco de dados relacional é um-para-muitos: um cliente tem muitos pedidos, um autor tem muitas postagens. Você modela isso colocando a chave estrangeira no lado “muitos”.
Relacionamentos muitos-para-muitos — como estudantes matriculados em cursos — exigem uma tabela de junção (também chamada de tabela associativa ou de ponte). Em vez de tentar armazenar múltiplos valores em uma única coluna, você cria uma terceira tabela (enrollments) com chaves estrangeiras apontando tanto para students quanto para courses. Isso mantém o schema limpo e consultável.

Discover how at OpenReplay.com.
Normalização de Banco de Dados Explicada
Normalização de banco de dados é o processo de estruturar tabelas para reduzir redundância e prevenir anomalias de dados. As três formas normais mais práticas são:
- 1FN (Primeira Forma Normal): Cada célula contém um valor — sem listas separadas por vírgula, sem grupos de colunas repetidas
- 2FN (Segunda Forma Normal): Cada coluna não-chave depende da chave primária inteira, não apenas de parte dela (isso se aplica principalmente a tabelas com chaves primárias compostas)
- 3FN (Terceira Forma Normal): Colunas não-chave dependem apenas da chave primária — não umas das outras
Normalização é uma diretriz, não uma lei. Schemas altamente normalizados são mais fáceis de manter, mas podem exigir mais joins. Algumas equipes intencionalmente desnormalizam tabelas específicas para cargas de trabalho com muitas leituras. O equilíbrio certo depende dos seus padrões de consulta e requisitos de desempenho. Uma visão geral mais detalhada da teoria por trás da normalização de banco de dados está disponível na Wikipedia.
Impondo Integridade com Constraints
Validação apenas no nível da aplicação não é suficiente. Se múltiplos serviços escrevem no seu banco de dados, ou alguém executa uma consulta SQL direta, suas verificações no lado da aplicação são totalmente contornadas. Constraints de banco de dados são sua última linha de defesa:
PRIMARY KEY— impõe unicidade e não-nulidade no identificadorFOREIGN KEY— garante que as linhas referenciadas realmente existemUNIQUE— previne valores duplicados em uma coluna (útil para emails, nomes de usuário)NOT NULL— previne valores ausentes onde um campo é obrigatórioCHECK— valida que um valor atende a uma condição (ex.:price > 0)
A maioria dos bancos de dados SQL modernos também suporta colunas geradas — valores computados automaticamente a partir de outras colunas — que podem reduzir lógica redundante na camada de aplicação. As implementações variam entre os motores (PostgreSQL, MySQL, SQL Server cada um lida com isso de forma diferente), mas o conceito está amplamente disponível. Por exemplo, o PostgreSQL documenta colunas geradas em sua documentação oficial.
Um Exemplo Prático de Schema
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);Este exemplo usa sintaxe SQL no estilo PostgreSQL. Ele impõe integridade referencial, previne emails nulos e valida que os totais dos pedidos são não-negativos — tudo no nível do banco de dados.
Note que GENERATED ALWAYS AS IDENTITY é SQL padrão (suportado no PostgreSQL 10+, Oracle 12c+ e DB2). Se você estiver usando MySQL, usaria AUTO_INCREMENT em vez disso. No SQL Server, o equivalente é IDENTITY(1,1). Consulte a documentação do PostgreSQL sobre colunas de identidade para detalhes.
Conclusão
Um bom design de banco de dados relacional se resume a uma ideia: cada tabela deve representar uma coisa, e cada pedaço de dado deve existir em exatamente um lugar. Aplique isso consistentemente, use constraints para impor como os dados devem ser, e seu schema permanecerá manutenível à medida que sua aplicação cresce. Os princípios abordados aqui — chaves primárias e estrangeiras, normalização, modelagem de relacionamentos e imposição de constraints — formam a fundação sobre a qual todo banco de dados confiável é construído.
Perguntas Frequentes
Use UUIDs quando os registros são gerados em múltiplos bancos de dados ou serviços que precisam se mesclar sem colisões de chaves. Inteiros auto-incrementais são mais simples, menores em armazenamento e mais rápidos para indexação. Para a maioria das aplicações com banco de dados único, inteiros funcionam bem. Escolha UUIDs quando precisar de identificadores globalmente únicos em arquiteturas distribuídas ou multi-tenant.
Comece com a terceira forma normal (3FN) como sua linha de base. Se cada coluna não-chave depende exclusivamente da chave primária e você não tem dados repetidos entre linhas, está em boa forma. Se as consultas ficarem muito lentas devido a joins excessivos, considere desnormalização seletiva em tabelas específicas com muitas leituras, em vez de abandonar completamente a normalização.
Sem constraints de chave estrangeira, o banco de dados não pode prevenir registros órfãos. Você pode acabar com pedidos referenciando clientes que não existem mais, ou linhas de matrícula apontando para cursos deletados. O código da aplicação pode perder casos extremos, especialmente quando múltiplos serviços ou consultas manuais modificam dados. Chaves estrangeiras capturam esses problemas no nível do banco de dados.
Sim, desnormalização deliberada é uma prática comum e válida para cargas de trabalho com muitas leituras. O segredo é fazê-lo intencionalmente e documentar as compensações. Tabelas desnormalizadas são mais rápidas para consultar, mas mais difíceis de manter porque atualizações devem se propagar para dados duplicados. Use seletivamente onde o desempenho de consulta exige, não como uma escolha de design padrão.
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..


