
リレーショナルデータベース設計の基礎

ほとんどのデータベース問題は、悪いクエリによって引き起こされるのではなく、悪いスキーマによって引き起こされます。テーブルが最初から不適切に構造化されている場合、どれだけ巧妙なSQLを使っても完全に補うことはできません。この記事では、リレーショナルデータベース設計の中核となる原則を取り上げます:テーブルの構造化方法、キーの定義、リレーションシップのモデリング、そしてデータの信頼性を保つための制約の使用方法について説明します。
重要なポイント
- リレーショナルデータベースは、情報を複製するのではなく、キーによってリンクされたテーブルにデータを格納します
- 主キーは行を一意に識別し、外部キーはテーブル間のリレーションシップを表現します
- 1対多のリレーションシップは「多」側に外部キーを使用し、多対多のリレーションシップには中間テーブルが必要です
- 正規化(第1正規形、第2正規形、第3正規形)は冗長性を減らしデータ異常を防ぎますが、意図的な非正規化が正当化される場合もあります
- データベース制約(
PRIMARY KEY、FOREIGN KEY、UNIQUE、NOT NULL、CHECK)は、データ整合性を守る最後の防衛線です
リレーショナルデータベースとは実際何か
リレーショナルデータベースは、テーブルにデータを格納します。テーブルは行と列で構成された構造化されたグリッドです。各テーブルは、users、orders、productsのような単一の主題またはエンティティを表します。各行は1つのレコードです。各列はそのレコードの1つの属性です。
リレーショナルモデルの力は、データを複製するのではなく、テーブルを相互にリンクすることから生まれます。この概念は、1970年にEdgar F. Coddによって提案されたリレーショナルモデルに由来し、現代のSQLデータベースの理論的基礎を今でも形成しています。
主キーと外部キー:リレーショナルスキーマの基礎
すべてのテーブルには主キーが必要です。主キーは、各行を一意に識別する列(または列の組み合わせ)です。優れた主キーは以下の特性を持ちます:
- すべての行で一意である
- 決してnullにならない
- 安定している — 割り当てられた後に変更されるべきではない
最新のSQLデータベースのほとんどは、一意の識別子を自動的に生成するidentity列(自動インクリメント整数)をサポートしています。多くのシステムは、組み込みのデータベース関数やデフォルト値を通じて生成されるUUIDベースのキーもサポートしています。どちらもコンテキストに応じて有効な選択肢です。自動インクリメント整数はシンプルで効率的です。UUIDは、複数のソースが独立してレコードを生成する分散システムに適しています。
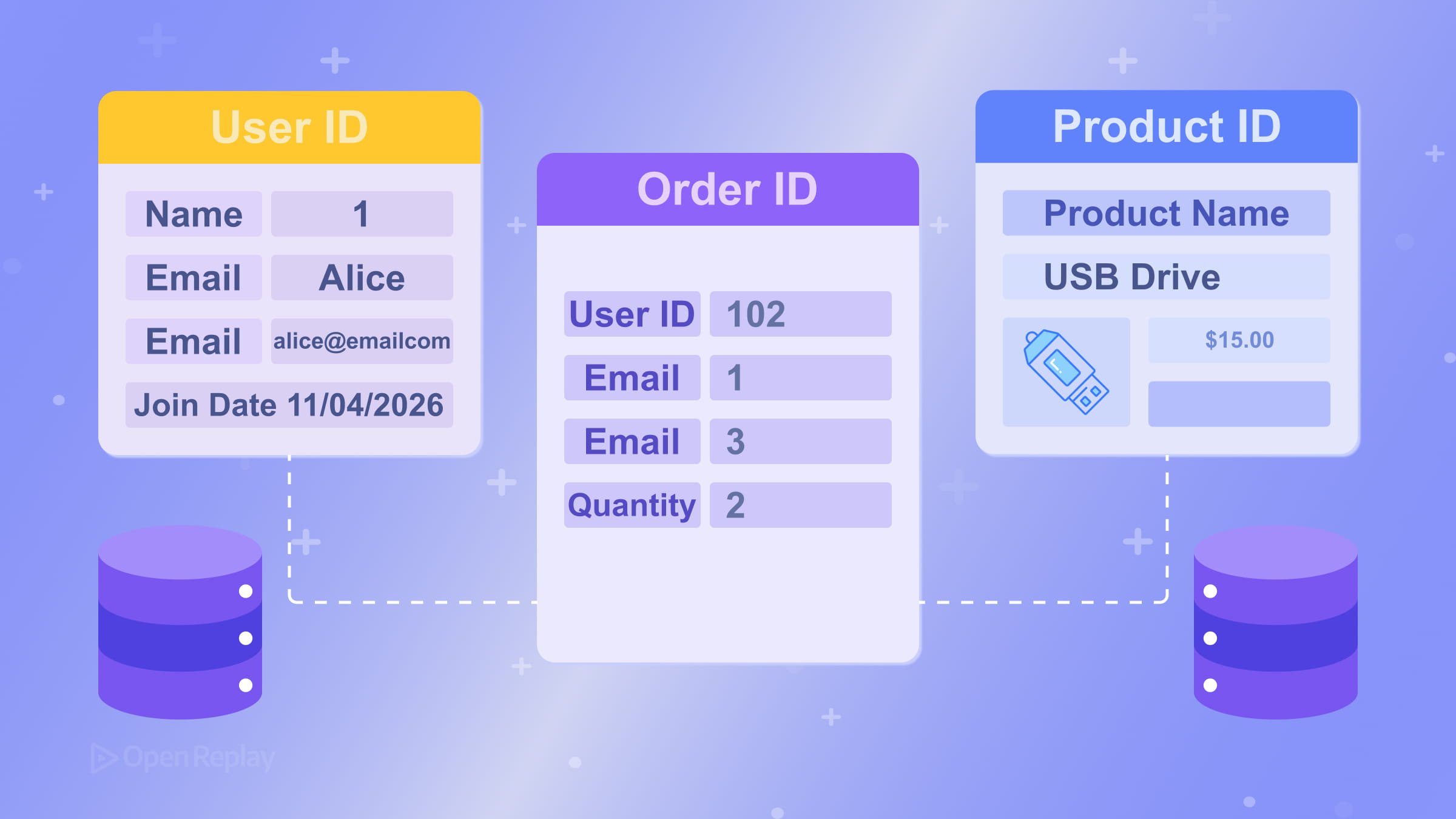
外部キーは、あるテーブルの列で、別のテーブルの主キーを参照するものです。これがテーブル間のリレーションシップを表現する方法です。例えば、ordersテーブルにはcustomers.idを参照するcustomer_id列があるかもしれません。データベースはこのリンクを強制し、孤立したレコードを防ぐことができます。具体的な例については、PostgreSQLの外部キー制約に関するドキュメントを参照してください。
リレーションシップのモデリング:1対多と多対多
リレーショナルデータベース設計で最も一般的なリレーションシップは1対多です:1人の顧客が複数の注文を持つ、1人の著者が複数の投稿を持つ、などです。これは「多」側に外部キーを配置することでモデル化します。
多対多のリレーションシップ(学生がコースに登録するなど)には、中間テーブル(連想テーブルまたはブリッジテーブルとも呼ばれます)が必要です。単一の列に複数の値を格納しようとするのではなく、studentsとcoursesの両方を指す外部キーを持つ第3のテーブル(enrollments)を作成します。これによりスキーマがクリーンでクエリ可能な状態に保たれます。

Discover how at OpenReplay.com.
データベース正規化の説明
データベース正規化は、冗長性を減らしデータ異常を防ぐためにテーブルを構造化するプロセスです。最も実用的な3つの正規形は以下の通りです:
- 第1正規形(1NF):各セルは1つの値を保持します — カンマ区切りのリスト、繰り返される列グループはありません
- 第2正規形(2NF):すべての非キー列は、主キーの一部だけでなく、全体に依存します(これは主に複合主キーを持つテーブルに適用されます)
- 第3正規形(3NF):非キー列は主キーのみに依存します — 互いに依存しません
正規化はガイドラインであり、法則ではありません。高度に正規化されたスキーマは保守が容易ですが、より多くの結合が必要になる場合があります。一部のチームは、読み取り負荷の高いワークロードのために特定のテーブルを意図的に非正規化します。適切なバランスは、クエリパターンとパフォーマンス要件によって異なります。データベース正規化の背後にある理論の詳細な概要は、Wikipediaで入手できます。
制約による整合性の強制
アプリケーションレベルの検証だけでは十分ではありません。複数のサービスがデータベースに書き込む場合、または誰かが直接SQLクエリを実行する場合、アプリ側のチェックは完全にバイパスされます。データベース制約は最後の防衛線です:
PRIMARY KEY— 識別子の一意性と非nullを強制しますFOREIGN KEY— 参照される行が実際に存在することを保証しますUNIQUE— 列内の重複値を防ぎます(メール、ユーザー名に便利)NOT NULL— フィールドが必須の場合に欠損値を防ぎますCHECK— 値が条件を満たすことを検証します(例:price > 0)
最新のSQLデータベースのほとんどは、生成列もサポートしています。これは他の列から自動的に計算される値で、アプリケーション層の冗長なロジックを減らすことができます。実装はエンジン(PostgreSQL、MySQL、SQL Serverそれぞれ異なる処理を行います)によって異なりますが、概念は広く利用可能です。例えば、PostgreSQLは公式ドキュメントで生成列について文書化しています。
実用的なスキーマの例
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);この例はPostgreSQLスタイルのSQL構文を使用しています。参照整合性を強制し、nullのメールを防ぎ、注文合計が非負であることを検証します — すべてデータベースレベルで行われます。
GENERATED ALWAYS AS IDENTITYは標準SQL(PostgreSQL 10+、Oracle 12c+、DB2でサポート)であることに注意してください。MySQLを使用している場合は、代わりにAUTO_INCREMENTを使用します。SQL Serverでは、同等のものはIDENTITY(1,1)です。詳細については、PostgreSQLのidentity列に関するドキュメントを参照してください。
まとめ
優れたリレーショナルデータベース設計は1つのアイデアに集約されます:各テーブルは1つのことを表すべきであり、各データは正確に1つの場所に存在すべきです。これを一貫して適用し、制約を使用してデータがどのようであるべきかを強制すれば、アプリケーションが成長してもスキーマは保守可能な状態を保ちます。ここで取り上げた原則 — 主キーと外部キー、正規化、リレーションシップモデリング、制約の強制 — は、すべての信頼性の高いデータベースが構築される基礎を形成します。
よくある質問
レコードが複数のデータベースまたはサービスで生成され、キーの衝突なしにマージする必要がある場合にUUIDを使用します。自動インクリメント整数はよりシンプルで、ストレージが小さく、インデックス作成が高速です。ほとんどの単一データベースアプリケーションでは、整数がうまく機能します。分散アーキテクチャやマルチテナントアーキテクチャでグローバルに一意な識別子が必要な場合にUUIDを選択してください。
ベースラインとして第3正規形(3NF)から始めてください。すべての非キー列が主キーのみに依存し、行間で重複データがない場合、良好な状態です。過度な結合によりクエリが遅くなりすぎる場合は、正規化を完全に放棄するのではなく、特定の読み取り負荷の高いテーブルで選択的な非正規化を検討してください。
外部キー制約がないと、データベースは孤立したレコードを防ぐことができません。存在しなくなった顧客を参照する注文や、削除されたコースを指す登録行が発生する可能性があります。アプリケーションコードは、特に複数のサービスや手動クエリがデータを変更する場合、エッジケースを見逃す可能性があります。外部キーはこれらの問題をデータベースレベルでキャッチします。
はい、意図的な非正規化は読み取り負荷の高いワークロードにおいて一般的かつ有効な手法です。重要なのは、意図的に行い、トレードオフを文書化することです。非正規化されたテーブルはクエリが高速ですが、更新が重複データに伝播する必要があるため、保守が困難です。デフォルトの設計選択としてではなく、クエリパフォーマンスが要求される場所で選択的に使用してください。
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..


