JavaScript applications run on a single processing thread: a program can do one thing at a time. In simpler terms, a server with a 16-core CPU runs code on one core while 15 are idle.
Single threads avoid complex concurrency situations. What would happen if:
-
one browser thread added content to a DOM node while another deleted that element?
-
two or more browser threads attempted to redirect to different URLs?
-
two or more server threads attempted to update the same global variable simultaneously?
Languages such as PHP and Python also use a single thread. A multi-threaded web server launches a new instance of the interpreter for every request, so responses return in parallel.
Launching threads is resource-intensive, so Node.js applications provide their own web server. This runs on a single thread by default but does not necessarily cause performance problems because JavaScript is asynchronous:
-
Browser JavaScript does not need to wait for a user to click a button — the browser raises an event that calls a function when a click occurs.
-
Browser JavaScript does not need to wait for a response to a
Fetchrequest — the browser raises an event which calls a function when the server returns data. -
Node.js JavaScript does not need to wait for the result of a database query — the runtime raises an event that calls a function when data’s returned.
To achieve this, JavaScript has a non-blocking I/O event loop. Once the last statement of code has been executed, the runtime loops back, checks for outstanding timers, pending callbacks, and active data connections, and executes callback functions as necessary. Other OS threads handle input/output, such as HTTP requests, file reads, and database connections. They do not block the event loop, so other JavaScript code continues to run.
The JavaScript runtime has a single responsibility to run JavaScript code. The Operating System handles all other operations and returns results to the engine, which executes an associated callback. This tutorial describes how to avoid performance bottlenecks using parallel processing threads to execute long-running JavaScript functions.
Long-running JavaScript
JavaScript functions triggered by an event typically process the incoming data and output a result within milliseconds, so the event loop continues. A long-running function such as a complex calculation will block the event loop: no other JavaScript code will run until it completes:
-
In a browser, the user would be unable to interact with the page. They can not click, scroll, or type, and may encounter an “unresponsive script” error.
-
A Node.js, Deno, or Bun server application cannot respond to other requests as the function executes. One user triggering a 10-second calculation incurs a 10-second wait for every other user, regardless of their request.
Before 2012, JavaScript developers solved this problem by splitting calculations into smaller sub-tasks separated by a short setTimeout delay. It unblocked the event loop but wasn’t always practical, and a single thread was still used even when the CPU could do more. Modern JavaScript offers multi-threading via Web Workers.
Web workers
All browsers, Node.js, Deno, and Bun support Web Workers. They use a similar syntax, although server runtimes may provide advanced options.
A Web Worker is a script that runs as a background thread with its own engine instance and event loop. It runs parallel to the main execution thread and does not block the event loop.
The main thread — or a worker itself — can launch any number of workers. To spawn a worker script:
- The main (or another worker) thread posts a message to a new worker with all the necessary data.
- An event handler in the worker executes and starts processing the data.
- On completion (or failure), the worker posts a message back to the main thread with a calculated result.
- An event handler in the main thread executes, parses the incoming result, and runs necessary actions such as displaying values.
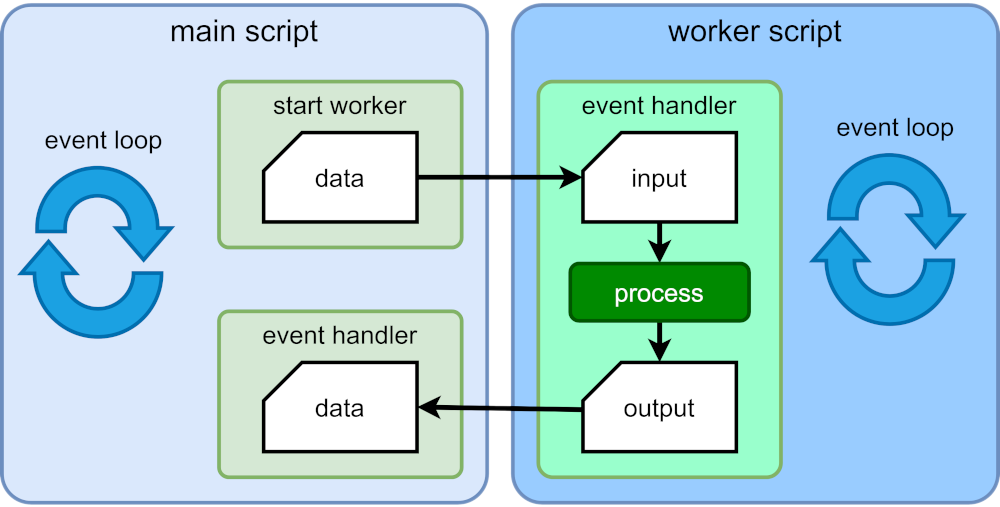
Workers are best used for JavaScript-based CPU-intensive tasks. They do not benefit intensive I/O work because that’s offloaded to the OS and runs asynchronously.
Client-side web worker restrictions
A worker cannot access data in other threads unless it’s explicitly passed to it. A copy of the data is passed to using JavaScript’s structured clone algorithm so it can include native types such as strings, numbers, Booleans, arrays, and objects but NOT functions or DOM nodes.
Browser workers can use APIs such as console, Fetch, XMLHttpRequest, WebSocket, and IndexDB. They can not access the document object, DOM nodes, localStorage, and some parts of the window object since this could lead to concurrency issues, as described above.
Most browsers support dedicated workers — a single script launched, used, and terminated by the main script.
Modern desktop browsers support shared workers — a single script accessible to multiple scripts in different windows, iframes, or workers which communicate over a unique port. Shared workers are not supported in most mobile browsers, so they’re impractical for most web projects.
Server-side web worker restrictions
Server workers also run in isolation and receive copies of data as they do in the browser. Worker threads in Node.js, Deno, and Bun have fewer API restrictions than browser workers because there’s no DOM. You could encounter issues if two or more workers wrote data to the same file simultaneously, but that’s unlikely.
You cannot pass complex objects such as database connections to workers since most will have methods and functions which are not cloned. You could:
- Asynchronously read all necessary data in the main thread and pass it to the worker for processing, or
- Connect to the database in the worker. This will have a start-up cost but may be practical if your function has to make further database queries during processing.
Using client-side web workers
Your main script must define a Worker object with the filename of the worker script (relative to the HTML file):
// main.js: run on worker thread
const worker = new Worker('./worker.js');Start the worker using its postMessage() method to send data such as an object:
// main.js: post data to worker
worker.postMessage({ a: 1, b: 2, c: 3 });This triggers an onmessage event handler function in the worker script. It receives the incoming data (e.data), processes it, and runs a postMessage() method to return data back to the main script before terminating:
// worker.js
onmessage = function(e) {
console.log(e.data); // { a: 1, b: 2, c: 3 }
const result = runSomeProcess(e.data);
// return to main thread
postMessage(result);
};This triggers an onmessage event handler function in the main script. It receives the incoming data (e.data) and can process or output it as necessary.
// main.js: receive data from worker
worker.onmessage = function(e) {
console.log(e.data); // result
};The main script can stop the worker at any time by calling its .terminate() method. It can also declare the following event handlers:
-
onmessageerror— fired when the worker receives a data it cannot deserialize, and -
onerror— fired when a JavaScript error occurs in the worker script. The returned event object provides error details in the.filename,.lineno, and.messageproperties.
Client-side worker demonstration
View a client-side web worker demonstration
This example has a main index.js script, which displays the current time and updates it up to 60 times per second. The start throwing button starts a dice throwing calculation which, by default, throws ten six-sided dice ten million times and logs the frequency of totals. The clock pauses while the calculation runs, and some browsers may throw an “unresponsive script” error.
Now check the use web worker checkbox and start again. This passes data to worker.js, which runs the same calculation in a background worker thread. The result may take a little longer because launching a worker has an overhead, but the clock continues to run in the foreground.
Including other scripts in a client-side worker
Browser web workers can not be ES modules (those using export and import syntax). You must use the importScripts() method to synchronously import other scripts into the worker’s scope:
// worker.js
importScripts('./library.js');Chrome-based browsers support worker ES modules if use a second argument of { type: "module" } in the constructor:
const worker = new Worker('./src/worker.js', { type: 'module' });You can then import libraries in the worker:
// worker.js
import { functionX } from './library.js';This functionality is not yet available in Firefox or Safari. Until greater support is available, you could use a JavaScript bundler such as esbuild or Rollup.js to resolve imports at build time and pack all worker code into a single file.
Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
Using server-side web workers
Server-side JavaScript runtimes also support workers:
-
Node.js implemented worker APIs in version 10.
-
Deno replicates the Web Worker API so the syntax is identical to browser code. It also offers a compatibility mode that polyfills Node.js APIs should you want to use that runtime’s worker thread syntax.
-
Bun is in beta, although it will support browser and Node.js worker APIs.
-
Serverless functions such as AWS Lambda, Azure functions, Google Cloud functions, Cloudflare workers, and Netlify edge functions may provide web worker-like APIs. There may be fewer benefits because a user request often launches a separate isolated instance.
To use workers in Node.js, the main script must define Worker object with the name of the worker script relative to the project root. A second constructor parameter defines an object with a workerData property containing the data you want to send:
const worker = new Worker('./worker.js', {
workerData: { a: 1, b: 2, c: 3 }
});Unlike browser workers, the worker starts, and there’s no need to run worker.postMessage(). You can call that method if necessary and send more data later — it triggers the worker’s parentPort.on('message') event handler:
// worker message handler
parentPort.on('message', e => {
console.log(e);
});Once the worker completes processing, it posts the resulting data back to the main thread using the following:
// worker.js: return result to main
parentPort.postMessage( result );This raises a message event in the main script, which receives the result:
// main.js: result received
worker.on('message', result => {
console.log( result );
});The worker terminates after sending the message. This also raises an exit event should you want to run clean-up or other functions:
worker.on('exit', code => {
//... clean up
});Other event handlers are also supported:
-
messageerror— fired when the worker receives data it cannot deserialize -
online— fired when the worker thread starts to execute, and -
error— fired when a JavaScript error occurs in the worker script.
Inline server-side worker scripts
A single Node.js script file can contain both the main and worker code. The script must check whether it’s running on the main thread using isMainThread and then call itself as a worker (perhaps using import.meta.url as the file reference in an ES module or __filename in CommonJS):
import { Worker, isMainThread, workerData, parentPort } from "node:worker_threads";
if (isMainThread) {
// main thread
// create a worker from this script
const worker = new Worker(import.meta.url, {
workerData: { a: 1, b: 2, c: 3 }
});
worker.on('message', msg => {});
worker.on('exit', code => {});
}
else {
// worker thread
const result = runSomeProcess( workerData );
parentPort.postMessage(result);
}This is faster and could be an option for small, self-contained, single-script projects. Larger projects will be easier to maintain if you separate worker script files.
Sharing data between threads
Communication between the main and worker threads incurs data serialization. It’s possible to share data between threads using a SharedArrayBuffer object representing fixed-length raw binary data. The following main thread defines 100 numeric elements from 0 to 99, which it sends to a worker:
// main.js
import { Worker } from "node:worker_threads";
const
buffer = new SharedArrayBuffer(100 * Int32Array.BYTES_PER_ELEMENT),
value = new Int32Array(buffer);
value.forEach((v,i) => value[i] = i);
const worker = new Worker('./worker.js');
worker.postMessage({ value });The worker can receive the value object:
// worker.js
import { parentPort } from 'node:worker_threads';
parentPort.on('message', value => {
value[0] = 100;
});Either the main or worker threads can change elements in the value array, and they will update on both sides. This could improve performance, but there are downsides:
- You can only share integer data.
- It may still be necessary to alert the other thread about a change.
- There’s a risk two threads could update the same value at the same time and lose synchronization.
Node.js child processes
Node.js supported child processes before workers. A child process launches another application, passes data, and receives a result. They operate similarly to workers but are generally less efficient and more process-intensive.
Workers are best used when running complex JavaScript functions — probably within the same project. Child processes become necessary when launching another application, such as a Linux or Python command.
Node.js clustering
Node.js clusters allow you to fork identical processes to handle loads more efficiently. The initial primary process can fork itself — perhaps once for each CPU as returned by os.cpus(). It can also handle restarts when an instance fails and broker communication messages between forked processes.
The cluster standard library offers properties and methods, including:
-
.isPrimary: returnstruefor the main primary process -
.fork(): spawns a child worker process -
.isWorker: returnstruefor worker processes.
This example starts a web server worker process for each CPU/core. A 4-core machine will spawn four instances of the web server so it can handle up to four times the load. It also restarts any failed processes, so the application is more resilient:
// app.js
import cluster from 'node:cluster';
import process from 'node:process';
import { cpus } from 'node:os';
import http from 'node:http';
const cpus = cpus().length;
if (cluster.isPrimary) {
console.log(`Started primary process: ${ process.pid }`);
// fork workers
for (let i = 0; i < cpus; i++) {
cluster.fork();
}
// worker failure event
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${ worker.process.pid } failed`);
cluster.fork();
});
}
else {
// start HTTP server on worker
http.createServer((req, res) => {
res.writeHead(200);
res.end('Hello!');
}).listen(8080);
console.log(`Started worker process: ${ process.pid }`);
}All processes share port 8080, and any can handle an incoming HTTP request. The log when running the applications shows something like:
$ node app.js
Started primary process: 1000
Started worker process: 2000
Started worker process: 3000
Started worker process: 4000
Started worker process: 5000
worker 3000 failed
Started worker process: 6000Few Node.js developers attempt clustering. The example above is simple and works well, but code can become increasingly complex as you attempt to handle messages, failures, and restarts.
Process managers
A process manager can run multiple instances of one Node.js application without you having to write cluster code. The most popular Node.js option is PM2, which can launch an instance of your application on every CPU/core and restart any on failure:
pm2 start ./app.js -i maxApplication instances start in the background, so it’s ideal for live server deployments. You can examine which processes are running by entering pm2 status :
$ pm2 status
┌────┬──────┬───────────┬─────────┬─────────┬──────┬────────┐
│ id │ name │ namespace │ version │ mode │ pid │ uptime │
├────┼──────┼───────────┼─────────┼─────────┼──────┼────────┤
│ 1 │ app │ default │ 1.0.0 │ cluster │ 1000 │ 4D │
│ 2 │ app │ default │ 1.0.0 │ cluster │ 2000 │ 4D │
└────┴──────┴───────────┴─────────┴─────────┴──────┴────────┘PM2 can also run non-Node.js applications written in other languages.
Container management systems
Clusters and process managers run an application on a specific device. If your server or OS fails, your application will fail regardless of the number of instances.
Containers are similar to virtual machines, except they emulate an Operating System rather than hardware. It’s a lightweight wrapper around a single application with all necessary OS, library, and executable files. A single container can run your application in an isolated instance of Node.js, and one or more devices can run multiple containers.
Well-known container solutions include Docker and Kubernetes which can launch and monitor any number of containers across any number of devices even in different locations.
Conclusion
Web Workers run in parallel to the main thread’s event loop, so they’re ideal for long-running calculations or dangerous activities which could terminate unexpectedly.
Using workers is straight-forward but remember:
-
Workers are less necessary for intensive but asynchronous I/O tasks such as HTTP requests and database queries.
-
Starting a worker has a performance overhead.
-
Process and container management may be a better solution than multi-threading.
More information:
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.