Building Scalable Web Applications
Create an architecture that can grow to handle bigger demand levels


Scalability refers to your web application’s ability to handle the increasing amount of work, i.e., user demand. It requires proper planning from all stakeholders involved. This article explores the architecture involved in building a scalable web app and choosing the one important to your brand.

Discover how at OpenReplay.com.
According to Worldometer, the world population is about 8 billion people, and about 5.35 billion people have access to the Internet. This means we live in a time when we have more online presence than in the 20th century. People now have access to the internet, and as a business owner or organization, this is a great advantage for you to be able to access these billions of people by building web applications that can handle growing numbers of users and data without sacrificing performance or reliability. This term is referred to as scalability.
Understanding scalability needs
Building a successful business is a journey, not a destination. The same goes for Scalability, because as your business grows, the number of online visitors to your web application also grows. Scalability refers to your application’s ability to handle increasing amounts of work traffic or data without sacrificing performance. It means that as the demand for your application grows, the system can adapt and handle the increased load efficiently.
Types of scalability
There are two major types of scalability when dealing with web applications: vertical and horizontal (scaling out).
Vertical scalability: This is adding more resources or power such as (Central Processing Unit (CPU), Random Access Memory (RAM), or storage)) to a single server to handle increased load. There are limits to how much you can scale vertically, as there is a maximum capacity for individual hardware components.
Horizontal scalability: This is adding more servers to distribute the load across multiple servers. This approach allows for more flexibility and can potentially handle an unlimited load by adding more servers to the infrastructure.
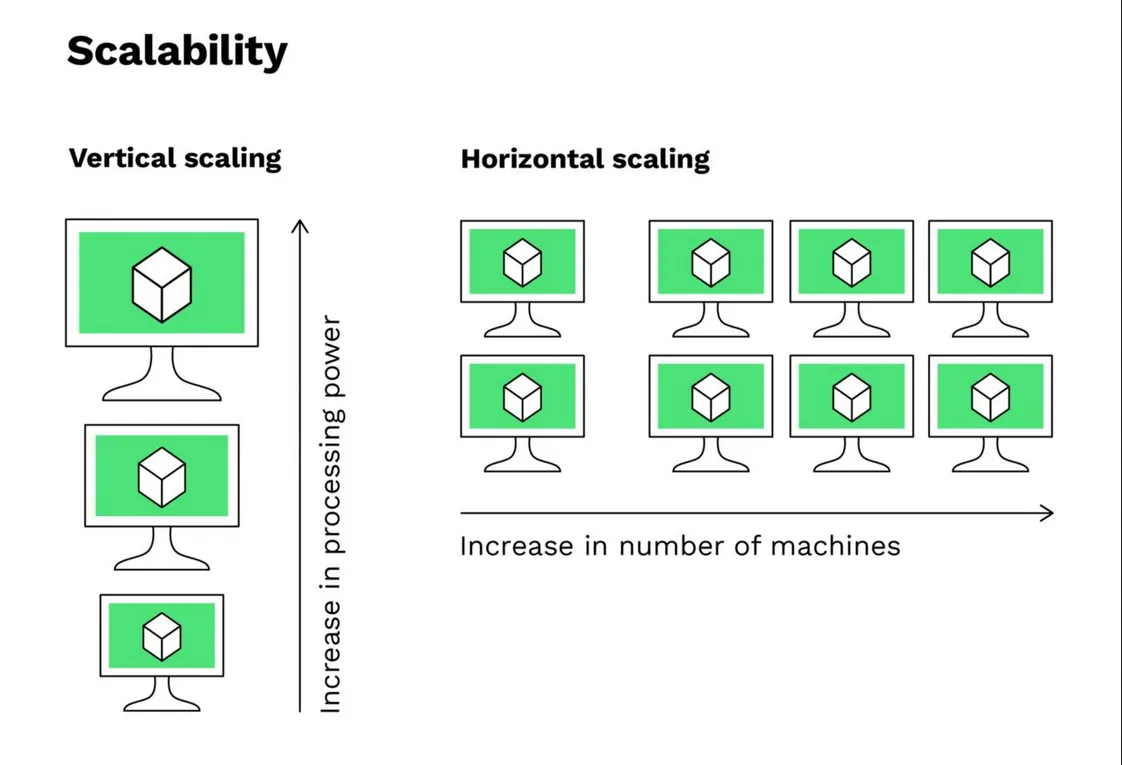
The diagram above represents the difference between vertical scalability and horizontal scalability.
Factors to consider when dealing with scalability
These are some of the factors to consider when dealing with scalability:
-
Traffic Volume: This is the expected volume of traffic(users) your application will receive.
-
Data Volume: Scalable programs must be able to manage increasing amounts of data and transactions.
-
Cost Considerations: Scaling infrastructure can incur additional costs. Thus, it’s necessary to combine scalability with cost-effectiveness. This requires optimizing resource consumption, leveraging cost-effective cloud services, and developing efficient scaling solutions.
-
Infrastructure Scalability: Scalable applications demand scalable infrastructure. This comprises cloud services, container orchestration systems, and auto-scaling methods that may dynamically distribute resources based on demand.
Modular Architectural Strategies for Scalability
Modular architecture is a method used to develop software systems where the system is broken down into smaller, independent modules or components, each responsible for a certain functionality or feature. These modules are often designed to be self-contained so they can be developed, tested, and maintained independently.
Dive into Microservice Architecture
Microservices architecture is a software development approach that enables large teams to build scalable applications that are composed of many loosely coupled services; i.e., Each service handles a dedicated function inside a large-scale application: is independently deployable, and is responsible for specific business capabilities. For example, shopping carts, billing user profiles, and push notifications can all be individual microservices for an e-commerce web app. This architectural style offers several benefits, including scalability, flexibility, and the ability to use different technologies for different services.
Principles and components of Microservices
Here are the key principles and components of a microservice architecture:
-
Decomposition: Microservices divide a large application into smaller, independent modules, each responsible for a distinct business capability, such as billing user profiles or shopping carts for an e-commerce web app.
-
Single Responsibility: Each microservice has a particular task or carries out a specified business function. This guarantees that services remain focused, maintainable, and easily adaptable.
-
Inter-Service Communication: Microservices interact with one another via well-defined Application Programming Interface (
APIs). This communication takes place viaHTTP/RESTor messaging systems like RabbitMQ or Kafka. -
Scalability: Microservices offer horizontal scaling by allowing individual services to scale independently in response to demand. This scalability is required to handle varying workloads efficiently. Other structures such as monolithic architectures can make it more challenging to evolve components independently due to their interdependencies and shared codebase, making changes risky and more likely to impact the entire system.
What is Database scalability?
Database scalability refers to a database system’s capacity to handle a growing amount of data and an increasing number of users or requests. It is the ability to efficiently and effectively manage a larger volume of data, support more concurrent users, and handle a higher frequency of data queries and transactions as the database’s demand increases.
Database scalability can be achieved through various strategies such as sharding, replication, and partitioning. These strategies ensure a database system can efficiently handle increasing data volumes and user loads. Let’s explore them in detail:
Sharding
Sharding involves horizontally distributing data over several database units called shards. Like a book divided into chapters to make up the whole book, each shard contains a subset of the data, and together, they constitute the whole dataset. Sharding is particularly effective for splitting the workload over numerous servers, enhancing scalability and performance.
Sharding is ideal for large datasets and read-mostly workloads (a situation where the majority of database operations are read operations, such as SELECT queries). Read operations are database operations used to retrieve data from a database.
Common sharding techniques include:
Range-based sharding: Data is divided based on a specific range of values, such as IDs, timestamps, or alphabetical ranges. For example, one shard may handle data with IDs from 1 to 10000, while another handles IDs from 10001 to 20000. It is well-suited for queries that filter data based on that attribute.
Hash-based sharding: Data is distributed across shards based on a hash function applied to a shard key (e.g., user ID). The hash function determines which shard the data should be stored on.
Replication
This strategy involves creating copies of your entire database on multiple servers. These copies, called replicas, act as backups or offload read requests from the primary server.
There are two main types of replication:
Synchronous replication: Changes made to the primary server are immediately reflected on all replicas. This ensures high data consistency but can impact performance.
Asynchronous replication: Changes made in the primary server do not immediately reflect in the secondary server. There is usually a delay between when the data is stored in the primary server and when it reflects in the other replicas.
Partitioning
Partitioning involves splitting a large table into smaller, more manageable portions called partitions. Each partition can be stored and handled independently, allowing for increased performance and scalability.
Partitioning works well with Large tables and predictable access patterns.
Common types of partitioning include:
Range Partitioning: Data is partitioned based on a specified range of values. For example, you might partition a sales table by date, with each partition containing data for a specific range of dates (e.g., one partition for each month).
Hash Partitioning: Data is partitioned based on a hash function, which produces a unique key or identifier for each row in the table. The keys are then mapped to specific partitions, ensuring that similar data is stored in the same partition for quick and efficient querying.
Choosing the right strategy
When it comes to choosing the right strategy for database scalability, it’s important to consider the specific needs and requirements of the application or system. But here is a quick guide:
- Sharding for massive datasets and read-heavy workloads.
- Replication for high availability and read scaling.
- Partitioning for optimizing queries on large tables with predictable access patterns.
Essential technologies and tools
Essential technologies and tools that support scalability include:
Load balancers and caching mechanisms for servers
When it comes to providing support for scalable web applications, load balancers, and caching mechanisms are essential components. To understand how these technologies contribute to scalability, let’s explore each in detail:
Load Balancers
Load balancers are devices that divide incoming network traffic among numerous servers to prevent any one server from becoming overloaded. Optimizing resource utilization and maintaining high availability play a significant part in improving the scalability and performance of online applications. This is accomplished through performance enhancement. Some important things to keep in mind are as follows:
-
Scalability: Load balancers help distribute incoming traffic evenly across numerous servers, preventing any one server from becoming overloaded.
-
High Availability: Load balancers help improve the availability of online applications by balancing traffic across numerous servers. In case one server fails, the load balancer sends traffic to healthy servers, assuring continuity of service.
-
Health Checks: Load balancers can execute health checks on servers to verify their availability and responsiveness. Unhealthy servers can be automatically removed from the load balancer rotation, preventing them from hurting the application’s overall performance.
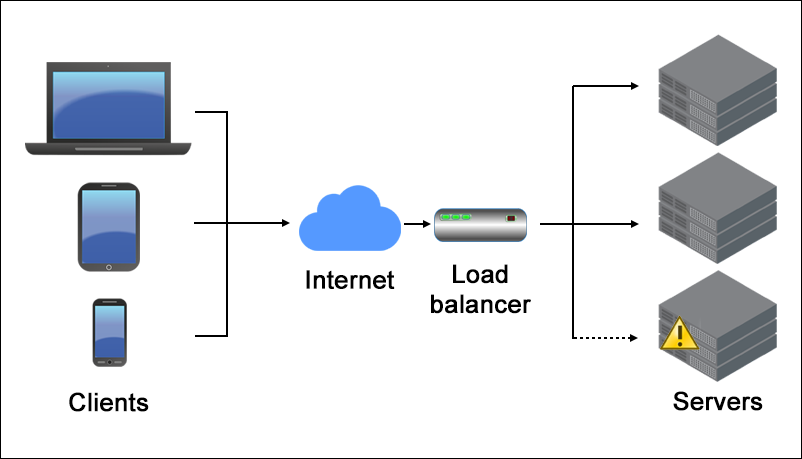
The image above shows a proper description of a load balancer.
Caching mechanisms
Caching mechanisms help improve the efficiency and scalability of web applications by storing frequently visited data in memory or on disk. Cached data(temporary storage of information that has been recently accessed or used) can be retrieved quickly, decreasing the burden on backend servers. The Caching mechanism contributes to scalability through the following:
-
Reduced Server Load: By storing frequently accessed data or computed results, caching mechanisms lower the number of requests that need to be processed by backend servers.
-
Faster Response Times: Cached data may be served promptly to users, lowering latency and improving the user experience.
By successfully deploying load balancers and caching mechanisms, web applications can achieve enhanced scalability, performance, and reliability, even under high-traffic conditions.
Cloud computing
The term “cloud computing” refers to a model that allows users to rent various computer resources (storage, processing power, databases, networking, etc.) over the Internet. Cloud computing is important for developing scalable web applications because it provides the resources and infrastructure needed to successfully handle fluctuating demand and growth on a pay-as-you-go model. Instead of managing physical servers yourself, you rent virtual resources from cloud service providers (CSPs) like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP).
Cloud computing allows web applications to scale in the following ways:
Elasticity
With cloud platforms, resources like storage, bandwidth (the maximum amount of data that can be transmitted over a network in a given amount of time), and processing power can be easily increased or decreased to meet fluctuating demand. This means that web apps don’t need human involvement to automatically adapt to increased workload or traffic.
Auto-Scaling
Web applications can use cloud platforms’ auto-scaling functionality to automatically adjust resource allocation based on predefined parameters like CPU utilisation, memory consumption, or incoming requests. This ensures that the program can handle abrupt increases or dips in traffic without downtime or performance degradation.
Global Distribution
Cloud companies have data centers located in many areas throughout the world. Developers can exploit this worldwide infrastructure to deploy their web apps closer to end-users, lowering latency. Also, global distribution helps distribute traffic internationally, limiting the impact of regional breakdowns or traffic spikes.
Pay-Per-Use Model
Cloud computing follows a pay-per-use pricing model, where customers only pay for the resources they consume. This lets developers expand resources depending on actual demand and pay only for what they use, making scalability more cost-effective.
Cloud computing provides a good foundation for building scalable web applications. With its on-demand resources, pay-as-you-go model, and global reach, cloud computing allows developers to focus on innovation while ensuring their applications can handle ever-changing user demands.
Asynchronous processing and message queues
Asynchronous processing refers to the ability of a system or program to execute tasks concurrently without interrupting the main operation.
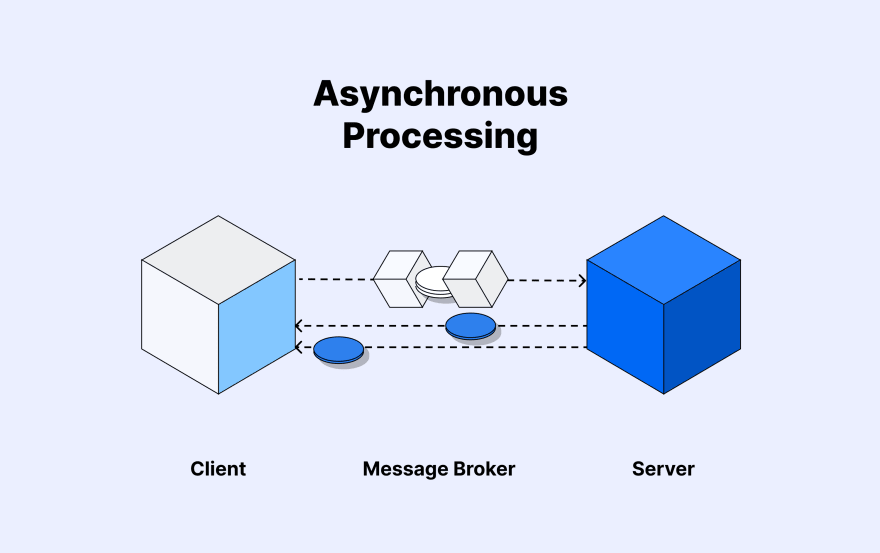
An image showing an asynchronous processing can do tasks independently of the main execution flow.
Messaging queues, on the other hand, are a means of managing workloads in a distributed system. They allow messages to be delivered and received individually, allowing for non-blocking communication between components. This enables more efficient resource use and higher scalability.

An image showing the process flow of the message queue.
Let’s explore how they help in building scalable web applications:
Concurrency Management
In a web application, many requests can come simultaneously. Asynchronous processing allows these requests to be handled concurrently without disrupting the main thread of execution. This means the program can continue serving new requests while executing long-running operations in the background.
Fault Tolerance
Message queues provide a layer of fault tolerance by storing messages until they are successfully processed. This ensures that no data is lost even if a component of the application fails, leading to increased reliability and scalability.
With these technologies, web applications become more responsive, scalable, and fault-tolerant.
NoSQL databases and NewSQL databases
NoSQL databases and NewSQL databases play crucial roles in building scalable web applications by offering different advantages. NoSQL databases, such as key-value stores and wide-column stores provide scalability for larger data sets commonly found in analytics and AI applications. They simplify application development, offer flexibility for unnormalized data, and are better suited for cloud, mobile, social media, and big data requirements. On the other hand, NewSQL databases combine the distributed scalability of NoSQL with ACID guarantees (Atomicity, Consistency, Isolation, and Durability), making them essential for business systems processing high volumes of data with full transactional support and ACID compliance. NewSQL databases like Cockroach DB, TiDB, YugabyteDB, and Vitess provide global scalability, strong consistency, high availability, and compatibility with SQL databases.
The scalability of web applications with NoSQL databases is important as it allows for horizontal scaling of applications by distributing computing tasks across servers to handle increasing user loads effectively. NoSQL databases enhance response time and scalability by supporting distributed computing for real-time data processing and parallel processing of data. In contrast, NewSQL databases are vital for systems requiring high-volume data processing across distributed environments while ensuring data consistency and reliability.
The best database type depends on your web application’s specific needs:
-
For web applications handling massive volumes of unstructured data or where data structures are constantly evolving, NoSQL provides the flexibility and horizontal scalability to grow seamlessly.
-
NewSQL offers a compelling solution for web applications requiring high-performance transactions, data consistency, and the ability to scale while still using a familiar SQL interface.
Conclusion
In this blog, we’ve explored the architecture when building a scalable web application, from the requirements involved, which includes proper planning from the developers, understanding the business needs and objectives, knowing what type of scaling is needed for your business, and knowing the type of database to employ to optimize performance. Businesses can grow and stay ahead to accommodate future growth.
Scale Seamlessly with OpenReplay Cloud
Maximize front-end efficiency with OpenReplay Cloud: Session replay, performance monitoring and issue resolution, all with the simplicity of a cloud-based service.
Start with Cloud

