ハーネスとは、モデル本体以外のすべてのコード、設定、実行ロジックの総称です。具体的には、オーケストレーションループ、ツール、メモリ、コンテキスト管理、状態管理、エラーハンドリング、ガードレール、検証チェックが含まれ、これらが組み合わさってエージェントの成否を決定します。OpenAIやAnthropicのSDKを使ってLLM機能をリリースし、ループが発生したり、ツール呼び出しのハルシネーションが起きたり、3ターン前のユーザー発言を忘れたりする場面に遭遇したことがあれば、すでに薄いハーネスの限界に直面しています。そして多くの場合、問題はモデルにあるのではありません。
本記事では、ハーネスの正確なメンタルモデル、モデル選択よりもハーネスが結果の分散に大きく影響するという根拠、エンドツーエンドで読める実行可能なJS/TSハーネスの実装例、そしてフロントエンドチームがプロダクト内のAI機能をリリースする際に実際に担う4つの意思決定について解説します。
重要なポイント
- ハーネスとはモデル本体以外のすべてのコード、設定、実行ロジックのことです。LangChainのVivek Trivedy氏は「モデルでなければ、それはハーネスだ」と表現しています。
- Vercelのv0チームはエージェントのツールを80%削除したところ、タスク成功率が80%から100%に上昇し、平均トークン使用量が37%減少しました。モデルは変更していません。
- Princeton HALのCORE-Bench Hardリーダーボードでは、Claude Opus 4.5がCORE-Agentで42.22%、Claude Codeで77.78%のスコアを記録しており、同一モデルでスキャフォールドによって35.56ポイントの差が生じています。
- ハーネス対モデルの議論は決着していません。Scale AIのSWE-Atlasはスキャフォールドの効果がモデルによって異なることを示しており、METRはClaude CodeとCodexが時間軸評価において独自のデフォルトスキャフォールドと比較して統計的に有意な差がなかったと報告しています。
- すべてのハーネスには、ユーザーに出力を返す前に少なくとも1つの決定論的チェック(テスト、スキーマバリデーター、正規表現など)が必要です。
エージェントハーネスとは何か?
エージェントハーネスとは、LLM呼び出しをラップする完全なソフトウェアシステムです。モデルを呼び出すタイミングを決定するオーケストレーションループ、モデルが呼び出せるツール、モデルが参照するメモリとコンテキスト、ターン間で保持される状態、そして出力をゲートするガードレールと検証チェックで構成されます。定義の起点となる表現はLangChainのVivek Trivedy氏によるもので、「モデルでなければ、それはハーネスだ」というものです。モデルはトークンを生成し、ハーネスはそのトークンを信頼性の高い機能へと変換するすべてのものです。
この関係を理解するうえで最もわかりやすいメンタルモデルは、Beren Millidge氏が2023年のエッセイでスキャフォールド型LLMシステムを自然言語コンピューターとして捉えたフレームワークです。LLMはCPUに対応し、プロンプトとコンテキストウィンドウはRAM(高速だが容量が限られる)に対応し、ベクターデータベースなどの外部メモリはディスクストレージに対応します。ツールは外部世界にアクセスするデバイスドライバーとして機能し、ハーネスはそれらすべてを調整するオペレーティングシステムです。OSのないCPUは何も有用な計算ができません。モデルは必要条件ですが、十分条件ではないのです。
この分野では用語が乱立しているため、ここで整理しておきます。モデルはLLM、つまり重みとAPIです。ハーネス(スキャフォールドとも呼ばれる)は周囲のコードです。エージェントは創発的な振る舞いであり、ユーザーが対話する目標指向でツールを使用し自己修正する実体です。Hugging Face Agents Courseでは、エージェントをAIモデルを使って環境と対話し、ユーザー定義の目標を達成するシステムと定義しています。「エージェントを作った」と言う場合、実際にはハーネスを作ってモデルに向けたということです。Anthropic自身のClaude Agent SDKの発表でも、Claude Code SDKを「Claude Codeを動かすエージェントハーネス」と表現しています。
なぜラッパーはモデルよりも重要なのか?

Discover how at OpenReplay.com.
ラッパーがモデルよりも重要な理由は、同じモデルでも異なるハーネスの背後では大きく異なる結果が生まれるからです。そのデルタは大きく、繰り返し観測され、公開ベンチマークで計測されています。最も強力なデータポイントは、Vercelのv0チームがエージェントのツールを80%削除した事例です。モデルを変えることなく、タスク成功率が80%から100%に上昇し、平均トークン使用量が37%減少し、最悪ケースのクエリ処理時間が724秒から141秒に短縮されました。修正はすべてハーネス側で行われ、ツールをより少なく、より適切なスコープに絞り込んだものでした。
同じ方向を示す結果がさらに2つあります。LangChainは自社のブログ記事によると、モデルを変えずにハーネスのみを変更することで、コーディングエージェントをTerminal-Bench 2.0のトップ30圏外からトップ5に引き上げたと報告しています。また、Princeton HALのCORE-Bench Hardリーダーボードでは、Claude Opus 4.5がCORE-Agentスキャフォールドで42.22%、Claude Codeで77.78%を記録しており、同一モデルで35.56ポイントの差が生じています。なお、リーダーボードではClaude Codeの実行について手動検証で95.5%という数値も報告されています。
| 事例 | モデル変更 | ハーネス変更 | 変更前 | 変更後 |
|---|---|---|---|---|
| Vercel v0 | なし | あり(ツール80%削減) | 成功率80% | 成功率100%、トークン37%減 |
| LangChain / Terminal-Bench 2.0 | なし | あり | トップ30圏外 | トップ5 |
| Princeton CORE-Bench Hard | なし(Opus 4.5) | あり(スキャフォールド) | 42.22% | 77.78% |
この議論は決着していないため、単純化しすぎると信頼性を損ないます。Scale AIのSWE-Atlasは、ファーストパーティのコーディングエージェントスキャフォールドと最小限のmini-SWE-agentを比較し、スキャフォールドの効果がモデルによって異なることを示しており、ネイティブスキャフォールドが最小限のベースラインに対して顕著な改善をもたらすケースもあります。一方、METRはClaude CodeとCodexが時間軸評価において独自のデフォルトスキャフォールドと比較して統計的に有意な差がなかったと報告しています。どちらの効果も実在しており、どちらが支配的かはタスクの性質によって異なります。MongoDBが述べているように、「LLMは最も小さな部分だ」というのが正直な読み方ですが、ハーネスによる改善には上限があり、弱いタスクに強力なモデルを使っても、スキャフォールドで補える範囲には限界があります。
LLMハーネスのコンポーネントとは何か?
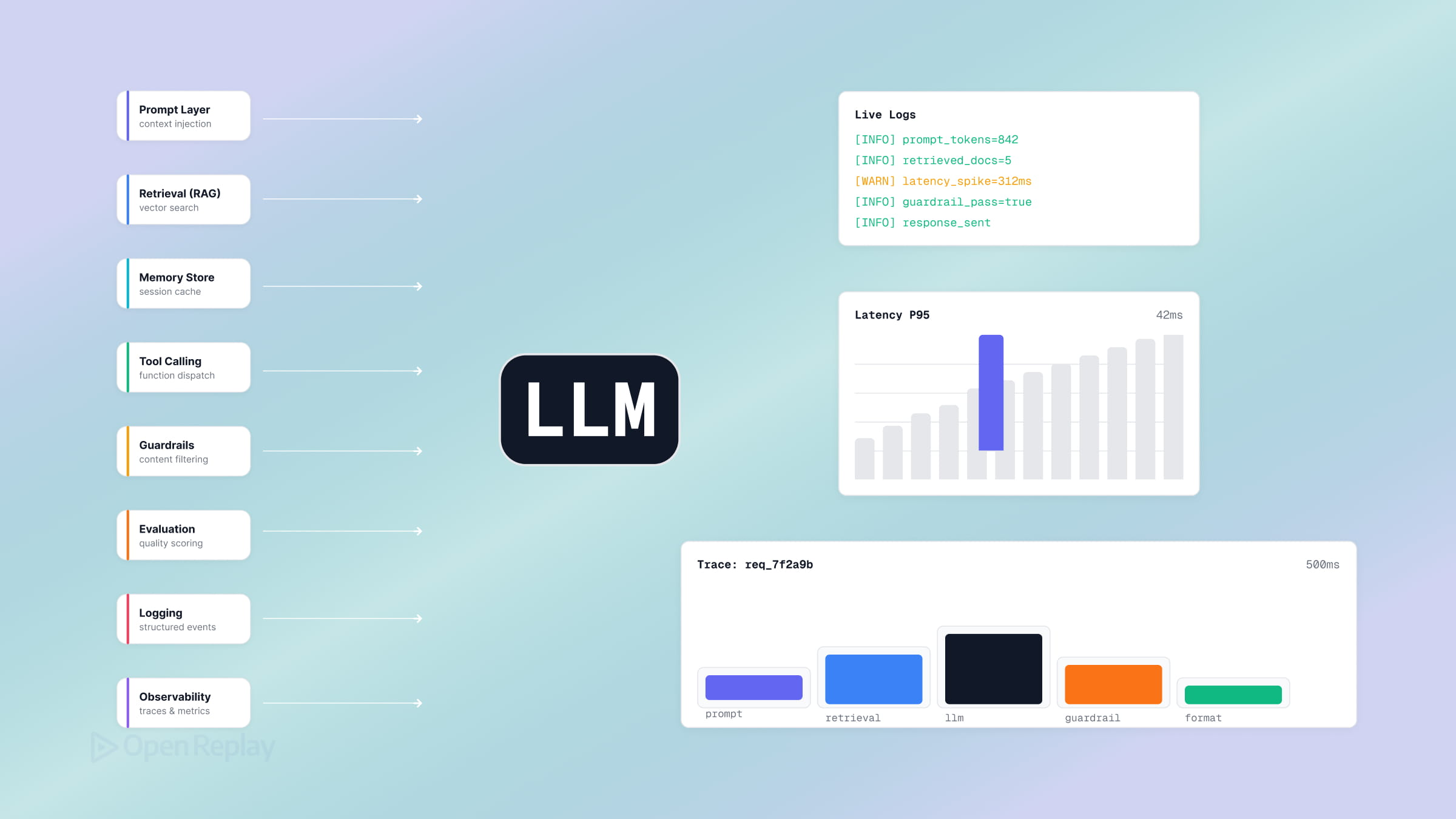
本番環境のハーネスは8つのコンポーネントに分解でき、それぞれが薄いラッパーが失敗しうる箇所です。オーケストレーションループ、ツール、メモリ、コンテキスト管理、プロンプト構築、状態管理、エラーハンドリング、そしてガードレールと検証ループです。
オーケストレーションループ。 ループはThought–Action–Observationサイクル(ReActパターン)を実装します。モデルを呼び出し、ツールのリクエストがあるか確認し、ツールを実行し、結果をフィードバックし、モデルが回答するかガードが発動するまで繰り返します。Claude Codeのリバースエンジニアリング分析でVikash Rungta氏が述べているように、ランタイムは「単純なループ」であり、すべての知性はモデルに宿り、ハーネスはターンを管理するだけです。機械的にはターン上限付きのwhileループです。
ツール。 ツールはエージェントの「手」であり、スキーマ(名前、説明、パラメーター型)としてモデルに公開される関数です。ツール層は登録、引数の検証、実行、そして結果をモデルが読める観測値としてフォーマットすることを担います。ヘルプウィジェットのsearch_docsツールも、get_order_statusもツールです。
メモリ。 短期メモリは現在の会話であり、長期メモリはセッションをまたいで保持されます。チャットウィジェットでは、短期メモリは各ターンで再生するメッセージ配列であり、長期メモリはセッション開始時にロードするユーザーごとのサマリーかもしれません。
コンテキスト管理。 希少なリソースはコンテキストウィンドウであり、失敗パターンはコンテキストの劣化です。ウィンドウが低シグナルのトークンで埋まると品質が低下します。Anthropicのコンテキストエンジニアリングガイダンスによると、目標は最小限の高シグナルトークンセットです。戦略としては、コンパクション(古いターンを要約する)とジャストインタイム検索(事前ロードではなくオンデマンドで取得する)があります。
プロンプト構築。 ハーネスは入力を階層的に組み立てます。システムプロンプト、ツール定義、メモリ、会話履歴、現在のメッセージの順です。順序は重要であり、重要なコンテキストはウィンドウの先頭と末尾に配置します。
状態管理。 状態とは、ターンやクラッシュをまたいで生き残るもの、つまりマルチステップタスクにおけるエージェントの位置、中間出力、チェックポイントです。ユーザーが以前に述べた制約を「忘れる」チャットウィジェットは、モデルの問題ではなく状態とコンテキスト管理の問題です。
エラーハンドリング。 1ステップあたり99%の成功率を持つ10ステップのタスクは、エラーが複合するためエンドツーエンドの成功率は約90%にしかなりません。重要なパターンは、ツールエラーを例外としてスローしてランを終了させるのではなく、観測値としてモデルに返すことで自己修正を可能にすることです。
ガードレールと検証ループ。 ガードレールはエージェントが行えることを制約し、検証ループは生成した内容をチェックします。Martin Fowler氏とBirgitta Böckeler氏のハーネスエンジニアリングに関する記事では、検証をガイド(フィードフォワード:行動前に誘導する)とセンサー(フィードバック:観察して自己修正する)に分類し、さらに計算的(決定論的:テスト、リンター)と推論的(LLM-as-judge)なコントロールに分けています。
JavaScriptでエージェントハーネスを構築するには?
最小限かつ完全なハーネスは、ターン上限付きのReActループ、適切にスコープされた1つのツール、エラーを観測値として扱うハンドラー、そして1つの決定論的検証チェックで構成されます。以下の例ではAnthropic SDKとZodをスキーマバリデーションに使用しています。検証チェックは多くの薄いラッパーが省略する部分ですが、これなしではエージェントは自分が間違っていることを知る手段がありません。
import Anthropic from "@anthropic-ai/sdk";
import { z } from "zod";
const client = new Anthropic();
// ツールは1つ、スコープを絞る。ツールが少ないほど不要な呼び出しが減る。
const tools: Anthropic.Tool[] = [
{
name: "get_order_status",
description: "Look up the status of an order by its numeric ID.",
input_schema: {
type: "object",
properties: { orderId: { type: "number" } },
required: ["orderId"],
},
},
];
// 決定論的検証:モデルのツール入力はこのスキーマに一致しなければならない。
const OrderArgs = z.object({ orderId: z.number().int().positive() });
async function runOrder(orderId: number) {
// 実際のルックアップの代替。
return { orderId, status: "shipped", eta: "2026-03-04" };
}
export async function harness(userMessage: string) {
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: userMessage },
];
// ターン上限ガード:ループ防止のための最重要安全レール。
for (let turn = 0; turn < 6; turn++) {
const res = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: "You are an order-status assistant. Use tools when asked about orders.",
tools,
messages,
});
const toolUse = res.content.find(
(b): b is Anthropic.ToolUseBlock => b.type === "tool_use"
);
if (!toolUse) return res.content; // ツール呼び出しなし → モデルが回答した。
messages.push({ role: "assistant", content: res.content });
let observation: string;
const parsed = OrderArgs.safeParse(toolUse.input);
if (!parsed.success) {
// 検証失敗:エラーを観測値として返す。スローしない。
observation = `Invalid arguments: ${parsed.error.message}`;
} else {
try {
observation = JSON.stringify(await runOrder(parsed.data.orderId));
} catch (e) {
observation = `Tool error: ${(e as Error).message}`; // これも観測値
}
}
messages.push({
role: "user",
content: [{ type: "tool_result", tool_use_id: toolUse.id, content: observation }],
});
}
return [{ type: "text", text: "Could not complete the request." }];
}この約50行のコードにある4つの設計上の選択が、信頼性の大部分を担っています。ターン上限付きのforループはオーケストレーションループであり、ループ防止ガードでもあります。ツールを1つに絞ることでツールスキーマを小さく保ちます。ZodのsafeParseは、ハルシネーションされた引数がバックエンドに到達する前に検出する決定論的検証チェックです。そして検証失敗とランタイムエラーの両方を観測値として返すことで、ランを終了させるのではなくモデルが自己修正できるようにしています。AnthropicのツールUseの仕組みはツールUseガイドに記載されており、OpenAI SDKでの同等のループはtool_callsとrole: "tool"メッセージを使用します。
なぜフロントエンド開発者は自分が思う以上にハーネスを担っているのか?
フロントエンド開発者は、AIチャットウィジェット、プロダクト内検索アシスタント、コパイロットUIをリリースする際にすでにハーネスを担っています。ただし、エージェント型のものより薄いハーネスです。ユーザーが不満を言う失敗のほとんど(ループ、ツール呼び出しのハルシネーション、コンテキストの忘却、制約の無視)はハーネスの失敗であり、モデルの失敗ではありません。フロントエンドチームがAI機能をリリースする際、モデルの選択は多くの意思決定の一つに過ぎず、ハーネスに関する意思決定(ツールのスコープ、どのコンテキストを保持するか、何を検証するか)は通常、それが受けるべき設計レビューよりも少ない注目しか集めていません。
対応関係は明確です。アシスタントが同じ誤った回答を「再生成」し続けるのを見るユーザーは、検証のないオーケストレーションループを目撃しています。2ターン後に述べた制約が消えてしまうユーザーは、状態とコンテキスト管理のギャップを目撃しています。ゴミの引数でツール呼び出しが発生し、わかりにくい返答が返ってくるのは、スキーマチェックの欠如、つまり上記のsafeParseステップの欠如です。これらはいずれもモデルを交換しても解決しません。すでに担っているラッパーを締め直すことで解決します。
ハーネスはどれくらい厚くすべきか?フロントエンドチームが担う4つの意思決定
プロダクト内のAI機能をリリースするフロントエンドチームが実際にコントロールするハーネスの意思決定は4つです。ツールのスコープ設定、コンテキスト戦略、検証ループ、そしてハーネスの厚さです。フィールド全体のより広いリスト(シングルエージェント対マルチエージェント、ReAct対プランアンドエグゼキュート、権限管理、永続的実行、フリートガバナンス)は、ほとんどのチャットウィジェットが到達しないインフラ層に位置します。
-
ツールのスコープ設定 — 10個未満のツールから始め、慎重に拡張する。 エージェントに必要以上のツールを与えると、パフォーマンスが確実に低下します。追加のツールスキーマごとにコンテキストを消費し、不要な呼び出しの確率が上がるためです。Vercelの事例がその根拠です。ツールの80%を削除することですべての指標が改善しました。
-
コンテキスト戦略 — ウィンドウへの詰め込みではなく、コンパクションとジャストインタイム検索を活用する。 ナレッジベース全体をプロンプトに事前ロードしないでください。ウィンドウの上限に近づいたら古いターンを要約し、ドキュメントはオンデマンドで取得します。Anthropicのコンテキストエンジニアリングガイダンスでは、目標を最小限の高シグナルトークンセットと定義しています。
-
検証ループ — すべてのハーネスは、ユーザーに出力を返す前に少なくとも1つの決定論的チェックが必要。 スキーマバリデーター、正規表現、ユニットテストなど、モデル自身の判断に依存せずにハーネスが実行できるものが必要です。これなしではエージェントは自分が間違っていることを知る手段がありません。Böckeler氏の計算的/推論的分類に従い、安価な計算的チェックから始め、意味的な正確さが必要な場合にのみLLM-as-judgeを追加します。
-
ハーネスの厚さ — 薄く始め、失敗パターンが繰り返されたときにのみ構造を追加する。 まだ見ていない失敗に備えてオーケストレーションを事前構築しないでください。特定の失敗が2回以上発生したときに、リトライ、ガードレール、または検証ステップを追加します。
本番環境でのAI機能のセッションリプレイを見ることは、ハーネスの品質をユーザー行動から読み取る最も速い方法の一つです。診断シグネチャはモデルレベルのテレメトリなしに可視化できるからです。同じリクエストを繰り返し言い換えるのは、コンテキストの喪失または検証ループが発動していないシグナルです。マルチステップタスクの途中での離脱は、飲み込まれたツールエラーが曖昧な返答として表面化していることが多いです。コピーして編集する行動は検証ギャップのシグナルであり、ハーネスのチェックは通過したがユーザーの基準を満たさなかった出力を示しています。「再生成」や「もう一度試す」の繰り返しクリックは、自分の失敗状態を検出できないループするハーネスのシグネチャです。
ハーネス設計はどこへ向かっているのか?
モデルは今やハーネスをループに組み込んだ状態でポストトレーニングされています。LangChainがエージェントハーネスアーキテクチャの議論で述べているように、Claude CodeやCodexなどのプロダクトはモデルトレーニングとハーネス設計をフィードバックサイクルで組み合わせています。これはハーネスがもはや交換可能なラッパーではなく、プロダクトサーフェスと共進化した部分になっていることを意味します。ビルダーへの示唆は、ハーネスが汎用アダプターではなく、設計するプロダクトの一部になりつつあるということです。
これにより、スキャフォールドの比喩から引き出したクリーンな将来性テストが得られます。設計が同じハーネスでより強力なモデルとともにきれいにスケールアップするなら、それは健全な設計です。モデルが改善するにつれてより多くのスキャフォールドで補う必要があるなら、ハーネスはモデルまたはタスクの問題を隠蔽しており、別の場所で修正すべきです。スキャフォールドは建設現場のものと同様に、構造が自立したときに取り外されるべきものです。
AI機能がループしたり、忘れたり、自信を持って間違ったものを返したりするとき、モデルを調査する前にハーネスを調査してください。上記の4つの意思決定(ツールのスコープ、コンテキスト戦略、1つの決定論的チェック、そして厚さ)から始め、失敗が繰り返されなくなるための最小限の構造を追加してください。
FAQ
ハーネスとスキャフォールドの違いは何ですか?
実際にはこれらの用語は同義語として使われています。どちらも、モデル本体以外のモデルを取り巻くすべてのコード、設定、実行ロジックを指します。「スキャフォールド」はPrincetonのCORE-AgentとClaude Codeスキャフォールドの比較など、ベンチマーク文献でより一般的な用語です。一方「ハーネス」は本番環境やSDKのコンテキストで好まれます。LangChainのVivek Trivedy氏はこの区別を「モデルでなければ、それはハーネスだ」というルールで解消しています。
ハーネスでツールエラーをモデルに返すべきか、スローすべきか?
エラーはスローするのではなく、観測値としてモデルに返してください。スローするとランが終了しますが、エラーをツール結果として返すことでモデルは何が問題だったかを確認し、次のターンで自己修正できます。これが重要な理由は、マルチステップタスクではエラーが複合するからです。1ステップあたり99%の成功率を持つ10ステップのタスクは、エンドツーエンドで約90%の成功率に低下します。スキーマバリデーション失敗とランタイム例外の両方を観測値としてフィードバックし、未処理のスローとして扱わないようにしてください。
ツールを増やすとエージェントのパフォーマンスは向上しますか?
いいえ、ある時点を超えてツールを増やすとパフォーマンスは確実に低下します。各ツールスキーマはコンテキストウィンドウのトークンを消費し、不要または不正確なツール呼び出しの確率を高めます。Vercelのv0チームはエージェントのツールを80%削除したところ、同じモデルでタスク成功率が80%から100%に上昇し、平均トークン使用量が37%減少しました。実践的なルールは10個未満のツールから始め、実際のギャップが現れたときにのみ拡張することです。
変更なしに同じハーネスでモデルを入れ替えることはできますか?
ますます難しくなっています。LangChainがエージェントハーネスアーキテクチャの議論で述べているように、Claude CodeやCodexなどのプロダクトはモデルトレーニングとハーネス設計をフィードバックサイクルで組み合わせています。これによりハーネスは汎用アダプターではなく、プロダクトサーフェスと共進化した部分となっています。有用な将来性テストは、設計が同じハーネスでより強力なモデルとともにきれいにスケールアップするかどうかです。モデルが改善するにつれてより多くのスキャフォールドで補う必要があるなら、ハーネスはより深い問題を隠蔽しています。