コードメトリクス解説:循環的複雑度(Cyclomatic Complexity)とは?
JavaScriptの循環的複雑度を、例、計算式、ESLintやSonarQubeでの測定方法と分岐ロジックの減らし方まで解説。

プルリクエストをレビューしていると、ある関数が肥大化し、8つもの異なる条件(ユーザーロール、フィーチャーフラグ、エッジケース、フォールバック)を扱うようになっていることに気づきます。テストはパスしています。動作もします。しかし、何か違和感があります。その違和感には名前があり、そして数値もあります。
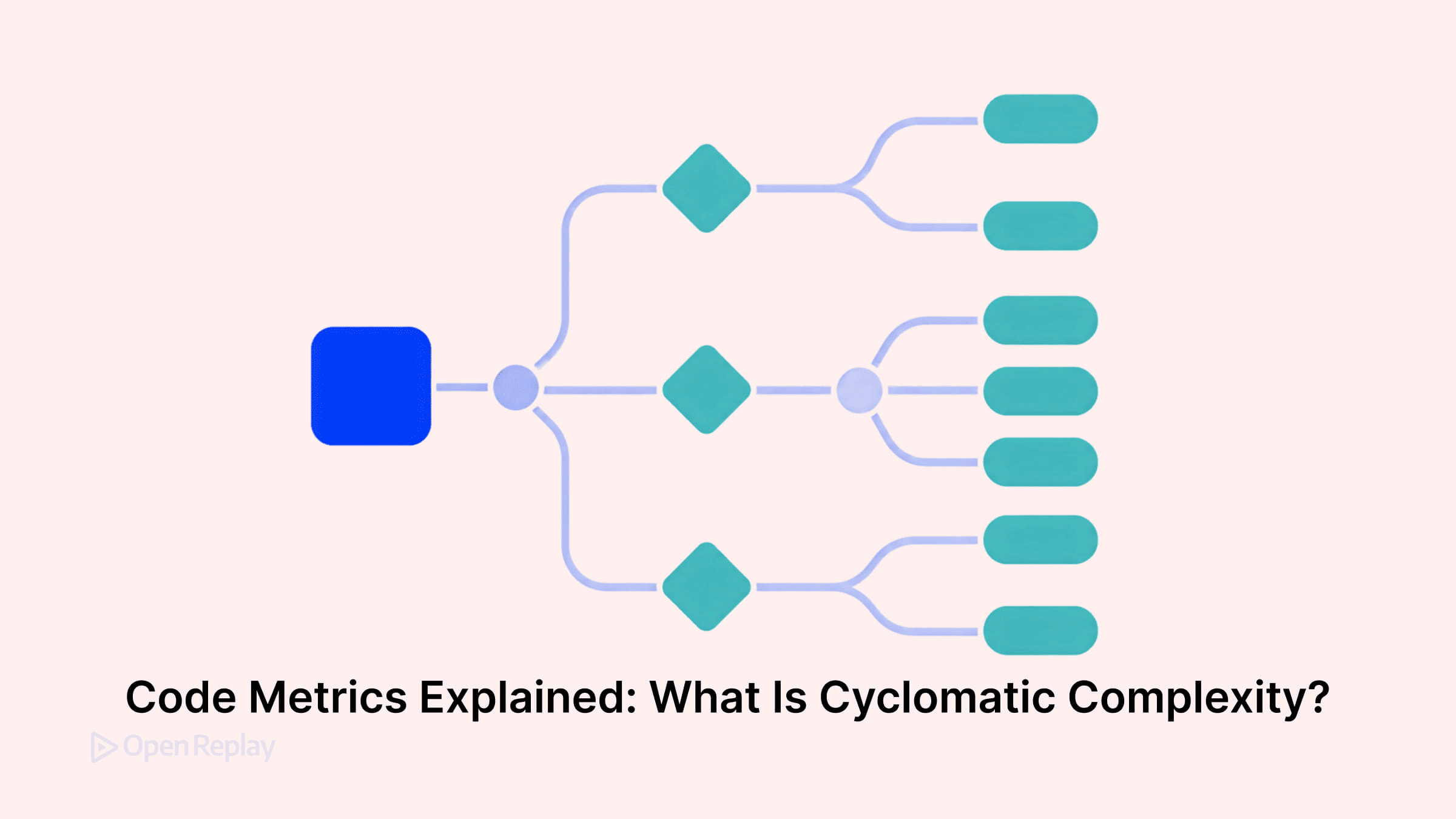
循環的複雑度(Cyclomatic Complexity)は、関数を通る独立した実行経路がいくつ存在するかを測定するコード品質メトリクスです。この数値が高いほど、コードに含まれる分岐ロジックが多くなり、読みやすさ・テスト容易性・保守性が低下していきます。
要点
- 循環的複雑度は関数を通る独立経路の数をカウントし、分岐ロジックを計測可能なシグナルとして提供します。
- 計算方法は簡単で、1から始めて
if、&&、||、case、三項演算子などの分岐文ごとに1を加算します。 - 認知的複雑度(Cognitive Complexity)とは異なり、こちらは人間にとってのコードの読みにくさではなく、経路の数を測定します。
- ESLint や SonarQube などのツールを使えば複雑度を自動追跡し、設定したしきい値を超える関数をフラグできます。
- ガード節、ヘルパー関数の抽出、説明的なブール変数、ルックアップテーブルを活用することで複雑度を削減できます。
循環的複雑度はどう計算されるか
1976年に Thomas McCabe によって考案されたこのメトリクスは、関数の制御フローグラフから導出されます。単一の連結成分に対する実用的な式は以下の通りです:
M = E − N + 2P
ここで、E はエッジ数、N はノード数、P は連結成分の数(単一関数では通常1)、M は複雑度スコアです。
ほとんどの JavaScript 開発者は、これを手動で計算する必要はありません。簡単な方法としては、1から始めて、分岐文ごとに1を加算する ことです — if、else if、&&、||、for、while、case、三項演算子、catch 句が対象です。ツールによっては、オプショナルチェーン、デフォルト値、論理代入などの構文もカウントします。具体的な計算ルールは ESLint や SonarQube などのツールによって若干異なります。
JavaScript の例:分岐が複雑度を上げる仕組み
// Cyclomatic complexity: 1
function getDisplayName(user: User): string {
return user.name;
}// Cyclomatic complexity: 6
function getDisplayName(user: User | null): string {
if (!user) return "Guest"; // +1
if (user.isAdmin) return "Admin"; // +1
if (user.displayName) return user.displayName; // +1
if (user.firstName && user.lastName) // +1 (if) +1 (&&)
return `${user.firstName} ${user.lastName}`;
return user.email;
}条件が増えるたびに分岐が追加されます。分岐が多くなるほどテストすべき経路が増え、将来の変更が予期せぬ箇所を壊す可能性も高まります。
このパターンはフロントエンドのコードで頻繁に登場します:React コンポーネントのレンダリングロジック、多くの action type を扱う Redux のリデューサー、フォームバリデーションハンドラー、権限ベースの UI フローなどです。
循環的複雑度 vs. 認知的複雑度
これらは関連していますが異なるメトリクスです。循環的複雑度 は構造的な分岐をカウントするもので、テスト容易性のシグナルです。認知的複雑度(SonarQube によって広まった概念)は、コードが人間にとってどれだけ読みにくいかを測定し、ネストや非線形フローをより重く評価します。
ある関数が循環的複雑度では低スコアでも、依然として理解しづらいことがあります — 例えば、中間変数のない深いメソッドチェーンなどです。両方のメトリクスとも有用であり、片方だけでは全体像を捉えきれません。

Discover how at OpenReplay.com.
JavaScript コードベースでの計測方法
フロントエンドチームに有用な2つのツール:
- ESLint の
complexityルール — 設定可能なしきい値を超える関数をエディタ上で直接フラグします - SonarQube / SonarCloud — コードベース全体について、循環的複雑度と認知的複雑度の両方をレポートします
ESLint は次のように設定します:
{
"rules": {
"complexity": ["warn", { "max": 10 }]
}
}しきい値は設定可能であり、調整すべきです。バリデーションユーティリティと Redux リデューサーで同じ上限を設ける必要はありません。普遍的なルールにこだわるのではなく、コードの文脈に合わせてしきい値を調整しましょう。
不要な複雑度を減らす実践的な方法
関数のスコアが上昇したときに役立つテクニック:
- 関数を抽出する — 個別のロジックを名前付きヘルパーに切り出す
- ガード節を使う — 条件をネストせずに早期リターンする
- 条件式を単純化する — 複雑なブールチェーンを説明的な変数に置き換える
- ルックアップテーブルを使う — 長い
switch文をオブジェクトやMapに置き換える
目的はスコアそのものを低くすることではありません。テストしやすく、変更しやすく、次の開発者が理解しやすいコードを目指すことです。
まとめ
循環的複雑度は、コード内の分岐ロジックに関する具体的で計測可能なシグナルを提供します。ESLint や SonarQube で追跡し、コードベースに適したしきい値を設定し、スコアの上昇は危機としてではなくリファクタリングのきっかけとして捉えましょう。認知的複雑度と組み合わせることで、保守性のより包括的な視点が得られます。
FAQ
循環的複雑度の良いスコアとは?
一般的なガイドラインとして、関数を10以下に保つことが推奨されます。1〜10は管理可能、11〜20は関数が複雑化しつつあるサイン、20を超えるとリファクタリングの強力な候補とされます。適切なしきい値はコードの種類に依存するため、チームの状況に合わせて調整してください。
循環的複雑度はネストされた条件を含みますか?
循環的複雑度は、ネストの深さに関係なく各分岐文を均等にカウントします。フラットな3つの if 文を持つ関数と、3つのネストされた if 文を持つ関数は同じスコアになる可能性があります。これが認知的複雑度が存在する理由の一つで、認知的複雑度はネストに追加の重みを加え、コードの読みにくさをより正確に反映します。
しきい値を超えた関数はすべてリファクタリングすべきですか?
必ずしもそうではありません。高スコアは関数を詳しく見るべきサインですが、パーサー、ステートマシン、バリデーションパイプラインなど、本質的に分岐の多いロジックも存在します。このメトリクスは厳格なルールではなく、レビューのきっかけとして使ってください。十分にテストされ、明確に書かれ、安定している関数であれば、リファクタリングが実質的な利益なしにリスクを増やすこともあります。
循環的複雑度はコード行数とどう違いますか?
コード行数はサイズを測定するのに対し、循環的複雑度は決定ポイントを測定します。分岐のない200行の関数の複雑度は1ですが、条件だらけの20行の関数ははるかに高いスコアになる可能性があります。複雑度はテストが網羅すべき経路の数を反映するため、テスト容易性や保守工数のより良い予測指標となります。
Gain control over your UX
See how users are using your site as if you were sitting next to them, learn and iterate faster with OpenReplay — the open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data.
Star on GitHub12k