
Como Fazer Streaming de Dados para o Navegador com Fetch

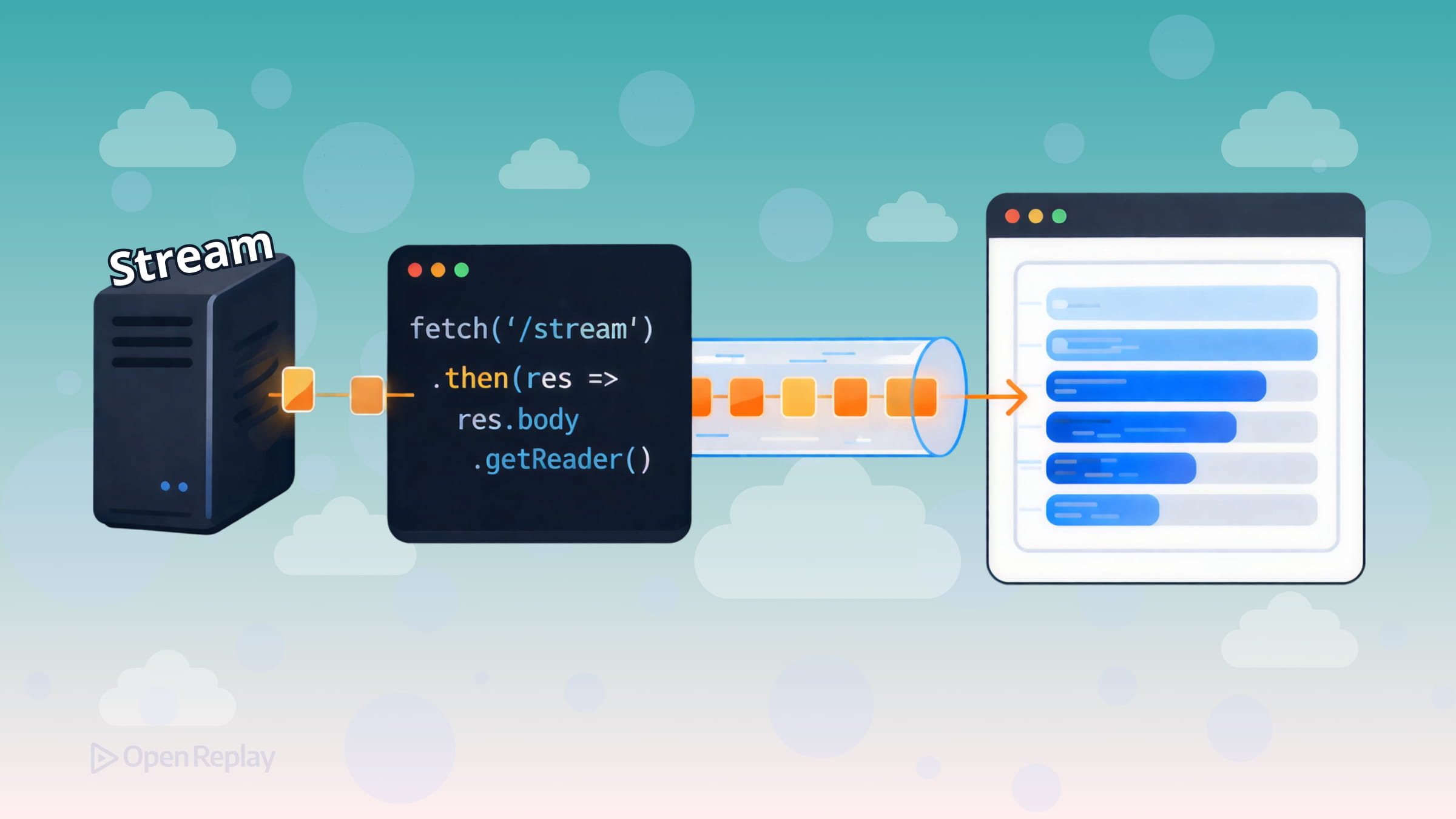
A maioria dos tutoriais sobre a API Fetch mostra o mesmo padrão: chamar fetch(), aguardar a resposta, chamar .json() ou .text(), pronto. Isso funciona bem para payloads pequenos. Mas quando seu servidor está gerando dados progressivamente—pense em respostas de IA, logs ao vivo ou grandes conjuntos de dados—esperar pela resposta completa antes de tocar em um único byte é um problema real.
A boa notícia: a API Fetch já suporta streaming incremental de dados no navegador. Veja como usá-la.
Principais Conclusões
- O
response.bodyda API Fetch expõe umReadableStream, permitindo que você processe dados fragmento por fragmento conforme chegam, em vez de esperar pelo payload completo. - Use
response.body.getReader()com umTextDecoderpara a compatibilidade mais ampla entre navegadores ao ler respostas em streaming. - Os fragmentos de rede não respeitam limites de mensagem—você deve bufferizar e dividir linhas incompletas manualmente ao analisar formatos estruturados como JSON delimitado por linha.
- Sempre combine streams de longa duração com um
AbortControllerpara que você possa cancelar requisições de forma limpa quando os usuários navegarem para outra página.
Por Que Streaming de Respostas com a API Fetch É Importante
Quando você chama response.json() ou response.text(), o navegador deve receber todo o corpo da resposta antes de resolver a promise. Para um arquivo de log de 50MB ou um endpoint lento de completação de IA, isso significa que sua aplicação não pode processar ou renderizar nenhuma parte da resposta até que o último byte chegue.
O streaming permite que você processe dados conforme chegam—exibindo o primeiro fragmento aos usuários enquanto o restante ainda está em trânsito. Essa é uma melhoria significativa na performance percebida.
Como Funciona a API Fetch com ReadableStream
Toda resposta do fetch() expõe um ReadableStream em response.body. Em vez de esperar pelo payload completo, você anexa um reader e extrai fragmentos conforme eles saem da rede.
A abordagem mais amplamente compatível é response.body.getReader():
const response = await fetch('/api/stream')
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`)
}
const reader = response.body.getReader()
const decoder = new TextDecoder()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(decoder.decode(value, { stream: true }))
}Cada value é um Uint8Array de bytes brutos. O TextDecoder converte esses bytes em uma string. Passe { stream: true } para que o decoder manipule corretamente caracteres multi-byte que podem estar divididos entre limites de fragmentos.
Nota sobre iteração assíncrona: Você pode ter visto
for await (const chunk of response.body). Essa sintaxe é mais limpa, mas não é suportada no Safari a partir da versão 18.x, então o loop comgetReader()acima é a escolha mais segura para produção. Veja o suporte atual dos navegadores em https://caniuse.com/wf-async-iterable-streams.
Decodificando Streams de Texto com TextDecoderStream
Se você prefere uma abordagem estilo pipeline, TextDecoderStream manipula a decodificação automaticamente:
const response = await fetch('/api/stream')
const reader = response.body
.pipeThrough(new TextDecoderStream())
.getReader()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(value) // já é uma string
}Isso fica mais limpo ao encadear múltiplas etapas de transformação.

Discover how at OpenReplay.com.
Considerações Práticas para Streaming no Navegador com Fetch
Os limites de fragmentos são arbitrários. Fragmentos de rede não se alinham com linhas ou mensagens. Se você está analisando JSON delimitado por linha ou eventos SSE, precisa bufferizar linhas incompletas e dividir em \n você mesmo.
Streams só podem ser consumidos uma vez. Anexar um reader com getReader() bloqueia o stream para aquele reader, e uma vez que qualquer dado tenha sido lido, o corpo fica perturbado e não pode ser consumido novamente. Se você precisa do corpo em dois lugares, chame response.clone() antes de ler:
const response = await fetch('/api/data')
const clone = response.clone()
// Leia o original como stream
const reader = response.body.getReader()
// Use o clone normalmente em outro lugar
const text = await clone.text()Cancele streams com AbortController. Streams de longa duração devem ser canceláveis—especialmente quando usuários navegam para outra página:
const controller = new AbortController()
const response = await fetch('/api/stream', {
signal: controller.signal
})
// Cancele quando necessário
controller.abort()Isso impede que o navegador continue recebendo dados que ninguém está lendo.
Conclusão
O streaming no navegador com Fetch é bem suportado e prático hoje em dia. O padrão central é direto: obtenha um reader de response.body, faça um loop com reader.read(), decodifique bytes com TextDecoder e manipule limites de fragmentos em seu próprio buffer. Adicione um AbortController para limpeza, e esteja atento ao fato de que corpos de resposta só podem ser consumidos uma vez quando você precisa dos dados em múltiplos lugares. Isso é tudo que você precisa para construir experiências de dados incrementais e responsivas no navegador.
Perguntas Frequentes
O streaming com Fetch funciona com qualquer método HTTP que retorna um corpo de resposta, incluindo POST, PUT e PATCH. O ReadableStream em response.body se comporta de forma idêntica independentemente do método usado. O servidor apenas precisa enviar uma resposta fragmentada ou em streaming para que a leitura incremental seja significativa.
Você precisa manter um buffer de string. Anexe cada fragmento decodificado ao buffer, depois divida nos caracteres de nova linha. Processe cada linha completa como JSON e mantenha o segmento incompleto final no buffer para o próximo fragmento. Isso leva em conta o fato de que fragmentos de rede podem dividir um objeto JSON em duas leituras.
Sim. Você pode consumir um endpoint SSE via streaming com Fetch analisando manualmente o formato text/event-stream dos fragmentos. Isso lhe dá mais controle sobre cabeçalhos, autenticação e métodos de requisição comparado à API EventSource, que suporta apenas requisições GET e oferece personalização limitada de cabeçalhos.
Se a conexão cair ou o stream apresentar erro, a promise retornada por reader.read() será rejeitada. Envolva seu loop de leitura em um bloco try-catch para que sua aplicação possa lidar com a falha de forma elegante, notificar o usuário ou tentar novamente a requisição se apropriado.
Complete picture for complete understanding
Capture every clue your frontend is leaving so you can instantly get to the root cause of any issue with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data.
Check our GitHub repo and join the thousands of developers in our community.
