7 Microservice Design Patterns to Use
Seven important patterns for modern web architecture


What is Microservice Architecture?
Microservice architecture is a collection of small services. All the components in this architecture are self-contained and wrap up around one business capability. Furthermore, it also refers to an architectural style for app development.
The microservice architecture enables a big app to be separated into smaller parts. And each part has its responsibility. Microservices, typically, are used to hasten app development. A perfect example of the microservices architecture is containers since they enable you to focus on services development without having to worry about dependencies.
The principles that microservice has been built include:
- Scalability
- Flexibility
- Independent and autonomous
- Decentralized governance
- Resiliency
- Failure isolation.
- Continuous delivery through the DevOps
In the following sections, we’ll discuss seven important patterns.
Saga pattern
This microservice design pattern provides transaction management using a sequence of local transactions. Each operation part of a saga guarantees that all operations are complete, or that the corresponding compensation transactions are run to undo the previously done work.
Furthermore, in Saga, a compensating transaction should be retriable and idempotent. The two principles ensure that transactions can be managed without manual intervention. The pattern is also a way of managing data consistency across microservices in distributed transaction instances. A saga is also a sequence of transactions that updates every service and publishes an event or message to trigger the next transaction step. Sagas can be achieved in two ways:
- Choreography - Each microservice produces and listens. Check out its example pattern below.
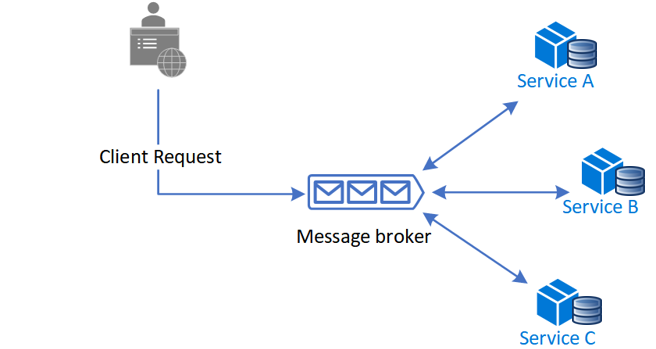
A diagram of how a Choreography pattern works. Image source - Microsoft.com
- Orchestration - An Orchestrator is responsible for decision-making. Check out its example pattern below.
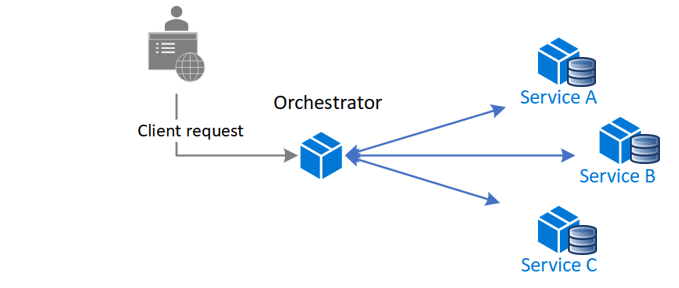
A diagram of how an Orchestration pattern works. Image source - Microsoft.com
More on Saga Pattern
- Perfect for transactions that have lesser steps
- Makes transaction management in a message-driven, loosely coupled environment possible
- Could be used to maintain consistency of data across different services minus the tight coupling
Database per microservice
When a company replaces a large monolithic system with several smaller microservices, the most important decision would be about the database. Many architects favor keeping the database as is, but the short-term benefit is an anti-pattern, particularly in a big-scale system.
A better approach would be to provide each Microservice with its data store to avoid strong coupling between services in a database layer. The key to designing the microservice architecture is to choose a database model, which could either be per service or shared. The design is rapidly evolving and is one of the most important aspects of microservices.
More on database per microservice
- Complete data to a service ownership
- Loose coupling among the development teams building the services
- The application is more resilient
- Individual data stores are easier to scale
- Polyglot persistence that enables the use of various database technologies for different microservices
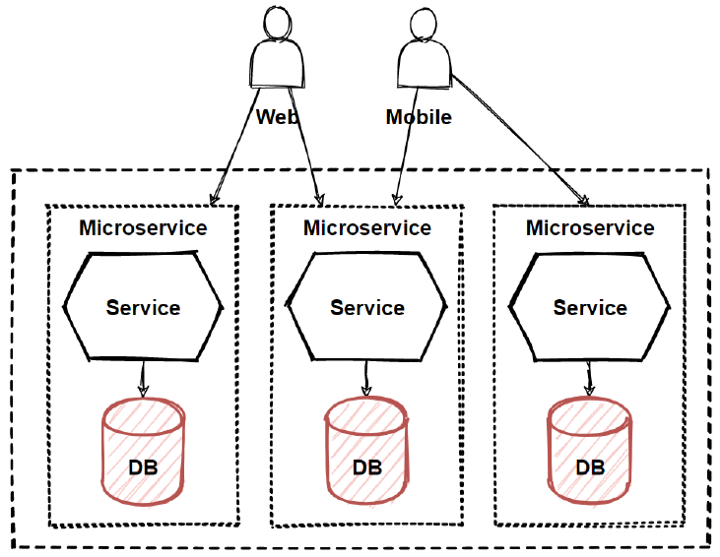 A diagram of how a database per microservice pattern works. Image Source - Mehmet Ozkaya
A diagram of how a database per microservice pattern works. Image Source - Mehmet Ozkaya
Aggregator pattern
In computing, Aggregator refers to a program or website that gathers related data items and displays them. Thus, Aggregator in Microservices patterns is a basic web page that invokes different services to get the information or achieve the functionality required. Moreover, since the output source is divided on breaking the monolithic architecture to microservices, the pattern proves beneficial when you require an output.
With its unique transaction ID, the Aggregator could collect the data from every microservice, apply business logic, and publish it as a REST endpoint. The collected data, later on, could be consumed by the respective services that require the data collected.
More on Aggregator pattern
- Reduces communication overhead between the client and services
- Enables architecturally and easily understood consolidation of the endpoint of discrete functionality
- Intellectually easy to understand and implement, which lets engineers develop time-to-market solutions rapidly
- X-axis and Z-axis scalability
- Provides microservices with a single access point
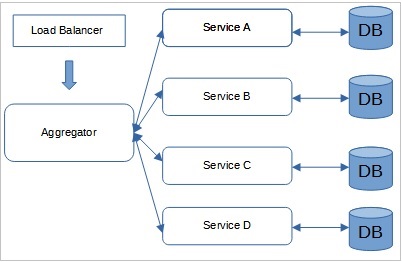
A diagram of how an Aggregator pattern works. Image Source - tutorialspoint.com
Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
Event Sourcing
Event sourcing defines an approach to handling data operations driven by a sequence of events, each of which is recorded in an append-only store. The app code sends a series of events that describe every action that happened on the data to the event store. Typically, the event store publishes these events so consumers can be notified and handle them if required.
For instance, consumers could initiate tasks that apply the events operations to other systems or do any other action associated needed to complete an operation. The events published by the event store are used to maintain materialized views of entities as actions in the app change them and integrate them with external systems.
More on Event Sourcing
- Automatic entities history, which includes time travel functionality
- Event-driven microservices that are loosely coupled
- Provides highly scalable systems with atomicity
- The pattern helps prevent concurrent updates from making conflicts
- Immutable events could be stored with an append-only operation
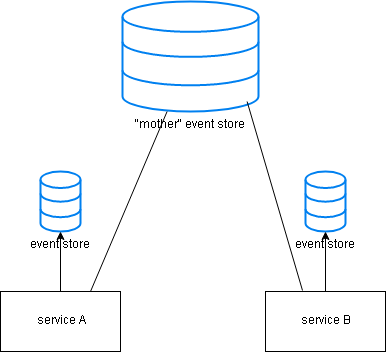
A diagram of how an Event Sourcing pattern works. Image Source - Javarevisited
Command Query Responsibility Segregation
The pattern is useful for implementing a query since data access is limited to only one database. With this pattern, the app is divided into two parts: Command and Query. The command part handles all the requests related to creating, updating, and deleting, and the query part handles the materialized views, which are updated via a sequence of events. With the CQRS pattern, the data modification part or Command is separated from the data read or Query part.
The pattern ensures that a method working with data is allowed only to perform one of two tasks. A method could retrieve or modify information but could not do both.
More on Command Query Responsibility Segregation
- High data availability
- Faster data reading in event-driven microservices
- Read and write systems that independently scale
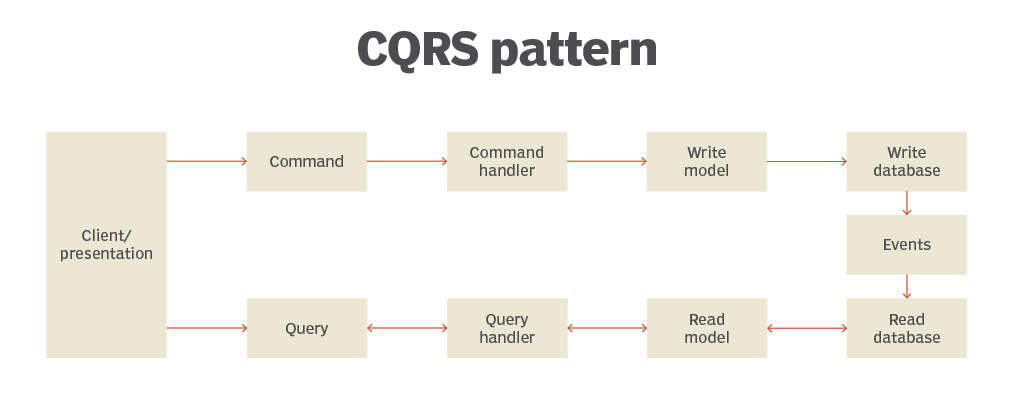
A diagram of how a CQRS pattern works. Image Source - TechTarget
API Gateway
The pattern is suitable for big apps with multiple client applications and is responsible for providing a single-entry point for a certain microservices group. The API Gateway sits between the microservices and client applications and is a reverse proxy. Some cross-cutting services it can provide include SSL termination, authentication, and caching.
The API gateway is capable of handling partial failures and could deal with partial failures in different ways. Instead of providing a one-size-fits-all API style, this pattern could expose a different API for every client.
Furthermore, the pattern could also implement security and verify that the client is authorized to make the request.
More on API Gateway:
- Minimizes the number of round-trip calls between microservices and the client
- Offers loose coupling between frontend and backend microservices
- Provides High security via authentication, SSL termination, and authorization
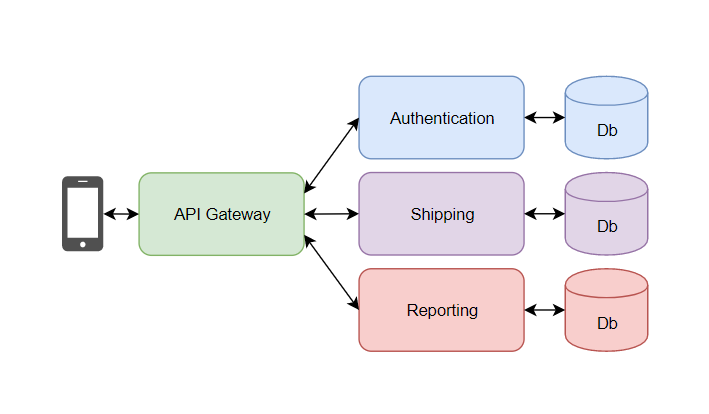
A diagram of how an API Gateway pattern works. Image Source - Javarevisited
Circuit Breaker
The Circuit Breaker pattern could come to the rescue if a service failure could lead to cascading failures throughout the application. The pattern could have the following three states, such as the following:
- Open – request from the Microservice immediately fails, and an exception is returned. The circuit breaker, after a timeout, goes to a Half-Open state.
- Closed – routes requests to the Microservice and counts the number of failures. If the number of failures at a certain time exceeds a threshold, it trips to Open State.
- Half-Open – only a small number of requests are allowed to pass and invoke the operation. The circuit breaker goes to a Closed state if the requests are successful, and if a request fails, it will go to the Open state.
More on Circuit Breaker:
- Stops cascading of failure to other microservices
- Boosts the architecture’s fault tolerance and resilience
- Helps prevent catastrophic cascading failure across various systems
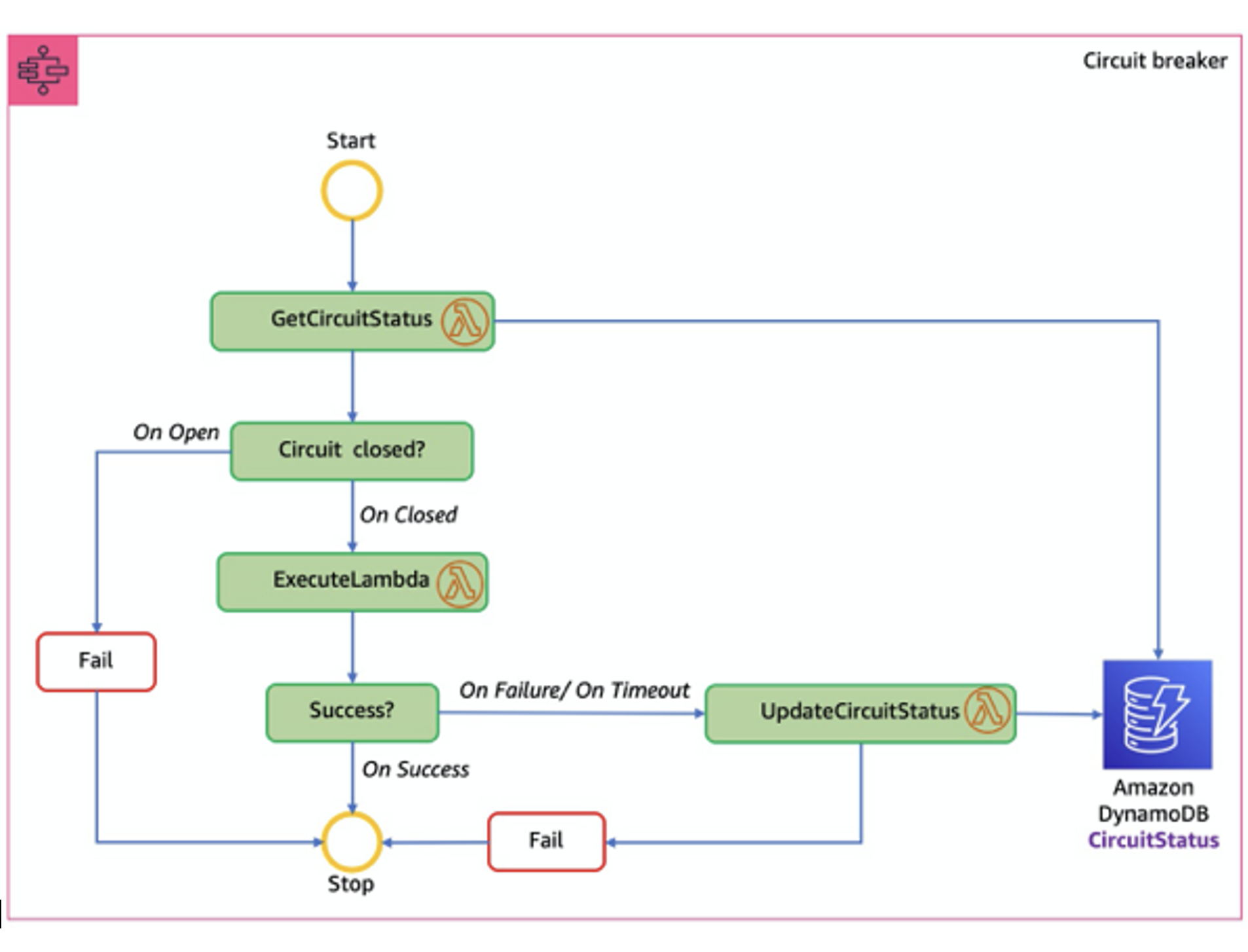
This example uses the AWS Step Functions, AWS Lambda, and Amazon DynamoDB to implement the circuit breaker pattern. Image Source - Amazon.
Wrap Up
Microservices are critical in helping organizations achieve their goals, regardless if it’s faster development, top talent, better software, or lesser costs. It could take time, effort, and resources to convert a monolithic architecture to a microservices architecture, but the rewards are well worth it.
When it comes to microservice design patterns, there are more choices. Furthermore, the list keeps growing as developers get more experience with microservices. These patterns are very effective when it comes to the specialized design requirements of microservices.
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.



