
如何使用 Fetch 向浏览器流式传输数据

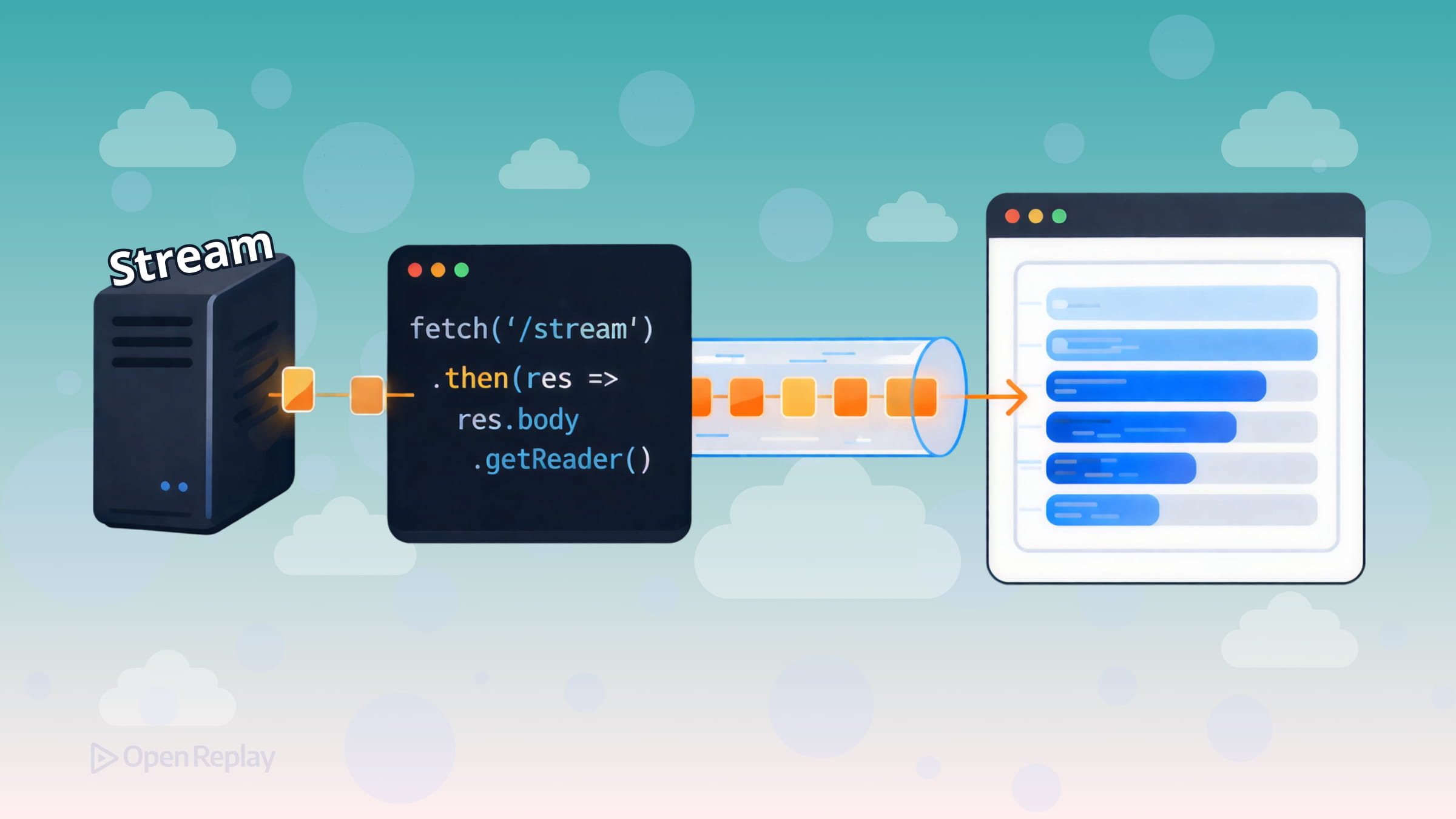
大多数 Fetch API 教程都展示相同的模式:调用 fetch(),等待响应,调用 .json() 或 .text(),完成。这对于小型负载来说没问题。但当你的服务器正在逐步生成数据时——比如 AI 响应、实时日志或大型数据集——在接触单个字节之前等待整个响应就成了一个真正的问题。
好消息是:Fetch API 已经在浏览器中支持增量数据流式传输。以下是使用方法。
核心要点
- Fetch API 的
response.body暴露了一个ReadableStream,让你可以在数据到达时逐块处理,而不是等待完整的负载。 - 在读取流式响应时,使用
response.body.getReader()配合TextDecoder可获得最广泛的浏览器兼容性。 - 网络块不遵守消息边界——在解析换行符分隔的 JSON 等结构化格式时,你必须自己缓冲和拆分不完整的行。
- 始终为长时间运行的流配对
AbortController,以便在用户离开页面时能够干净地取消请求。
为什么使用 Fetch API 流式响应很重要
当你调用 response.json() 或 response.text() 时,浏览器必须接收整个响应体才能解析 promise。对于 50MB 的日志文件或缓慢的 AI 补全端点,这意味着你的应用程序在最后一个字节到达之前无法处理或渲染任何响应。
流式传输让你可以在数据到达时就进行处理——在其余部分仍在传输时就向用户显示第一个块。这是感知性能上的显著改进。
ReadableStream Fetch API 的工作原理
每个 fetch() 响应都在 response.body 上暴露一个 ReadableStream。你不需要等待完整的负载,而是附加一个读取器并在数据从网络传来时拉取块。
最广泛兼容的方法是 response.body.getReader():
const response = await fetch('/api/stream')
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`)
}
const reader = response.body.getReader()
const decoder = new TextDecoder()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(decoder.decode(value, { stream: true }))
}每个 value 都是原始字节的 Uint8Array。TextDecoder 将这些字节转换为字符串。传递 { stream: true } 以便解码器正确处理可能跨块边界分割的多字节字符。
关于异步迭代的说明: 你可能见过
for await (const chunk of response.body)这种语法。这种语法更简洁,但截至 18.x 版本在 Safari 中不受支持,因此上面的getReader()循环是生产环境中更安全的选择。请在 https://caniuse.com/wf-async-iterable-streams 查看当前的浏览器支持情况。
使用 TextDecoderStream 解码文本流
如果你更喜欢管道式方法,TextDecoderStream 可以自动处理解码:
const response = await fetch('/api/stream')
const reader = response.body
.pipeThrough(new TextDecoderStream())
.getReader()
while (true) {
const { value, done } = await reader.read()
if (done) break
console.log(value) // 已经是字符串
}当链接多个转换步骤时,这种方式更简洁。

Discover how at OpenReplay.com.
使用 Fetch 进行浏览器流式传输的实际注意事项
块边界是任意的。 网络块不会与行或消息对齐。如果你正在解析换行符分隔的 JSON 或 SSE 事件,你需要缓冲不完整的行并自己按 \n 分割。
流只能被消费一次。 使用 getReader() 附加读取器会将流锁定到该读取器,一旦读取了任何数据,响应体就会变为已扰动状态,无法再次消费。如果你需要在两个地方使用响应体,在读取之前调用 response.clone():
const response = await fetch('/api/data')
const clone = response.clone()
// 将原始响应作为流读取
const reader = response.body.getReader()
// 在其他地方正常使用克隆
const text = await clone.text()使用 AbortController 取消流。 长时间运行的流应该是可取消的——特别是当用户离开页面时:
const controller = new AbortController()
const response = await fetch('/api/stream', {
signal: controller.signal
})
// 需要时取消
controller.abort()这可以防止浏览器继续接收无人读取的数据。
结论
使用 Fetch 进行浏览器流式传输在今天得到了良好支持且实用。核心模式很简单:从 response.body 获取读取器,使用 reader.read() 循环,用 TextDecoder 解码字节,并在自己的缓冲区中处理块边界。添加 AbortController 进行清理,并注意当你需要在多个地方使用数据时,响应体只能被消费一次。这就是在浏览器中构建响应式、增量数据体验所需的一切。
常见问题
Fetch 流式传输适用于任何返回响应体的 HTTP 方法,包括 POST、PUT 和 PATCH。无论使用哪种方法,response.body 上的 ReadableStream 行为都是相同的。服务器只需要发送分块或流式响应,增量读取才有意义。
你需要维护一个字符串缓冲区。将每个解码的块追加到缓冲区,然后按换行符分割。将每个完整的行作为 JSON 处理,并将尾部不完整的片段保留在缓冲区中以供下一个块使用。这是因为网络块可能会在两次读取之间分割一个 JSON 对象。
可以。你可以通过手动从块中解析 text/event-stream 格式,使用 Fetch 流式传输来消费 SSE 端点。与 EventSource API 相比,这为你提供了对标头、身份验证和请求方法的更多控制,而 EventSource 仅支持 GET 请求并提供有限的标头自定义。
如果连接断开或流出错,reader.read() 返回的 promise 将被拒绝。将你的读取循环包装在 try-catch 块中,以便你的应用程序可以优雅地处理失败、通知用户或在适当时重试请求。
Complete picture for complete understanding
Capture every clue your frontend is leaving so you can instantly get to the root cause of any issue with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data.
Check our GitHub repo and join the thousands of developers in our community.
