
关系型数据库设计基础

大多数数据库问题不是由糟糕的查询引起的——而是由糟糕的模式(schema)引起的。如果你的表从一开始就结构不良,再巧妙的 SQL 也无法完全弥补。本文涵盖了关系型数据库设计的核心原则:如何构建表结构、定义键、建立关系模型,以及使用约束来保持数据的可靠性。
核心要点
- 关系型数据库通过键来链接表中存储的数据,而不是在表之间复制信息
- 主键(Primary Key)唯一标识行;外键(Foreign Key)表达表之间的关系
- 一对多关系在”多”的一方使用外键,而多对多关系需要一个中间表(junction table)
- 规范化(1NF、2NF、3NF)减少冗余并防止数据异常,尽管有时需要有意进行反规范化
- 数据库约束(
PRIMARY KEY、FOREIGN KEY、UNIQUE、NOT NULL、CHECK)是数据完整性的最后一道防线
什么是关系型数据库
关系型数据库将数据存储在**表(table)中——由行和列组成的结构化网格。每个表代表单一主题或实体,如 users、orders 或 products。每行(row)是一条记录。每列(column)**是该记录的一个属性。
关系模型的强大之处在于通过链接表而不是在表之间复制数据。这个概念源自 Edgar F. Codd 在 1970 年提出的关系模型,该模型至今仍是现代 SQL 数据库的理论基础。
主键和外键:关系型模式的基础
每个表都需要一个主键(primary key)——唯一标识每一行的一列(或多列组合)。一个好的主键应该是:
- 在所有行中唯一
- 永不为空(null)
- 稳定——分配后不应更改
大多数现代 SQL 数据库支持标识列(identity column)(自增整数),可以自动生成唯一标识符。许多系统还支持基于 UUID 的键,通常通过内置的数据库函数或默认值生成。两者都是有效的选择,取决于你的使用场景。自增整数简单高效。UUID 更适合分布式系统,其中多个数据源独立生成记录。
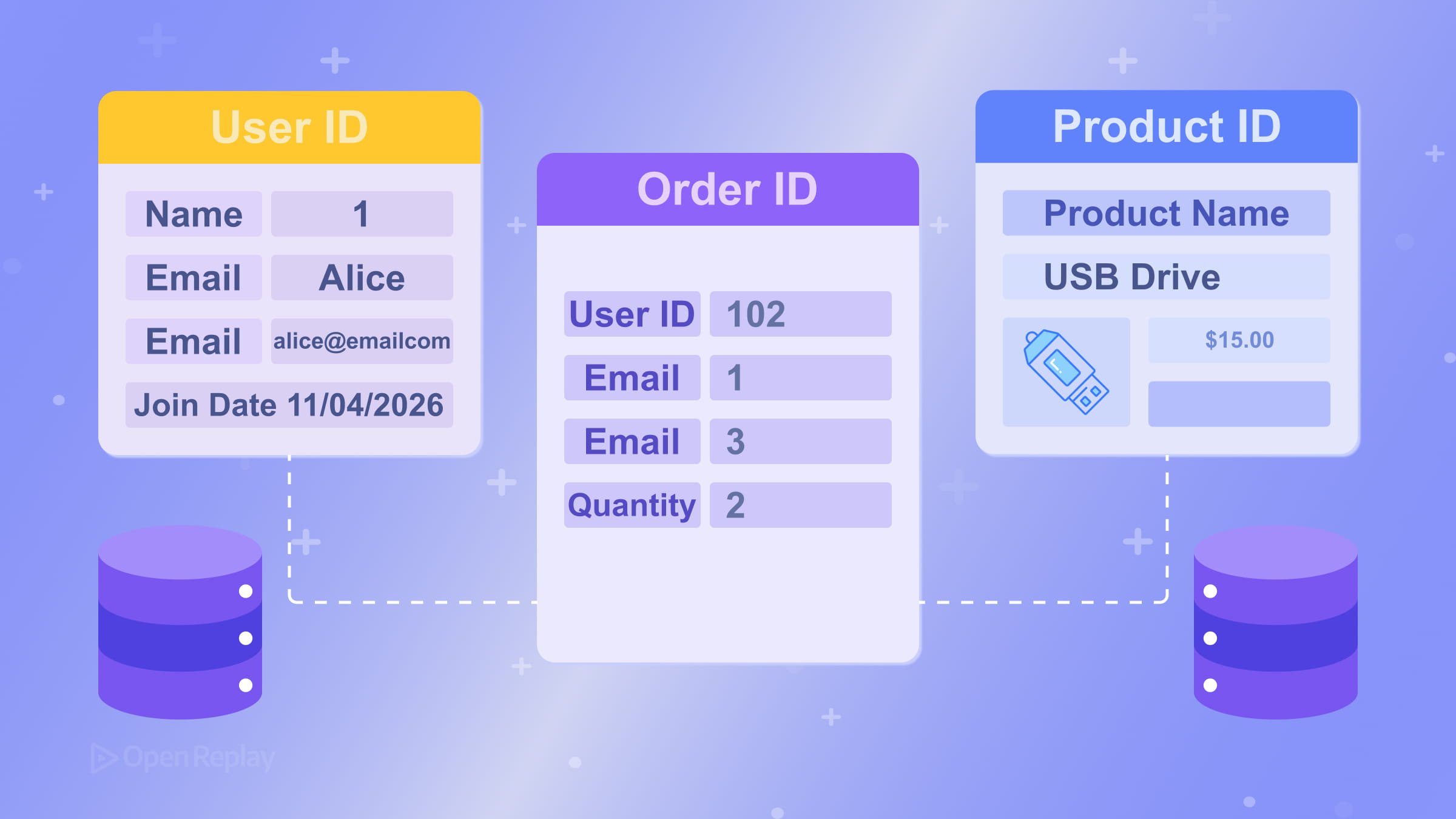
**外键(foreign key)**是一个表中引用另一个表主键的列。这是表之间关系的表达方式。例如,orders 表可能有一个 customer_id 列,引用 customers.id。数据库可以强制执行这种链接,防止出现孤立记录。具体示例请参见 PostgreSQL 外键约束文档。
关系建模:一对多和多对多
关系型数据库设计中最常见的关系是一对多(one-to-many):一个客户有多个订单,一个作者有多篇文章。你可以通过在”多”的一方放置外键来建立这种模型。
多对多(many-to-many)关系——如学生选修课程——需要一个中间表(junction table)(也称为关联表或桥接表)。与其试图在单个列中存储多个值,不如创建第三个表(enrollments),其中包含指向 students 和 courses 的外键。这样可以保持模式清晰且易于查询。

Discover how at OpenReplay.com.
数据库规范化详解
**数据库规范化(database normalization)**是构建表结构以减少冗余和防止数据异常的过程。三种最实用的范式是:
- 1NF(第一范式):每个单元格只保存一个值——没有逗号分隔的列表,没有重复的列组
- 2NF(第二范式):每个非键列依赖于整个主键,而不仅仅是其中一部分(这主要适用于具有复合主键的表)
- 3NF(第三范式):非键列仅依赖于主键——而不是相互依赖
规范化是一个指导原则,而不是法律。高度规范化的模式更易于维护,但可能需要更多的连接(join)操作。一些团队会有意对特定表进行反规范化(denormalize),以应对读取密集型工作负载。正确的平衡取决于你的查询模式和性能要求。关于数据库规范化背后理论的更详细概述可以在维基百科上找到。
使用约束强制完整性
仅靠应用层验证是不够的。如果多个服务写入你的数据库,或者有人运行直接的 SQL 查询,你的应用端检查就会被完全绕过。**数据库约束(database constraints)**是你数据完整性的最后一道防线:
PRIMARY KEY— 强制标识符的唯一性和非空FOREIGN KEY— 确保引用的行确实存在UNIQUE— 防止列中出现重复值(对电子邮件、用户名很有用)NOT NULL— 防止必填字段出现缺失值CHECK— 验证值是否满足条件(例如price > 0)
大多数现代 SQL 数据库还支持生成列(generated columns)——从其他列自动计算的值——这可以减少应用层中的冗余逻辑。不同数据库引擎的实现各不相同(PostgreSQL、MySQL、SQL Server 各有不同的处理方式),但这个概念是广泛可用的。例如,PostgreSQL 在其官方文档中记录了生成列。
实用模式示例
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);此示例使用 PostgreSQL 风格的 SQL 语法。它强制执行引用完整性,防止电子邮件为空,并验证订单总额为非负数——所有这些都在数据库层面完成。
请注意,GENERATED ALWAYS AS IDENTITY 是标准 SQL(在 PostgreSQL 10+、Oracle 12c+ 和 DB2 中支持)。如果你使用 MySQL,则应使用 AUTO_INCREMENT。在 SQL Server 中,等效语法是 IDENTITY(1,1)。详细信息请参见 PostgreSQL 关于标识列的文档。
结论
良好的关系型数据库设计归结为一个理念:每个表应该代表一件事,每条数据应该只存在于一个地方。始终如一地应用这一原则,使用约束来强制数据应该是什么样子,你的模式就会随着应用的增长而保持可维护性。本文涵盖的原则——主键和外键、规范化、关系建模和约束强制——构成了每个可靠数据库的基础。
常见问题
当记录在多个数据库或服务中生成,需要在不发生键冲突的情况下合并时,使用 UUID。自增整数更简单,存储空间更小,索引速度更快。对于大多数单数据库应用,整数效果很好。当你在分布式或多租户架构中需要全局唯一标识符时,选择 UUID。
以第三范式(3NF)作为基准。如果每个非键列仅依赖于主键,并且行之间没有重复数据,那么你的设计就是良好的。如果由于过多的连接导致查询速度过慢,可以考虑对特定的读取密集型表进行选择性反规范化,而不是完全放弃规范化。
没有外键约束,数据库无法防止孤立记录。你可能会遇到引用不再存在的客户的订单,或者指向已删除课程的选课记录。应用代码可能会遗漏边缘情况,特别是当多个服务或手动查询修改数据时。外键在数据库层面捕获这些问题。
是的,有意的反规范化是应对读取密集型工作负载的常见且有效的做法。关键是要有意识地这样做并记录权衡。反规范化的表查询速度更快,但更难维护,因为更新必须传播到重复的数据。在查询性能确实需要的地方有选择地使用它,而不是作为默认的设计选择。
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..
