
Inside the AST: How Tools Understand Code

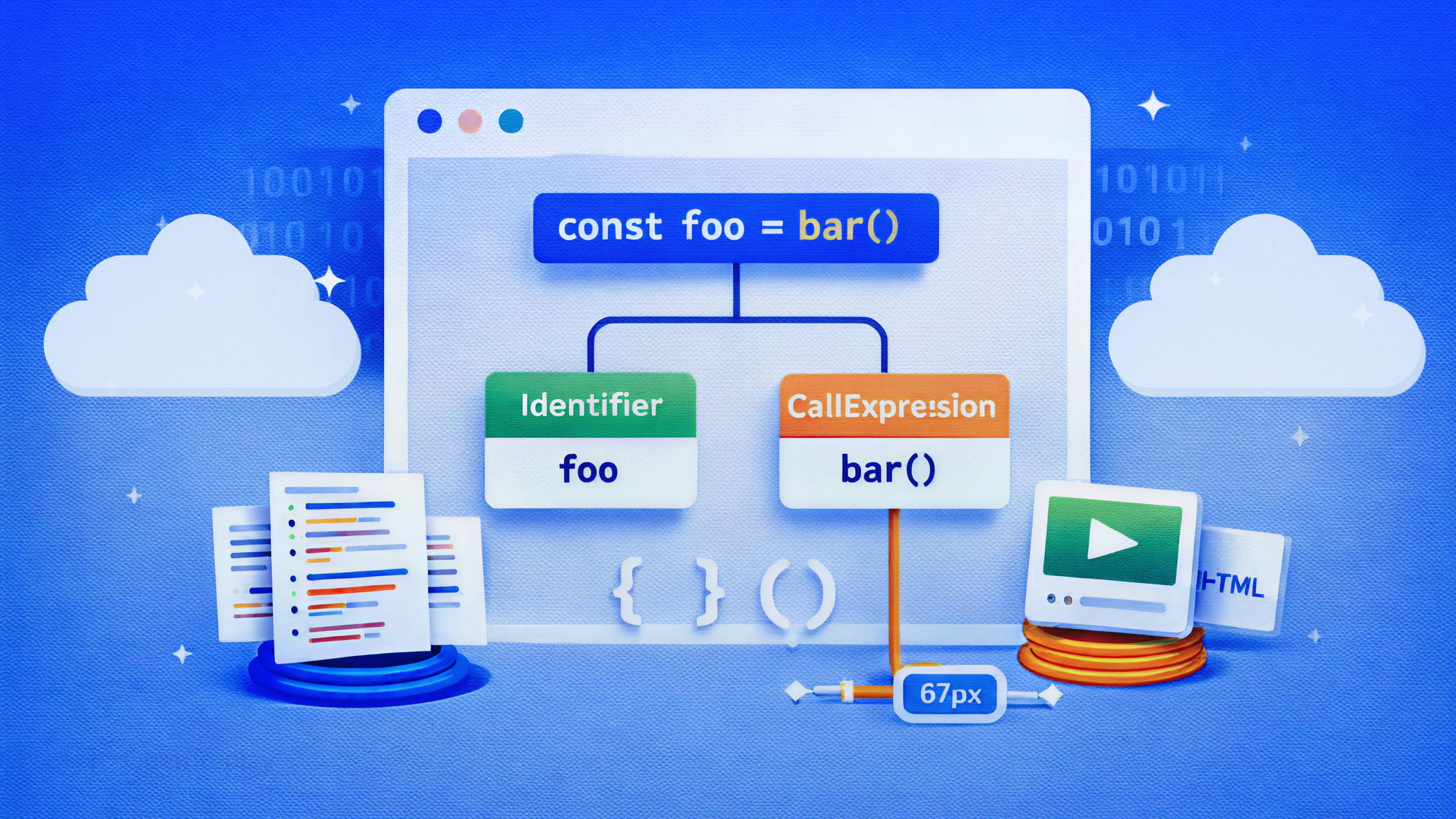
Every time ESLint flags a problem before you run your code, or Prettier reformats a messy function the moment you save, something precise is happening under the hood. These tools are not reading your source code as text. They are reading it as a structured tree. Understanding that tree — the Abstract Syntax Tree (AST) — explains how nearly every modern developer tool works.
Key Takeaways
- An AST is a tree-shaped representation of your code’s structure, often stripped of surface-level details like whitespace and grouping parentheses.
- Linters, formatters, and compilers all work by parsing source code into an AST, traversing it, and applying rules or transformations at each node.
- The visitor pattern is the dominant approach: tools register handlers for specific node types and react as the tree is walked.
- A Concrete Syntax Tree (CST) retains every token, making it better suited for editors that need incremental parsing and full-fidelity representations.
- Rust-based tools like Biome and Oxc use the same parse-traverse-act model but push performance significantly beyond what many JavaScript-based parsers achieve.
What Is an Abstract Syntax Tree?
When a tool parses your source code, it goes through two stages.
First, a lexer (or tokenizer) breaks the raw text into tokens: keywords, identifiers, operators, punctuation. Then a parser takes those tokens and builds a tree that represents the grammatical structure of your code.
That tree is the AST. It is called “abstract” because it often drops surface-level details — whitespace, most punctuation, and parentheses used purely for grouping — while keeping what is semantically meaningful.
Take this line:
const x = 5 + 3A parser produces something like this:
{
"type": "VariableDeclaration",
"kind": "const",
"declarations": [{
"type": "VariableDeclarator",
"id": { "type": "Identifier", "name": "x" },
"init": {
"type": "BinaryExpression",
"operator": "+",
"left": { "type": "Literal", "value": 5 },
"right": { "type": "Literal", "value": 3 }
}
}]
}Every node has a type. Child nodes nest inside parent nodes. The whole program becomes a tree rooted at a Program node.
You can explore this directly using AST Explorer, which lets you paste any JavaScript or TypeScript code and inspect the resulting tree in real time.
How Linters and Formatters Use ASTs
Once a tool has the AST, it can do something useful: traverse it.
Most tools use the visitor pattern. You register a function for a specific node type, and the traversal engine calls that function every time it encounters a matching node.
ESLint works exactly this way. Each lint rule is a visitor object. When ESLint walks the AST, it calls the relevant rule handlers at each node. A rule that disallows == in favor of === simply listens for BinaryExpression nodes and checks the operator property.
Babel uses the same approach for code transformation. It parses source into an AST, applies visitor-based transforms that modify nodes, then prints the modified tree back to source code. This is how it compiles modern JavaScript syntax into older equivalents.
Prettier takes a different angle. It parses code into an AST, discards all original formatting, and reprints the tree according to its own layout rules. The AST is the source of truth — not the original text.

Discover how at OpenReplay.com.
AST vs. CST: When Structure Matters More
An AST omits tokens that are syntactically required but semantically redundant. A Concrete Syntax Tree (CST) keeps the full syntactic structure of the source code, retaining tokens and their positions.
Tree-sitter produces a concrete syntax tree optimized for incremental parsing. Because it can update only the portion of the tree affected by an edit, it is well suited for syntax highlighting, code folding, and structural editing inside modern editors like Neovim and Zed.
The Shift Toward High-Performance Parsing
Newer tools in the JavaScript ecosystem are pushing parsing performance significantly further. Projects like Biome and Oxc are implemented in Rust and build their own parsers and AST representations from scratch.
They handle linting and formatting at speeds that often outperform JavaScript-based parsers, while supporting modern syntax such as import attributes and recent TypeScript features.
The underlying model is the same — parse to a tree, traverse it, apply analysis or transformation — but the implementation is optimized for scale.
Conclusion
Whether you are writing a custom ESLint rule, building a codemod with jscodeshift, or just trying to understand why a tool behaves the way it does, the AST is the right place to look. It is the structured representation that every serious developer tool is built on top of. Once you can read a syntax tree, the behavior of linters, formatters, and compilers stops feeling like magic.
FAQs
Not for everyday use. These tools work out of the box with sensible defaults. But if you want to write custom lint rules, build codemods, or debug unexpected tool behavior, understanding how ASTs represent your code gives you a clear mental model of what the tool is actually doing at each step.
An AST strips away syntactically required but semantically redundant tokens like commas, brackets, and whitespace. A CST retains the full syntactic structure of the source code. CSTs are preferred in editors and IDEs where full-fidelity representation and incremental parsing matter, while ASTs are typically used by linters, compilers, and formatters.
The easiest way is AST Explorer at astexplorer.net. Paste any JavaScript or TypeScript snippet, choose a parser like acorn, babel, or typescript, and the tool displays the full tree in real time. It also supports other languages and lets you experiment with transforms directly in the browser.
Rust gives these tools direct control over memory allocation and layout, avoids garbage collection pauses, and compiles to highly optimized native code. This means parsing, traversal, and analysis all run significantly faster, which becomes especially noticeable in large codebases with thousands of files.
Understand every bug
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
