
Data Lake vs Data Warehouse: Key Differences and When to Use Each



Discover how at OpenReplay.com.
Have you ever wondered where the data we create and use in our everyday activities ends up? Whether it is from storing website activities, social media posts, to even our online shopping transactions, this big volume of data needs an efficient and safe place where it can be stored, managed, and analyzed. Why? Well, because today’s world is driven by data, knowing how to store and manage it efficiently can help any business out there to thrive. Now, deciding on the best place to store this data is also important because, if done right, it can help us identify trends and predict customers’ future needs and behavior.
The two main solutions for storing data are data lakes and data warehouses. Each has its own features and strengths that make it perfect for a specific type of data, as this article will show.
Understanding Data Lakes
Okay, now I understand you have a lot of questions like, “What’s the difference between a data lake, data warehouse and a database like MySQL or PostgreSQL that we’re all familiar with?” Just chill—everything will be explained in this article. But first, let’s study what a data lake really is to see whether it’s the perfect storage space you’ve been looking for in your next project.
A data lake is a digital storage space that holds structured, semi-structured, and unstructured types of data. Look at it this way: it’s like a lake where any kind of data (text document, video, audio, and so on) can flow in without any form of restriction and may later be organized. This flexibility makes a data lake ideal for businesses that gather information from multiple sources and want to store it in a particular single place until they are ready to organize and use it.
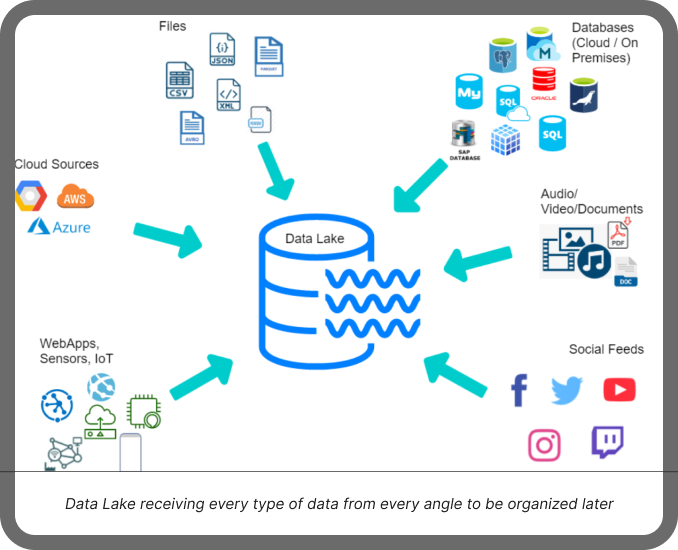
The image above helps to visualize a data lake as a centralized reservoir that can take in any kind of data—structured, semi-structured, and unstructured, such as text, videos, databases, and web apps.
For example, a social media app might decide to use a data lake to store everything a user uploads (like their pictures and videos), their posts, likes, and interactions. This data, stored in its raw form, might later be used to predict user behavior patterns or the kinds of content to recommend to that particular user.
Characteristics of Data Lake
How can you tell if a particular storage solution is a data lake? Well, let’s look at the kind of data it accepts and how it goes about doing that.
- Schema-on-read approach: Data lakes use a schema-on-read approach, which means that data is not arranged or organized at the point of entry until someone organizes it. Picture a library store where all kinds of books are dumped without being sorted by genre or topic. When you need to read a particular book, you then try to organize it yourself. The same goes for a retail company that collects all customer logs and comments in one place to sort later.
- Unstructured and structured data: By now, you should know that a data lake can contain all sorts of structured and unstructured data. Structured data includes those with a pre-defined format or pattern, like databases or tables, while unstructured data consists of unsorted forms like video files, photos, PDFs, emails, etc. An example could be a hospital that stores structured data like patient records alongside some unstructured data like doctors’ notes, all in the same data lake.
- Scalability and flexibility: Since data lakes accept any kind of data on the go without having the need to delete or organize it, they quickly scale up as time goes. This is usually good for businesses that expect data to grow quickly as they work. For example, a media company holding an event can easily store all kinds of data, and after the event, they can then sort it for that program.
Advantages of Data Lake
Data lake solutions like Amazon S3 are generally more affordable when compared to other cloud-based storage solutions out there. Why is this? Well, the fact that they don’t require their data to be first processed or organized before storage helps save companies a lot of money that would have gone into organization and individual storage.
Also, since we know data lakes accept diverse data types, they are ideal for companies that collect and gather different kinds of information for processing. For example, a machine learning tech company that focuses on training models can benefit from data lakes as they allow the collection of diverse information, such as audio samples, text data, videos, all kinds of imagery, and so on, all of which are essential for training their models.
Limitations of Data Lake
Because data are stored in their raw form, meaning they are not processed or analyzed, processing them later can be challenging and a bit complex. For example, a retail shop that has stored customer feedback along with transaction logs and images might spend a lot of time trying to process this large amount of data to make it usable for customer sentiment analysis.
Moreover, too much data can turn into what is called a ‘data swamp,’ which is basically when data becomes too messy and hard to even figure out. That’s why a specialist or an expert usually handles this kind of work.
Finally, since this option can store a large amount of diverse data and scales up as time goes on, it’s not an advisable choice for tasks or operations that require fast, structured analysis. For example, if a company wants to calculate its total sales quickly every 12 hours, a data lake might not be as fast or efficient as a data warehouse for that purpose.
Key Technologies
Let’s discuss some of the common technologies that you can use to set up and manage data lakes. With these tools, you are able to store, process, and retrieve large amounts of datasets.
Hadoop: Hadoop is an open-source framework commonly used by many companies because it stores and processes large amounts of datasets with ease, both structured and unstructured, which is basically what a data lake is all about. At the same time, it is cost-effective for companies needing large storage solutions.
Some of the benefits of using Hadoop are shown below:

Here, we see some of the benefits of considering Hadoop as a storage option include cost-effectiveness, scalability, speed, flexibility, high availability, and low network traffic usage. These make it a great choice for companies that handle big data processing.
Amazon S3: Amazon Simple Storage Service (S3) is another popular storage solution out there. Like Hadoop, it’s scalable, affordable, and fit for big tech companies that store lots of diverse datasets. Now, since it’s scalable, companies do not have to invest additional money in purchasing any other physical storage option. For example, an e-commerce website may choose Amazon S3 to store their user’s activity data and will not have to worry when the data scales or builds up while also being able to access those data anywhere in the world.
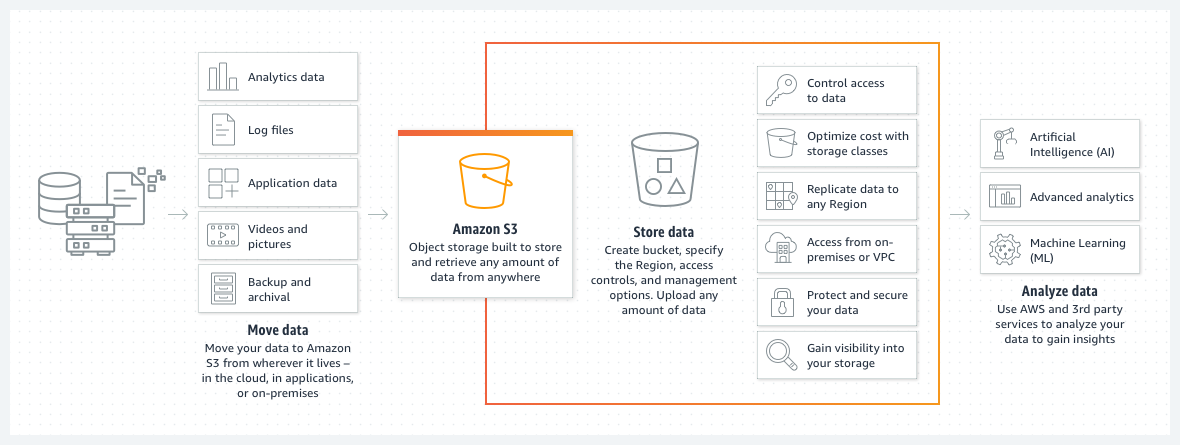
A closer look at the image above reveals that diverse data—such as log files, videos, images, application data, and backup files—can be stored in Amazon S3. Later, when analyzed, this data can provide insights for artificial intelligence, machine learning, and more.
Understanding Data Warehouses
A data warehouse is a specialized kind of storage that stores only structured forms of datasets for quick analysis and reporting. Unlike a data lake, where you are free to just dump all kinds of raw data, a data warehouse is more structured and organized. Think of it like a neatly arranged library where every book is categorized into its own topic or genre. This makes it fast and easy if you are searching for a particular book, no matter how long it has been there. On the other hand, businesses use data warehouses to store information that is ready to be analyzed, like sales records, transactional logs, or customer data.
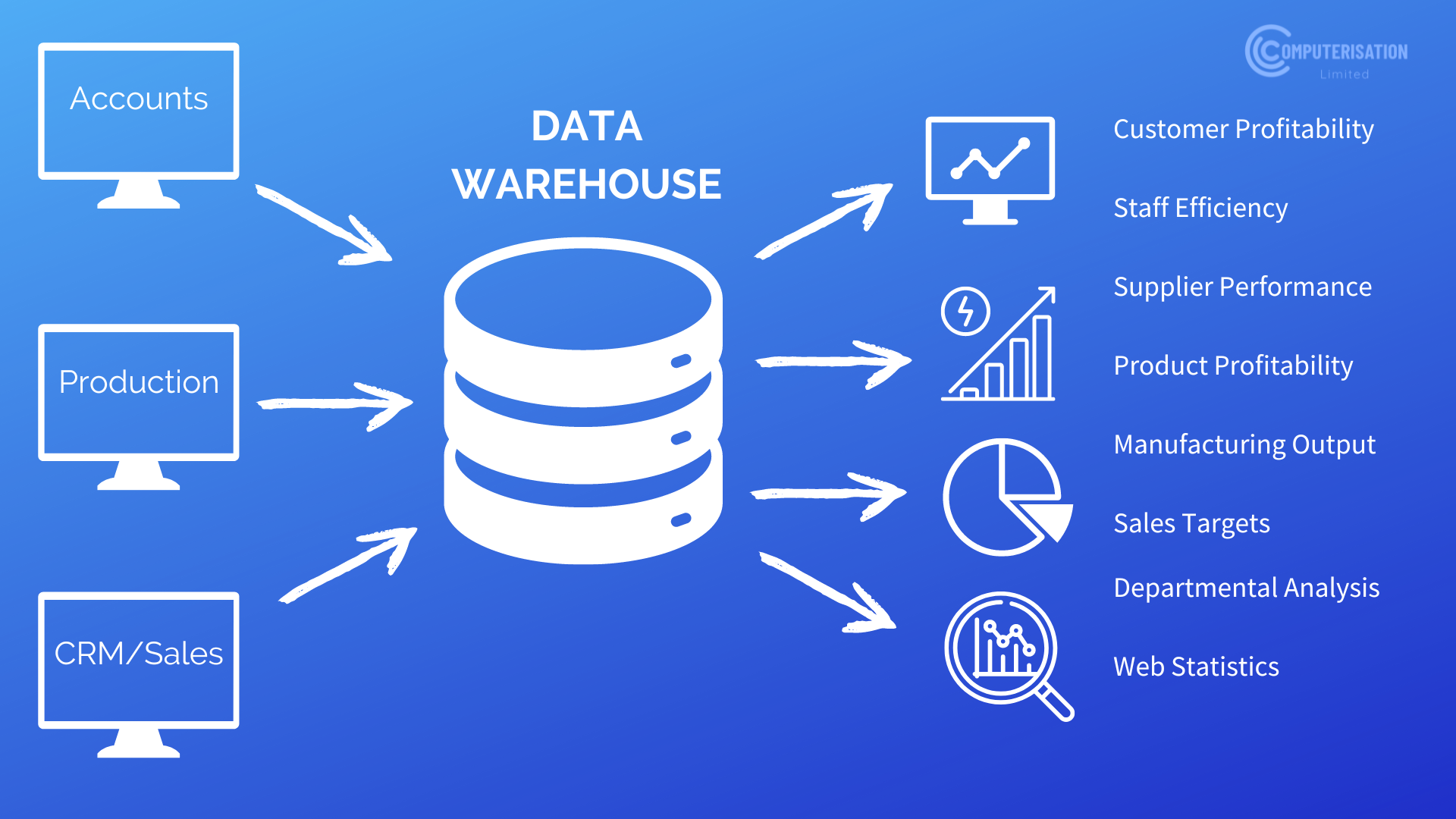
As shown in the image above, accounts, production, and sales information are entered into the data warehouse to be analyzed and processed. Now, the output is great insights like sales targets and product profitability that will cause any business to thrive. Whereas in a data lake, we can’t really deduce anything from it—it’s just a placeholder of data for later use.
Characteristics of Data Warehouse
Let’s look at some of the ways you can identify if a storage solution is a data warehouse.
- Schema-on-write approach: Unlike the data lake, all data in a data warehouse must be organized before it’s stored. It uses a method called ‘schema-on-write,’ which means data must be structured and formatted before it can go into the data warehouse. Picture this: each data coming in is placed in its respective folder so it can be easily accessed later on.
- Focus on structured data: When we say structured data, we are referring to data that fits neatly into tables, like the rows and columns in our ideal knowledge of a database. For example, information like our company’s customer data, transaction logs, and so on. Yes, that’s the kind of data a data warehouse takes in.
- Optimized for analytics and reporting: One of the key differences between a database and a data warehouse is that data warehouses are built for fast analytics and reporting, while databases are only good for organizing data into information like customer data and so on. A data warehouse is where that information is intelligently analyzed to make sense of it and understand customer behavior and actions, which makes them valuable for businesses that need real-time insights and reports.
Advantages of Data Warehouse
One of the biggest advantages of a data warehouse over a data lake is speed. I mean, it’s no surprise it’s faster than a data lake since the kind of information stored in it is only the structured and organized ones. With that in place, when data is requested, it is easily found and used.
Another benefit of a data warehouse is the fact that all of its data is clean and accurate, so there are no mistakes or duplicates when trying to make sense of its information in reporting. This is especially useful for healthcare providers that need patient records to be up-to-date and accurate so that doctors will not make mistakes when treating a patient.
Limitations of Data Warehouses
Data warehouses are not well suited for unstructured kinds of data, like social media posts, emails, or different types of images. This means that data lakes are more flexible than they are in this aspect. For example, if a tech company wants to store large video footage to train one of their models, a data warehouse won’t be compatible with them here since it works best with structured kinds of data.
Moreover, data warehouses are more expensive to manage and maintain when compared to data lakes. It makes sense since the resources required are carefully structured and organized.
Key Technologies
Several platforms are popular for building and managing data warehouses:
Amazon Redshift: This cloud-based data warehouse is mainly suitable for companies that need large-scale data analysis, and fast query performance. For example, an e-commerce website might use Amazon Redshift to store each customer’s location in real-time in order to make quick delivery sales.
So, normally, when a database is transferred into a data warehouse, there is a process involved called ETL (Extract, Transform, Load). However, with Amazon Redshift, you don’t necessarily need that entire approach; you can simply move the database into it, and it processes it, making it easy for business owners and managers to query, share, learn, and interpret such data.
Something like this:
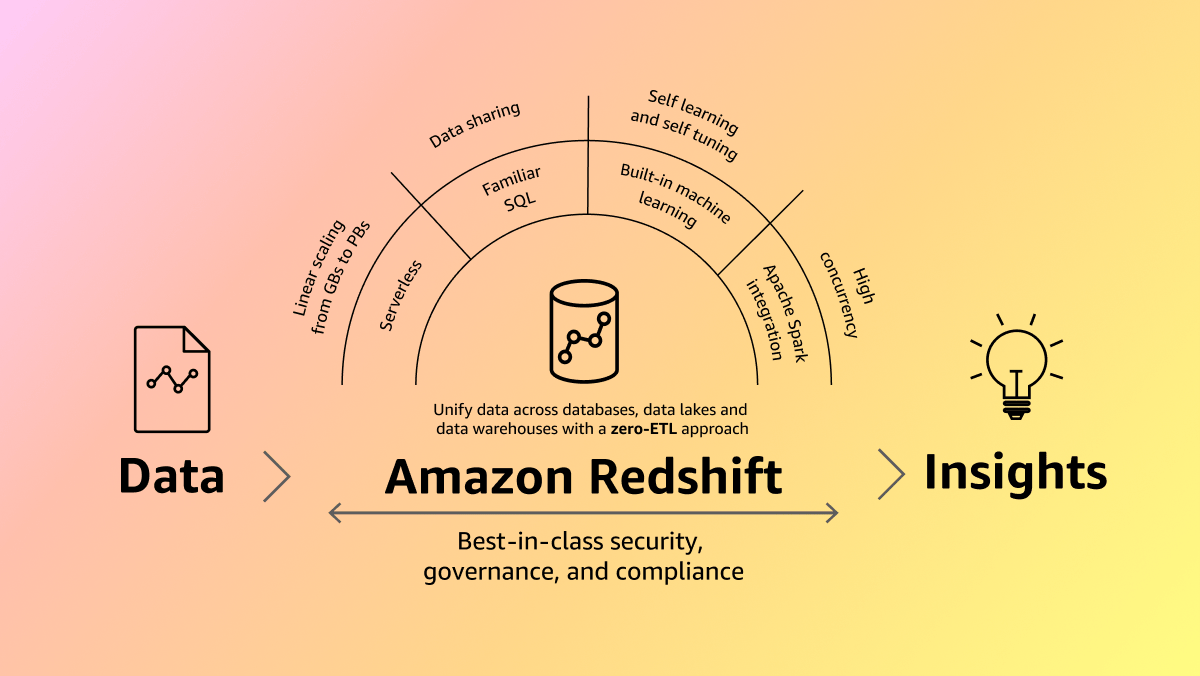
This architectural diagram explains the flow of how Amazon Redshift stores and performs analysis on structured data. It shows how data can be ingested very quickly into the warehouse and without requiring a complete ETL (Extract, Transform, Load) process to do so, giving businesses critical near-real-time analysis of their data, which is key in decision-making and reporting within data-driven industries.
Snowflake: This is also a cloud-based data warehouse that is highly flexible and can integrate well with other data sources. It allows businesses to scale their storage power as high as needed; this is particularly useful for companies with fluctuating data needs. For example, a company might use Snowflake to run historical data in order to find patterns or predictions that will help their present customer needs.
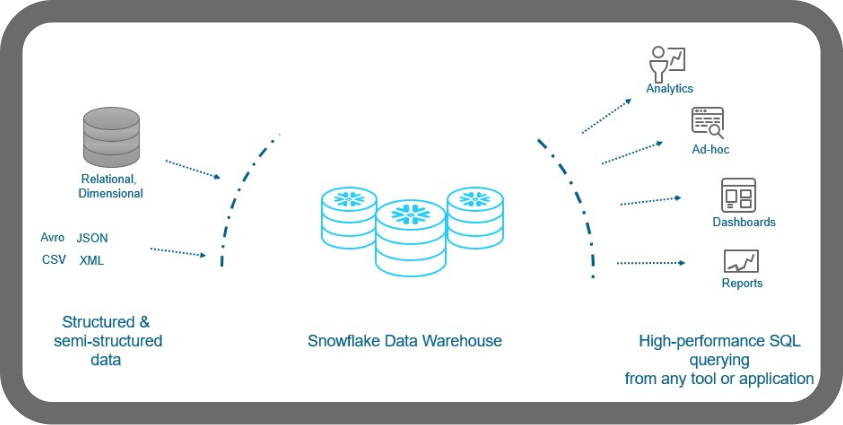
This image represents the ability of Snowflake to store both structured and semi-structured analytical data such as JSON files. Moreover, it also shows the ability to combine with different data sources that depicts snowflake is a great option for any organization needing a scalable and elastic data warehouse which can accommodate changing data requirements — especially for historical data analysis, reporting, and prediction.
Key Difference Between Database, Data Lake, and Data Warehouse
Let’s quickly look at a table that provides an overview of the differences between a database, data lake, and data warehouse.
| Features | Database | Data Warehouse | Data Lake |
|---|---|---|---|
| Use Case | Real-time apps | Business intelligence | Data science, big data |
| Volume | Smaller volumes | Large, but structured | Very large, raw data |
| Data Types | Structured (SQL) | Structured (SQL) | Structured, semi/unstructured |
| Data Structure | Schema-on-write | Schema-on-write | Schema-on-read |
| Purpose | Transactions | Analytics | Large-scale, diverse data |
As shown in the table, a database handles daily transactions or operations, while a data warehouse focuses on providing the analysis and history of such database information. Finally, a data lake just stores large amounts of raw data that can be sorted later for analytical purposes.
Let’s look at some other ways we can differentiate between a data warehouse and a data lake.
Data Structure and Storage: Unstructured vs. Structured
Let’s start with the kinds of data they are allowed to hold. While data lakes are mainly used by businesses that don’t know where to store their data or what they really need at the time, anything can be thrown in, including structured, semi-structured, or unstructured data. Data warehouses, on the other hand, are more selective, which is why many organizations use them. They only accept structured and organized data—data in rows and columns, formatted like tables in spreadsheets. No wonder it’s faster and easier to locate things in them.
Schema: Schema-on-read vs. Schema-on-write
I know we have discussed this earlier, but let’s go a little deeper into it because the way this data flows matters a lot, too. Data warehouse uses a ‘schema-on-write’ approach, which basically means that before any data can be stored, it has to look clean and organized. Think of it like sorting different items and labeling them before putting them inside the main store. This whole process will take extra time, but it will make it easier to find things faster later on.
On the other hand, data lake uses the ‘Schema-on-read’ approach, which basically means that data is stored in its raw form without any pre-assessment or organization. For example, a social media application like Facebook might use data lake to collect millions of interactions on their app and sort them later to make sense of it.
Performance and Processing: Batch vs. Real-Time Analytics
Data lakes are well suited for batch processing, where large amounts of data are processed in bulk rather than instantly. Data warehouses, however, can provide analysis and reports in real-time with high speed, and since data is already organized, data warehouses are ideal for tasks that require quick responses, such as in financial trading platforms where real-time decision-making is needed.
Cost and Scalability: Storage Cost Differences and Scaling
Another question any business has to ask itself before choosing the best storage solution is: How much are we willing to spend on storage? Data lakes are quite cost-effective for large-scale data storage compared to data warehouses. Since data doesn’t require organization and preparation, companies save a lot on costs, especially if they use cloud storage options like Amazon S3.
Data warehouses, on the other hand, are more expensive because they require a lot of structure and organization to prepare data for storage. However, this also makes them more efficient and quick. So, data warehouses are often preferred by businesses where speed is more important than cost, like in healthcare institutions.
Security and Governance
Security and governance play a crucial role in each of these storage solutions.
For data lakes, governance tends to be more flexible and looser, as they store raw data and are more likely to run into a “data swamp” if not managed well. However, security measures are still taken to prevent unauthorized access.
Data warehouses, on the other hand, have strict security and high governance control. This is because highly sensitive information, like patient records, financial records, and other health data, can be stored in a data warehouse. This alone makes data warehouses suitable for businesses with strict data regulations, like banks and healthcare facilities.
Use Cases: When to Use Each
Both data lakes and data warehouses serve specific data needs for different types of businesses. Let’s look at when it’s best to use each one.
When to Use Data Lake
This means of storage is better when you need to store large, raw data in various formats without needing to structure it immediately. Here are a few areas where data lakes are best to use:
- Big Data Analytics: Data lakes are preferred for analyzing big data because they can store vast amounts of raw data upfront without the need to even organize it.
- Machine Learning Model Training: Machine learning often requires storage of large, varied datasets to accurately train models.
- Data Exploration: Testing for hypotheses or new ideas is often better done with data lakes because analysts can now take their time to dig around when all the information is openly available, without the restrictions that come with a structured system.
When to Use Data Warehouse
When you need clean, structured data, a data warehouse is the right fit for your business. Here’s when this is needed:
- Business Intelligence (BI) Reporting: Some businesses need regular analysis and reporting to track daily performance, monitor KPIs, or any quick informed decision making.
- Historical Data Analysis: One reason why data warehouses are preferred over databases is that they store historical data, whereas databases just update information without no knowledge of the previous data. For example, if a staff member changes city from “Los Angeles” to “Oakland,” a database storage solution will only update to the new city, but a data warehouse will update the new city and still keep a record of the previous cities the staff member lived in.
- High-Performance Analytics for Structured Data: For businesses that need to run complex queries on structured data, data warehouses can optimize these tasks.
Combining Data Lake and Data Warehouse
As some businesses evolve, they realize that using just a data lake or a data warehouse can’t completely cover all their needs. That is where a data lakehouse comes in—combining the best features of the two storage solutions.
Data Lakehouse
A data lakehouse is a storage solution that combines the flexibility of a data lake with the structure and high-speed performance that a data warehouse excels at. The whole idea is to have a single storage solution where we can store raw data while still being able to organize, query, and report information as quickly as possible.
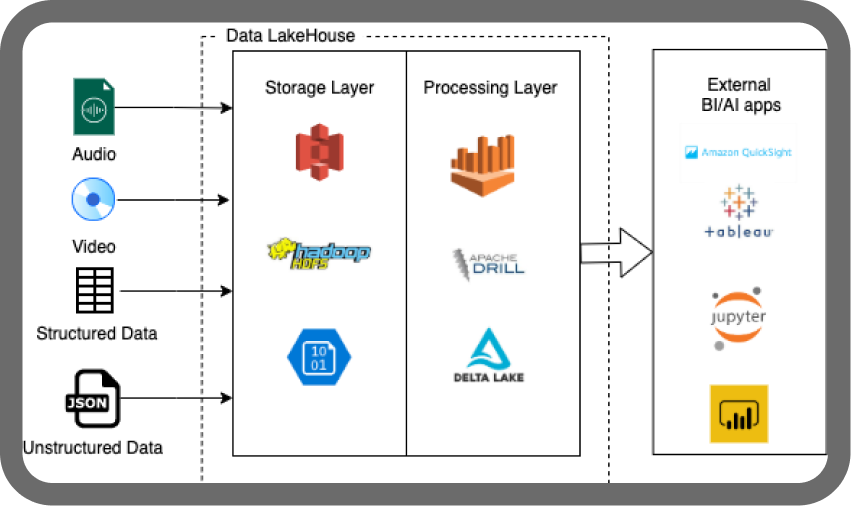
In this image, we see that a data lakehouse can accept all kinds of information, both structured and unstructured, such as audio, video, and databases. It processes this data and provides meaningful reports and insights for building applications like Jupyter Notebook, AI applications, Amazon QuickSight, and many more.
With a data lakehouse, there is no need to have any separate storage options; everything can fit in one place. Now, someone might ask: why is everyone not going for this wonderful storage solution? Well, it has its drawbacks too—one of them is that data-swamp is a common issue due to the complexity involved in trying to manage such a large storage system.
When to Consider a Hybrid Approach
When both flexibility and structure are needed, you might want to consider a hybrid approach to data storage. Here are those times:
- When Handling Diverse Data Types: If a company deals with both structured and unstructured types of data, like social media posts, transaction logs and imagery, a data lakehouse can be really useful for gathering and arranging everything in one place.
- When Balancing Data Exploration and Reporting: Many research companies want to explore raw forms of data in order to predict trends and patterns but also need fast, and organized reports for daily operations. In such times, a data lakehouse is ideal.
- When Supporting Machine Learning and Business Intelligence: A machine learning company could benefit from the flexibility that comes with a data lakehouse while still being able to report and show progress in business growth.
Conclusion
Choosing the best storage solution for your business can save you a lot of trouble in effectively managing or using data. Data lakes are best for storing large amounts of raw data, while data warehouses are preferred for analyzing structured data. Both have their strengths and weaknesses, as discussed in this article, to help you choose the best of both worlds.
Scale Seamlessly with OpenReplay Cloud
Maximize front-end efficiency with OpenReplay Cloud: Session replay, performance monitoring and issue resolution, all with the simplicity of a cloud-based service.
