LLM Harnesses: Why the Wrapper Matters More Than the Model
LLM harnesses, not just models, shape agent success. See how orchestration, tools, context, and verification improve AI features.

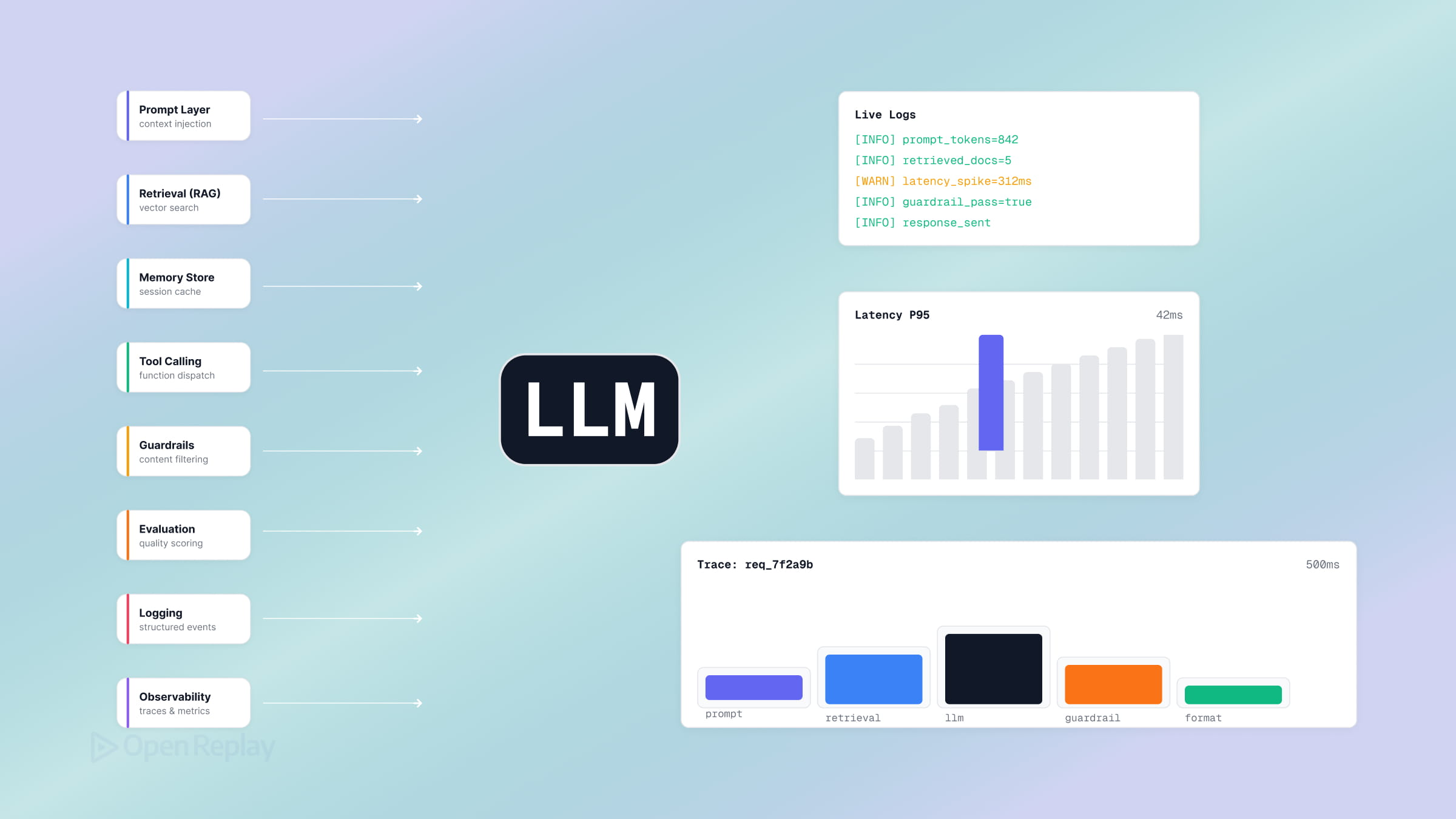
The harness is every piece of code, configuration, and execution logic that isn’t the model itself — the orchestration loop, tools, memory, context management, state, error handling, guardrails, and verification checks that together determine whether an agent succeeds or fails. If you’ve shipped an LLM feature with the OpenAI or Anthropic SDK and watched it loop, hallucinate tool calls, or forget what the user said three turns ago, you’ve already hit the limits of a thin harness — and most of the time the model wasn’t the problem.
This article gives you a precise mental model for the harness, the evidence that it drives more outcome variance than the model choice, a runnable JS/TS harness you can read end to end, and four decisions a frontend team actually owns when shipping an in-product AI feature.
Key Takeaways
- The harness is every piece of code, configuration, and execution logic that isn’t the model itself; LangChain’s Vivek Trivedy frames it as “if you’re not the model, you’re the harness.”
- Vercel’s v0 team deleted 80% of their agent’s tools and watched task success climb from 80% to 100% and average token usage fall by 37% — without changing the model.
- On Princeton HAL’s CORE-Bench Hard leaderboard, Claude Opus 4.5 scores 42.22% with CORE-Agent and 77.78% with Claude Code — a 35.56-point scaffold-driven swing on the same model.
- The harness-vs-model debate is not settled: Scale AI’s SWE-Atlas shows scaffold effects vary by model, while METR found Claude Code and Codex were not statistically significantly better than its own default scaffolds in a time-horizon evaluation.
- Every harness needs at least one deterministic check — a test, a schema validator, a regex — before it returns output to the user.
What is an agent harness?
An agent harness is the complete software system wrapping an LLM call: the orchestration loop that decides when to call the model, the tools the model can invoke, the memory and context it sees, the state it carries between turns, and the guardrails and verification checks that gate its output. The canonical formula comes from LangChain’s Vivek Trivedy: “if you’re not the model, you’re the harness.” The model produces tokens; the harness is everything that turns those tokens into a reliable feature.
The cleanest mental model for the relationship comes from Beren Millidge’s 2023 essay framing scaffolded LLM systems as natural-language computers: the LLM maps to the CPU, the prompt and context window map to RAM (fast but limited), and external memory like a vector database maps to disk-like storage. Tools act as device drivers reaching the outside world, and the harness is the operating system coordinating all of it. A CPU with no OS computes nothing useful. The model is necessary but not sufficient.
Terminology in this space sprawls, so fix it once. The model is the LLM — weights and an API. The harness (sometimes called the scaffold) is the surrounding code. The agent is the emergent behavior: a goal-directed, tool-using, self-correcting entity that the user interacts with. The Hugging Face Agents Course defines an agent as a system that uses an AI model to interact with its environment and achieve a user-defined objective. When someone says “I built an agent,” they built a harness and pointed it at a model. Anthropic’s own announcement of the Claude Agent SDK describes the Claude Code SDK as “the agent harness that powers Claude Code.”
Why does the wrapper matter more than the model?

Discover how at OpenReplay.com.
The wrapper matters more than the model because the same model, behind a different harness, produces wildly different outcomes — and the deltas are large, repeated, and measured on public benchmarks. The single strongest data point: Vercel’s v0 team deleted 80% of their agent’s tools and watched task success climb from 80% to 100%, average token usage fall by 37%, and one worst-case query drop from 724 seconds to 141 — without changing the model. The fix was entirely in the harness: fewer, better-scoped tools.
Two more results point the same direction. LangChain reported moving its coding agent from outside the top 30 to the top five on Terminal-Bench 2.0 by changing only the harness around an unchanged model, per its own writeup. And on Princeton HAL’s CORE-Bench Hard leaderboard, Claude Opus 4.5 scores 42.22% with the CORE-Agent scaffold and 77.78% with Claude Code — a 35.56-point swing on the same model, with the leaderboard also reporting 95.5% under manual validation for the Claude Code run.
| Study | Model changed? | Harness changed? | Before | After |
|---|---|---|---|---|
| Vercel v0 | No | Yes (−80% tools) | 80% success | 100% success, −37% tokens |
| LangChain / Terminal-Bench 2.0 | No | Yes | Outside Top 30 | Top 5 |
| Princeton CORE-Bench Hard | No (Opus 4.5) | Yes (scaffold) | 42.22% | 77.78% |
The debate is not settled, and oversimplifying it costs credibility. Scale AI’s SWE-Atlas compares first-party coding-agent scaffolds against the minimal mini-SWE-agent and shows scaffold effects vary by model, with native scaffolds producing notable improvements over the minimal baseline. Meanwhile, METR found that Claude Code and Codex were not statistically significantly better than its own default scaffolds in a time-horizon evaluation. Both effects are real; which one dominates depends on the task regime. The honest reading, as MongoDB puts it, is that “the LLM is the smallest part” — but harness gains are not unbounded, and a strong model on a weak task still caps what scaffolding can recover.
What are the components of an LLM harness?
A production harness decomposes into eight components, each of which is a place a thin wrapper can fail: orchestration loop, tools, memory, context management, prompt construction, state, error handling, and guardrails-with-verification.
Orchestration loop. The loop implements the Thought–Action–Observation cycle (the ReAct pattern): call the model, check whether it requested a tool, run the tool, feed the result back, repeat until the model answers or a guard fires. As Vikash Rungta’s reverse-engineering analysis of Claude Code puts it, the runtime is a “dumb loop” where all intelligence lives in the model and the harness just manages turns. Mechanically it is a while loop with a turn cap.
Tools. Tools are the agent’s hands — functions exposed to the model as schemas (name, description, parameter types). The tool layer handles registration, argument validation, execution, and formatting results back into model-readable observations. A search_docs tool in a help widget is a tool; so is get_order_status.
Memory. Short-term memory is the current conversation; long-term memory persists across sessions. In a chat widget, short-term memory is the message array you replay each turn; long-term memory might be a per-user summary you load on session start.
Context management. The scarce resource is the context window, and the failure mode is context rot — quality degrades when the window fills with low-signal tokens. Per Anthropic’s context engineering guidance, the goal is the smallest set of high-signal tokens. Strategies: compaction (summarize old turns) and just-in-time retrieval (fetch on demand instead of pre-loading).
Prompt construction. The harness assembles the input hierarchically: system prompt, tool definitions, memory, conversation history, current message. Order matters; important context belongs at the start and end of the window.
State. State is what survives across turns and crashes — the agent’s position in a multi-step task, intermediate outputs, checkpoints. A chat widget that “forgets” the user’s earlier constraint has a state problem, not a model problem.
Error handling. A 10-step task at 99% per-step success has only ~90% end-to-end success because errors compound. The key pattern: return a tool error to the model as an observation so it can self-correct, rather than throwing and killing the run.
Guardrails and verification loops. Guardrails constrain what the agent may do; verification loops check what it produced. Martin Fowler / Birgitta Böckeler’s harness-engineering writeup frames verification as guides (feedforward — steer before acting) and sensors (feedback — observe and self-correct), split into computational (deterministic: tests, linters) and inferential (LLM-as-judge) controls.
How do I build an agent harness in JavaScript?
A minimal but complete harness is a ReAct loop with a turn cap, one well-scoped tool, an error-as-observation handler, and one deterministic verification check. The example below uses the Anthropic SDK and Zod for schema validation. The verification check is the part most thin wrappers skip — without it, the agent has no way to know it’s wrong.
import Anthropic from "@anthropic-ai/sdk";
import { z } from "zod";
const client = new Anthropic();
// One tool, narrowly scoped. Fewer tools = fewer spurious calls.
const tools: Anthropic.Tool[] = [
{
name: "get_order_status",
description: "Look up the status of an order by its numeric ID.",
input_schema: {
type: "object",
properties: { orderId: { type: "number" } },
required: ["orderId"],
},
},
];
// Deterministic verification: the model's tool input must match this schema.
const OrderArgs = z.object({ orderId: z.number().int().positive() });
async function runOrder(orderId: number) {
// Stand-in for a real lookup.
return { orderId, status: "shipped", eta: "2026-03-04" };
}
export async function harness(userMessage: string) {
const messages: Anthropic.MessageParam[] = [
{ role: "user", content: userMessage },
];
// Max-turns guard: the single most important safety rail against looping.
for (let turn = 0; turn < 6; turn++) {
const res = await client.messages.create({
model: "claude-sonnet-4-6",
max_tokens: 1024,
system: "You are an order-status assistant. Use tools when asked about orders.",
tools,
messages,
});
const toolUse = res.content.find(
(b): b is Anthropic.ToolUseBlock => b.type === "tool_use"
);
if (!toolUse) return res.content; // No tool call → the model answered.
messages.push({ role: "assistant", content: res.content });
let observation: string;
const parsed = OrderArgs.safeParse(toolUse.input);
if (!parsed.success) {
// Verification failed: return the error AS an observation, don't throw.
observation = `Invalid arguments: ${parsed.error.message}`;
} else {
try {
observation = JSON.stringify(await runOrder(parsed.data.orderId));
} catch (e) {
observation = `Tool error: ${(e as Error).message}`; // also an observation
}
}
messages.push({
role: "user",
content: [{ type: "tool_result", tool_use_id: toolUse.id, content: observation }],
});
}
return [{ type: "text", text: "Could not complete the request." }];
}Four design choices in those ~50 lines carry most of the reliability. The for loop with a turn cap is the orchestration loop and the anti-looping guard. The single tool keeps the tool schema small. The Zod safeParse is the deterministic verification check that catches hallucinated arguments before they hit your backend. And both validation failures and runtime errors are returned as observations, not thrown — so the model can correct itself instead of the run dying. Anthropic’s tool-use mechanics are documented in the tool use guide; the equivalent loop with the OpenAI SDK uses tool_calls and role: "tool" messages.
Why do frontend developers own more of the harness than they think?
Frontend developers already own a harness whenever they ship an AI chat widget, an in-product search assistant, or a copilot UI — they’re just thinner harnesses than the agentic ones. Most of the failures users complain about (looping, hallucinated tool calls, forgotten context, ignored constraints) are harness failures, not model failures. When a frontend team ships an AI feature, the model choice is one decision among many, and the harness decisions — tool scope, what context to carry, what to verify — usually get less design review than they deserve.
The mapping is direct. A user who watches the assistant “regenerate” the same wrong answer is watching an orchestration loop with no verification. A user whose stated constraint vanishes two turns later is watching a state and context-management gap. A tool call that fires with a garbage argument and returns a confusing reply is a missing schema check — exactly the safeParse step above. None of these are fixed by swapping models. They are fixed by tightening the wrapper you already own.
How thick should my harness be? Four decisions frontend teams own
A frontend team shipping an in-product AI feature actually controls four harness decisions: tool scoping, context strategy, verification loops, and harness thickness. The broader field-wide list — single vs. multi-agent, ReAct vs. plan-and-execute, permissions, durable execution, fleet governance — sits at infrastructure layers most chat widgets never reach.
-
Tool scoping — start with fewer than 10 tools and expand reluctantly. Giving an agent more tools than it needs reliably degrades performance, because each additional tool schema consumes context and raises the probability of a spurious call. Vercel’s result is the load-bearing evidence: removing 80% of the tools improved everything.
-
Context strategy — compaction and just-in-time retrieval over stuffing the window. Don’t pre-load the whole knowledge base into the prompt. Summarize old turns when you approach the window limit, and fetch documents on demand. Anthropic’s context engineering guidance frames the target as the smallest high-signal token set.
-
Verification loops — every harness needs at least one deterministic check before it returns output to the user. A schema validator, a regex, a unit test — something the harness can run that doesn’t depend on the model’s own judgment. Without it, the agent has no way to know it’s wrong. Per Böckeler’s computational/inferential split, start with a cheap computational check; add an LLM-as-judge only when semantic correctness needs it.
-
Harness thickness — start thin, add structure only when a failure pattern recurs. Don’t pre-build orchestration for failures you haven’t seen. Add a retry, a guardrail, or a verification step when a specific failure shows up more than once.
Watching session replays of an AI feature in production is one of the fastest ways to read harness quality from user behavior, because the diagnostic signatures are visible without any model-level telemetry. Repeated rephrasing of the same request signals lost context or a verification loop that never fires. Mid-conversation abandonment on a multi-step task often traces to a swallowed tool error surfacing as a vague reply. Copy-then-edit behavior signals a verification gap — output that passed the harness’s checks but failed the user’s. Repeated clicking of “regenerate” or “try again” is the signature of a looping harness that can’t detect its own failure state.
Where is harness design heading?
Models are now post-trained with their harnesses in the loop — as LangChain notes in its discussion of agent harness architecture, products such as Claude Code and Codex combine model training and harness design in a feedback cycle — which means the harness is no longer a swappable wrapper but a co-evolved part of the product surface. The implication for builders is that the harness is becoming part of the product you design, not a generic adapter you can lift from one model to another unchanged.
That gives you a clean future-proofing test, drawn from the scaffolding metaphor: if your design scales up cleanly with a stronger model — same harness, better results — it’s sound. If it needs more scaffolding to compensate as the model improves, the harness is masking a model or task problem you should fix elsewhere. Scaffolding, like the construction kind, is meant to come down as the structure stands on its own.
The next time your AI feature loops, forgets, or returns something confidently wrong, audit the harness before you audit the model. Start with the four decisions above — tool scope, context strategy, one deterministic check, and thickness — and add the smallest amount of structure that makes the failure stop recurring.
FAQs
What is the difference between a harness and a scaffold?
The terms are used interchangeably in practice; both refer to every piece of code, configuration, and execution logic surrounding the model that isn't the model itself. 'Scaffold' is the more common term in benchmark literature, such as Princeton's CORE-Agent versus Claude Code scaffold comparison, while 'harness' is favored in production and SDK contexts. LangChain's Vivek Trivedy collapses the distinction with the rule: if you're not the model, you're the harness.
Should I return a tool error to the model or throw it in my harness?
Return the error to the model as an observation rather than throwing it. Throwing kills the run; returning the error as a tool result lets the model see what went wrong and self-correct on the next turn. This matters because errors compound across multi-step tasks, where a 10-step task at 99% per-step success drops to roughly 90% end-to-end. Both schema validation failures and runtime exceptions should be caught and fed back as observations, never as unhandled throws.
Does adding more tools improve agent performance?
No, adding more tools reliably degrades performance past a certain point. Each tool schema consumes context window tokens and increases the probability of a spurious or incorrect tool call. Vercel's v0 team deleted 80% of their agent's tools and watched task success climb from 80% to 100% and average token usage fall by 37% on the same model. The practical rule is to start with fewer than 10 tools and expand only when a real gap appears.
Can I swap models in and out of the same harness without changes?
Increasingly, no. As LangChain notes in its discussion of agent harness architecture, products such as Claude Code and Codex combine model training and harness design in a feedback cycle. This makes the harness a co-evolved part of the product surface rather than a generic adapter. A useful future-proofing test is whether your design scales up cleanly with a stronger model on the same harness; if it needs more scaffolding to compensate as the model improves, the harness is masking a deeper problem.


