
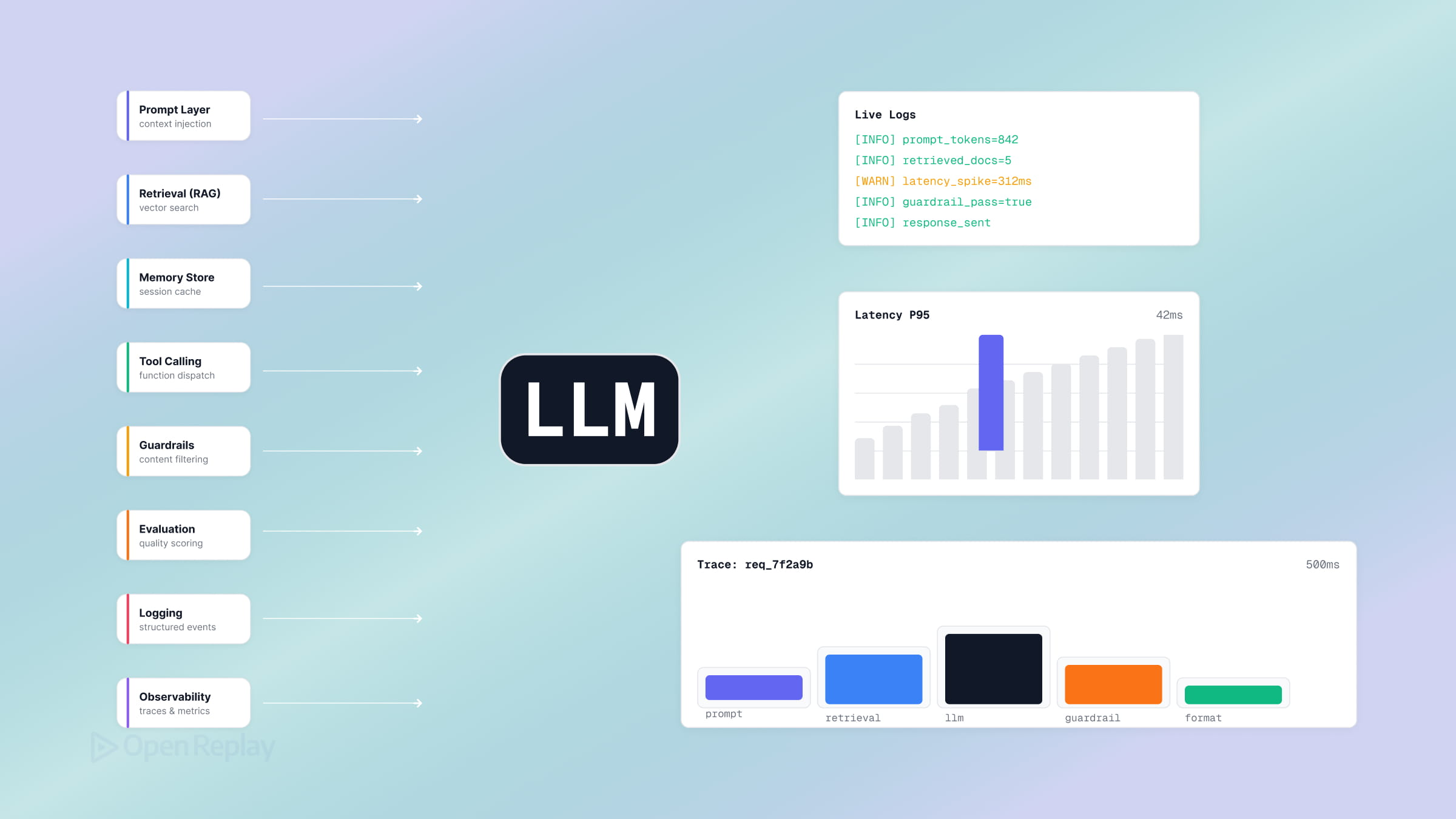
Harness(执行框架)是指除模型本身之外的所有代码、配置和执行逻辑——包括编排循环、工具、内存、上下文管理、状态、错误处理、防护栏以及验证检查,这些共同决定了一个智能体能否成功完成任务。如果你曾使用 OpenAI 或 Anthropic SDK 发布过 LLM 功能,并目睹它陷入循环、产生幻觉式工具调用,或者忘记用户三轮前说过的话,那你已经触及了”薄 harness”的极限——而大多数时候,问题并不出在模型上。
本文将为你提供一个关于 harness 的精确心智模型、证明其对结果差异的影响远超模型选择的实证依据、一段可完整阅读的可运行 JS/TS harness 示例,以及前端团队在发布产品内 AI 功能时实际需要掌控的四项决策。
核心要点
- Harness 是除模型本身之外的所有代码、配置和执行逻辑;LangChain 的 Vivek Trivedy 将其概括为:“凡不是模型的,皆是 harness。”
- Vercel 的 v0 团队删除了其智能体 80% 的工具,任务成功率从 80% 攀升至 100%,平均 token 用量下降 37%——模型未做任何改动。
- 在 Princeton HAL 的 CORE-Bench Hard 排行榜上,Claude Opus 4.5 使用 CORE-Agent 得分为 42.22%,使用 Claude Code 则达到 77.78%——同一模型因脚手架不同产生了 35.56 个百分点的差距。
- Harness 与模型孰优孰劣的争论尚无定论:Scale AI 的 SWE-Atlas 显示脚手架效果因模型而异,而 METR 发现在时间跨度评估中,Claude Code 和 Codex 相比其自有默认脚手架并无统计显著优势。
- 每个 harness 在向用户返回输出之前,都至少需要一项确定性检查——测试、schema 验证器或正则表达式。
什么是智能体 harness?
智能体 harness 是包裹 LLM 调用的完整软件系统:决定何时调用模型的编排循环、模型可调用的工具、模型所能访问的内存与上下文、跨轮次携带的状态,以及对输出进行把关的防护栏和验证检查。这一概念的经典表述来自 LangChain 的 Vivek Trivedy:“凡不是模型的,皆是 harness。“模型负责生成 token;harness 则是将这些 token 转化为可靠功能的一切。
理解两者关系最清晰的心智模型,来自 Beren Millidge 2023 年的文章——将脚手架化 LLM 系统类比为自然语言计算机:LLM 对应 CPU,提示词和上下文窗口对应 RAM(速度快但容量有限),向量数据库等外部内存对应磁盘存储。工具充当连接外部世界的设备驱动程序,而 harness 则是协调一切的操作系统。没有操作系统的 CPU 无法完成任何有意义的计算。模型是必要条件,但并非充分条件。
这一领域的术语较为混乱,在此统一厘清。模型是 LLM——权重加 API。Harness(有时也称 scaffold,即脚手架)是围绕模型的外围代码。智能体是涌现出的行为:一个用户所交互的、具有目标导向性、能使用工具并能自我纠错的实体。Hugging Face Agents Course 将智能体定义为:使用 AI 模型与其环境交互、以实现用户定义目标的系统。当有人说”我构建了一个智能体”,他们实际上是构建了一个 harness,并将其指向了某个模型。Anthropic 在其 Claude Agent SDK 发布公告中也将 Claude Code SDK 描述为”驱动 Claude Code 的智能体 harness”。
为什么封装层比模型本身更重要?

Discover how at OpenReplay.com.
封装层之所以比模型更重要,是因为同一个模型在不同的 harness 背后会产生截然不同的结果——而且这种差距是显著的、可重复的,并已在公开基准测试中得到验证。最有力的单一数据点来自:Vercel 的 v0 团队删除了其智能体 80% 的工具,随后任务成功率从 80% 攀升至 100%,平均 token 用量下降 37%,一个最坏情况的查询耗时从 724 秒降至 141 秒——模型未做任何改动。这一改进完全来自 harness 层面:更少、范围更精准的工具。
另外两项结果也指向同一方向。据 LangChain 自身的报告,该公司仅通过修改 harness(模型不变)就将其编程智能体在 Terminal-Bench 2.0 上的排名从 30 名开外提升至前五。在 Princeton HAL 的 CORE-Bench Hard 排行榜上,Claude Opus 4.5 使用 CORE-Agent 脚手架得分为 42.22%,使用 Claude Code 则达到 77.78%——同一模型因脚手架不同产生了 35.56 个百分点的差距,排行榜同时报告 Claude Code 运行在人工验证下达到了 95.5%。
| 研究 | 模型是否改变? | Harness 是否改变? | 改变前 | 改变后 |
|---|---|---|---|---|
| Vercel v0 | 否 | 是(减少 80% 工具) | 成功率 80% | 成功率 100%,token 减少 37% |
| LangChain / Terminal-Bench 2.0 | 否 | 是 | 30 名开外 | 前 5 名 |
| Princeton CORE-Bench Hard | 否(Opus 4.5) | 是(脚手架) | 42.22% | 77.78% |
这场争论尚无定论,过度简化只会损害可信度。Scale AI 的 SWE-Atlas 将第一方编程智能体脚手架与极简的 mini-SWE-agent 进行了对比,结果显示脚手架效果因模型而异,原生脚手架相比极简基线有显著提升。与此同时,METR 发现在时间跨度评估中,Claude Code 和 Codex 相比其自有默认脚手架并无统计显著优势。两种效应都真实存在;哪种占主导取决于具体任务场景。正如 MongoDB 所言,诚实的解读是”LLM 是其中最小的部分”——但 harness 带来的收益并非无上限,强模型在弱任务上依然会制约脚手架所能弥补的空间。
LLM harness 由哪些组件构成?
一个生产级 harness 可分解为八个组件,每个组件都是薄封装层可能失效的环节:编排循环、工具、内存、上下文管理、提示词构建、状态、错误处理,以及防护栏与验证循环。
编排循环。 循环实现了”思考—行动—观察”周期(即 ReAct 模式):调用模型,检查其是否请求了工具,执行工具,将结果反馈回去,循环往复,直到模型给出答案或触发防护条件。正如 Vikash Rungta 对 Claude Code 的逆向工程分析所指出的,运行时是一个”哑循环”,所有智能都存在于模型中,harness 只负责管理轮次。从机制上看,它就是一个带有轮次上限的 while 循环。
工具。 工具是智能体的”双手”——以 schema(名称、描述、参数类型)的形式暴露给模型的函数。工具层负责注册、参数验证、执行,以及将结果格式化为模型可读的观察内容。帮助组件中的 search_docs 工具是一个工具,get_order_status 也是。
内存。 短期内存是当前对话;长期内存跨会话持久化。在聊天组件中,短期内存是每轮重放的消息数组;长期内存可能是在会话开始时加载的每用户摘要。
上下文管理。 稀缺资源是上下文窗口,失效模式是”上下文腐化”——当窗口被低信噪比的 token 填满时,质量会下降。根据 Anthropic 的上下文工程指南,目标是使用最小集合的高信噪比 token。常用策略包括:压缩(对旧轮次进行摘要)和即时检索(按需获取,而非预先加载)。
提示词构建。 Harness 按层级组装输入:系统提示词、工具定义、内存、对话历史、当前消息。顺序至关重要;重要上下文应置于窗口的开头和结尾。
状态。 状态是跨轮次和崩溃后仍能保留的内容——智能体在多步骤任务中的位置、中间输出、检查点。一个”遗忘”了用户早先约束条件的聊天组件,存在的是状态和上下文管理问题,而非模型问题。
错误处理。 一个 10 步任务在每步成功率 99% 的情况下,端到端成功率仅约 90%,因为错误会累积。关键模式是:将工具错误作为观察内容返回给模型,让其自我纠错,而不是抛出异常终止运行。
防护栏与验证循环。 防护栏约束智能体的行为边界;验证循环检查其产出结果。Martin Fowler / Birgitta Böckeler 的 harness 工程文章将验证分为两类:引导(feedforward——在行动前引导)和传感(feedback——观察并自我纠正),并按计算型(确定性:测试、linter)和推断型(LLM 作为评判者)控制进一步细分。
如何用 JavaScript 构建一个智能体 harness?
一个最小化但完整的 harness 包含:带轮次上限的 ReAct 循环、一个范围精准的工具、一个将错误作为观察内容的处理器,以及一项确定性验证检查。以下示例使用 Anthropic SDK 和 Zod 进行 schema 验证。验证检查是大多数薄封装层所跳过的部分——没有它,智能体就无从知晓自己出了错。
import Anthropic from "@anthropic-ai/sdk";
import { z } from "zod";
const client = new Anthropic();
// 单一工具,范围精准。工具越少 = 误调用越少。
const tools: Anthropic.Tool[] = [
{
name: "get_order_status",
description: "Look up the status of an order by its numeric ID.",
input_schema: {
type: "object",
properties: { orderId: { type: "number" } },
required: ["orderId"],
},
},
];
// 确定性验证:模型的工具输入必须符合此 schema。
const OrderArgs = z.object({ orderId: z.number().int().positive() });
async function runOrder(orderId: number) {
// 真实查询的占位实现。
return { orderId, status: "shipped", eta: "2026-03-04" };
}
export async function harness(userMessage: string) {
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: userMessage },
];
// 最大轮次防护:防止循环的最重要安全栏。
for (let turn = 0; turn < 6; turn++) {
const res = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: "You are an order-status assistant. Use tools when asked about orders.",
tools,
messages,
});
const toolUse = res.content.find(
(b): b is Anthropic.ToolUseBlock => b.type === "tool_use"
);
if (!toolUse) return res.content; // 无工具调用 → 模型已直接给出答案。
messages.push({ role: "assistant", content: res.content });
let observation: string;
const parsed = OrderArgs.safeParse(toolUse.input);
if (!parsed.success) {
// 验证失败:将错误作为观察内容返回,而非抛出异常。
observation = `Invalid arguments: ${parsed.error.message}`;
} else {
try {
observation = JSON.stringify(await runOrder(parsed.data.orderId));
} catch (e) {
observation = `Tool error: ${(e as Error).message}`; // 同样作为观察内容
}
}
messages.push({
role: "user",
content: [{ type: "tool_result", tool_use_id: toolUse.id, content: observation }],
});
}
return [{ type: "text", text: "Could not complete the request." }];
}这约 50 行代码中的四个设计选择承载了大部分可靠性。带轮次上限的 for 循环既是编排循环,也是防循环的防护栏。单一工具保持了工具 schema 的精简。Zod 的 safeParse 是确定性验证检查,在幻觉参数到达后端之前将其拦截。验证失败和运行时错误都作为观察内容返回,而非抛出异常——这样模型就能自我纠正,而不是让整个运行崩溃。Anthropic 的工具使用机制详见工具使用指南;使用 OpenAI SDK 的等效循环则使用 tool_calls 和 role: "tool" 消息。
为什么前端开发者拥有的 harness 控制权比他们意识到的更多?
每当前端开发者发布 AI 聊天组件、产品内搜索助手或副驾驶 UI 时,他们就已经在掌管一个 harness——只是比智能体类型的 harness 更薄而已。用户抱怨的大多数问题(循环、幻觉式工具调用、上下文丢失、约束被忽略)都是 harness 问题,而非模型问题。当前端团队发布 AI 功能时,模型选择只是众多决策之一,而 harness 决策——工具范围、携带哪些上下文、验证什么——通常得到的设计审查远少于其应有的重视。
这种对应关系是直接的。用户看到助手”重新生成”同样错误答案,是在目睹一个没有验证的编排循环。用户发现两轮后其声明的约束条件消失,是在目睹状态和上下文管理的缺口。工具调用携带垃圾参数触发并返回令人困惑的回复,是缺少 schema 检查——正是上面的 safeParse 步骤。这些问题没有一个能通过换模型来解决。它们都需要通过收紧你已经掌控的封装层来修复。
Harness 应该有多厚?前端团队需要掌控的四项决策
前端团队在发布产品内 AI 功能时,实际上控制着四项 harness 决策:工具范围界定、上下文策略、验证循环,以及 harness 厚度。更广泛的领域级清单——单智能体 vs. 多智能体、ReAct vs. 计划-执行模式、权限管理、持久化执行、集群治理——属于大多数聊天组件永远不会触及的基础设施层。
-
工具范围界定——从不超过 10 个工具开始,谨慎扩展。 给智能体配备超出需要的工具会可靠地降低性能,因为每个额外的工具 schema 都会消耗上下文,并提高误调用的概率。Vercel 的结果是最有力的证据:删除 80% 的工具改善了所有指标。
-
上下文策略——优先使用压缩和即时检索,而非填塞窗口。 不要将整个知识库预加载到提示词中。在接近窗口上限时对旧轮次进行摘要,并按需获取文档。Anthropic 的上下文工程指南将目标定义为最小化的高信噪比 token 集合。
-
验证循环——每个 harness 在向用户返回输出之前,至少需要一项确定性检查。 schema 验证器、正则表达式、单元测试——某种 harness 可以独立运行、不依赖模型自身判断的检查机制。没有它,智能体就无从知晓自己出了错。根据 Böckeler 的计算型/推断型划分,从低成本的计算型检查开始;仅在需要语义正确性时才引入 LLM 作为评判者。
-
Harness 厚度——从薄开始,仅在某种失效模式反复出现时才增加结构。 不要为尚未遇到的失效情况预先构建编排逻辑。当某个具体问题出现超过一次时,再添加重试、防护栏或验证步骤。
在生产环境中观看 AI 功能的会话回放,是通过用户行为快速判断 harness 质量的最有效方式之一,因为诊断特征无需任何模型层面的遥测数据即可显现。用户反复用不同措辞提出同一请求,意味着上下文丢失或验证循环从未触发。在多步骤任务中途放弃,往往可追溯到一个被吞掉的工具错误以模糊回复的形式呈现。复制后再编辑的行为意味着验证缺口——输出通过了 harness 的检查,却未能满足用户的需求。反复点击”重新生成”或”再试一次”,是 harness 陷入循环且无法检测自身失效状态的典型特征。
Harness 设计的未来走向
模型现在已在 harness 参与的循环中进行后训练——正如 LangChain 在其智能体 harness 架构讨论中所指出的,Claude Code 和 Codex 等产品将模型训练与 harness 设计结合在一个反馈循环中——这意味着 harness 不再是一个可替换的封装层,而是产品表面协同演化的一部分。对构建者而言,这意味着 harness 正在成为你所设计的产品的一部分,而非一个可以在不同模型间无缝迁移的通用适配器。
这给了你一个清晰的面向未来的测试标准,源自脚手架的比喻:如果你的设计能随着更强的模型干净地扩展——相同的 harness,更好的结果——那它是健全的。如果随着模型能力的提升,它反而需要更多脚手架来弥补,那这个 harness 正在掩盖一个你应该在别处解决的模型或任务问题。脚手架,就像建筑工地上的那种,本就是在结构能够自立时拆除的。
下次当你的 AI 功能陷入循环、遗忘上下文或自信地返回错误结果时,先审查 harness,再审查模型。从上述四项决策入手——工具范围、上下文策略、一项确定性检查、以及 harness 厚度——并添加能让失效不再反复出现的最小结构量。
常见问题
Harness 和 scaffold 有什么区别?
这两个术语在实践中可互换使用,都指围绕模型的、除模型本身之外的所有代码、配置和执行逻辑。'Scaffold'(脚手架)在基准测试文献中更为常见,例如 Princeton 的 CORE-Agent 与 Claude Code scaffold 对比;而'harness'则在生产环境和 SDK 语境中更受青睐。LangChain 的 Vivek Trivedy 用一条规则消弭了两者的区别:凡不是模型的,皆是 harness。
在 harness 中应该将工具错误返回给模型,还是直接抛出异常?
应将错误作为观察内容返回给模型,而非抛出异常。抛出异常会终止整个运行;将错误作为工具结果返回,能让模型看到出了什么问题,并在下一轮自我纠正。这一点至关重要,因为错误在多步骤任务中会累积——一个 10 步任务在每步成功率 99% 的情况下,端到端成功率仅约 90%。schema 验证失败和运行时异常都应被捕获并作为观察内容反馈,绝不应作为未处理的异常抛出。
增加更多工具能提升智能体性能吗?
不能,超过一定数量后,增加工具会可靠地降低性能。每个工具 schema 都会消耗上下文窗口的 token,并增加误调用或错误调用的概率。Vercel 的 v0 团队删除了其智能体 80% 的工具,在同一模型上任务成功率从 80% 攀升至 100%,平均 token 用量下降 37%。实践原则是:从不超过 10 个工具开始,仅在出现真实需求缺口时才扩展。
我可以在不做任何修改的情况下,在同一个 harness 中替换不同的模型吗?
越来越难了。正如 LangChain 在其智能体 harness 架构讨论中所指出的,Claude Code 和 Codex 等产品将模型训练与 harness 设计结合在一个反馈循环中。这使得 harness 成为产品表面协同演化的一部分,而非通用适配器。一个有用的面向未来的测试标准是:你的设计能否随着更强的模型在同一 harness 上干净地扩展;如果随着模型能力的提升,它反而需要更多脚手架来弥补,那这个 harness 正在掩盖一个更深层的问题。


