Regular Expressions and Input Validation
Regular expressions are sometimes dreaded, but they are quite useful for validations


The /^\d+((\.\d+)?[\+\-×÷]\d+(\.\d+)?)+$/ string is a regular expression. To the untrained eye, it probably looks like a lot of gibberish, but these seemingly random sequences of characters are the key to text querying algorithms used across multiple programming and query languages. In this article, we will take a quick dive into regular expressions, what they are, what they do and how they can help us create custom HTML input validations.
At the end of this article, you will know how to:
- Read and write basic regular expressions
- Test your regular expressions
- Perform input validation with regular expressions
- Use regular expressions to boost your code
What Are Regular Expressions?
Regular expressions (commonly abbreviated to Regex or RegExp) are a sequence of characters that predefine a pattern for text combinations. At a basic level, regular expressions can be considered search terms or queries. They are very powerful queries that are particularly useful for finding a pattern of characters within any given group of texts.
/abcd/
The text above is a regex. It defines any text combination that reads exactly abcd. Consider the following groups of text:
abcd //match
abcdefgh //match
Xyzabcd //match
Xyzabcdefgh //match
123abcdxy //match
abcdabcd//1 match
Abxcd //no matchThe regex /abcd/ will match all except the last because although letters a,b,c and d are present, the pattern in which they are present does not match the exact pattern defined by the regex. The regex will only match the penultimate text group once because, by default, a regex returns after the first match.
Regex Syntax
Regex are kind of their own language. Hence, they have a unique syntax. This syntax consists of the following:
Alphanumeric Characters
Any alphanumeric characters A-Z and 0-9 are considered valid regex and represent themselves literally. This implies that /a/ matches a, /1/ matches 1 and so on.
Symbols
Symbols like .,^$×+ are all valid regex. However, in most cases, they do not represent themselves instead, they have special meanings which modify alphanumeric characters that come before or after them. Symbols are the key to making powerful regex. Common symbols include:
*
This symbol reads ‘0 or more times’.
/a*1b/
1bcd //match
a1bcd //match
aaaaaaaaa1bcd //matchMatch the preceding character (a) between 0 times and infinity times.
+
This symbol reads ‘at least one time’.
/a+1b/
1bcd //no match
a1bcd //match
aaaaaaaaa1bcd //matchMatch the preceding character (a) between one and infinity times.
?
This symbol reads ‘optional’.
/ab?1/
ab1 //match
a1 //matchMatch the presence or absence of the preceding character (b).
^
This symbol reads ‘start only’.
/^ab?c/
abc //only 2 possible matches
ac //It will match only if the entire text group begins with the preceding character (a).
$
This symbol reads ‘end only’.
/ab?c$/
abc //match
ac //match
abca //no matchIt will match only if the entire text group ends in the preceding character (c).
|
This symbol reads ‘or’.
/ab|cd/
abd //match
acd //match
abcd //1 matchMatch the presence of either the preceding characters (ab) or the succeeding characters (cd).
{}
This symbol is for repetition.
/abcd{3}/
abcd //no match
abcddd //matchMatch preceding character (d) repeatedly three times.
{,}
This symbol creates a repetition range.
/abcd{3,5}/
abcd //no match
abcddd //match
abcdddd//matchMatch preceding character (d) if repeated 3-5 times.
()
This symbol reads ‘group and evaluate’.
/a(bcd){3}/
abcdd //no match
abcdbcdbcd //matchIt will group characters (bcd) and evaluate them as one.
[ ]
This symbol reads ‘options’.
/ab[0369]cd/
ab0cd //match
ab6cd //match
ab03cd //no match
ab0369cd //no matchThis symbol allows us to pass in options where only one option is to be selected. It also allows special operations within its boundary, as seen in the next two examples.
[^]
This symbol reads ‘exclude’.
/ab[^c]de/
abcde //no match
abde //no match
abzde //match
ab1de //matchMatch any character except the succeeding character (c).
[-]
This symbol reads ‘range’.
/ab[0-9]cd/
ab1cd //match
ab6cd //matchMatch any character from 0-9
•
This symbol will match all characters except newline characters.
\
This symbol reads ‘escape’.
/abcd\$/
abcd //no match
abcd\$ // no match
abcd$ //matchThe escape symbol will remove the special meaning of a symbol but will give a special meaning to certain alphabets. (See metacharacters)
Metacharacters
Metacharacters are unique alphabets that have special meanings in regex. They are written using the escape symbol and the unique alphabet. Metacharacters include:
\d
Represents any number from 0-9
\w
Represents any character a-z,A-Z,0-9 and _
\s
Match all spaces
\b
This metacharacter creates a boundary. If used before a text, that text is a match, only if preceded by a space.
If used after a text, that text is a match, only if followed by a space.
/\bbird/
abird //no match
A bird//matchNote: Using capital letter metacharacters inverts the rules of that particular metacharacter. For example:
\D\
Match any character that is not a number.
Flags We use flags to control the behaviour of the entire regex pattern. Flags are added directly after the whole regex.
g
The global flag. It reads ‘find all matching patterns in the entire string; do not stop at the first one’. Note that stopping at the first match is a regex default behaviour.
i
The case-insensitive flag. It makes alphabet character matching case-insensitive.
m
The multi-line flag. It makes a regex evaluate each line separately.
Common Regex Patterns The following regex patterns often come in handy:
Start to End
\^your regex here $\
This pattern ensures that the regex will be a match only if the text group as a whole is in line with the regex pattern. Hence, our example will match ‘your regex here’ and no other string combination.
- Look ahead
\x(?=y)\will match x only if y comes after x. - Negative look ahead
\x(?!y)\will match x only if y does not come after x. - Look behind
\(?<=y)x\will match x only if it comes after y. - Negative look behind
\(?<!y)x\will match x only if it does not come after y.
Using Regex in JavaScript Regex is not JavaScript specific. It is present in many other programming languages like python, java, go etc. and works almost the same way in all languages. In JavaScript, a regex can be initiated in two ways:
- Double forward slashes:
/your regex here/flagTwo forward slashes with the regex in-between is the most common way to create a regex in JavaScript. - Regex constructor:
const pattern = new RegExp (‘your regex here’,flag). This method is useful, especially when the regex is written using variables and template literals.
const a='b'
const p=new RegExp(`${a}bc`)
console.log(p.test('abc')) //false
console.log(p.test('bbc')) //trueRegex Methods
let pattern=/\D/
pattern.test('hello') //true
pattern.exec('hello') //['h',index:0,input:'hello',groups:undefined]Regex.test(‘string’)This method checks if a regex matches a string and returns true or false.Regex.exec(‘string’)This method returns the matched string and information about that string in an array or null if there is no match.
A creative way to use regex is with string methods like match, replace, contains etc. Here is a cool trick to get the number of words in any string.
const words='any string'.match(/\S+/g) //[any,string]
words.length //2Note: /\S+/g reads ‘match all non-space characters of any length’.
Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
What Is Input Validation?
Input Validation is the process of controlling what values users (or 3rd party applications) can pass into our application. We do this to prevent unexpected and unwanted user inputs, which can cause errors or security risks from making their way into our application or database. Html input boxes are the most common way of taking in user input in a web application. HTML itself implements a few native input validations.
<html>
<head>
<title>Regex</title>
</head>
<body>
<form>
<input maxlength="10" required/>
<input type="number" min="120" max="500" required/>
<button>Submit</button>
</form>
</body>
</html>
<!-- The red highlighted text are native HTML validation attributes-->The form will be submitted only if the first input box contains ten or fewer characters and the second input box contains numbers between 120-500. Also, since both inputs are required, they must not be left empty. However, native HTML Validations often do not suffice, hence the need for custom validations.
Writing Custom Input Validations with Regex.
In this section, we will learn to validate input from an input box on the client side using regex. This idea can also be applied in the backend to validate data before storing it in a database.
To write validations with regex, rather than using regex as a query for an existing group of text, we use regex to define a standard, which every text input must meet before it can be submitted.
In most of our validations, we will use the start/end /^ $/ regex pattern since we want the entire user input to match our regex.
Max length Validator We will start by recreating the native validation in the first and second input of our previous HTML code block with regex. For the first input: Our input box should take any text, not be left empty (required) and have a maximum length of ten characters.
//take any text
/^\w$/
//take exactly ten characters
/^\w{10}$/
//take between 0-10 characters
/^\w{0,10}$/
//1st character is compulsory, with nine optional characters
/^\w\w{0,9}$/We have arrived at a solution, and we will call it maxRegex
maxRegex= `/^\w\w{0,9}$/`Min/Max length Validator
For the second input, we want numbers between 120-500 only.
To make this easier, we will break down our standard as numbers from 120-199 or 200 to 499 or 500
When using the | regex, each unit separated by | tends to evaluate individually. We will prevent this behaviour by grouping the units using ()
//100-199
/^(1\d\d)$/
//120-199
/^(1[2-9]\d)$/
//120-199 or 200-299
/^(1[2-9]/d])|(2\d\d)$/
//120-199 or 200-499
/^(1[2-9]/d])|([2-4]\d\d)$/
//120-199 or 200-499 or 500
/^(1[2-9]/d])|([2-4]\d\d)|500$/
//group entire regex
/^((1[2-9]/d])|([2-4]\d\d)|500)$/
minMaxRegex=`/^((1[2-9]/d])|([2-4]\d\d)|500)$/`Time Input Validator We will validate the HH: MM time format. We want a number between 0-23 (hours), a colon and a number between 00-59 (minutes)
//0-9, 10-19 or 20-23
/^(\d|1\d|2[0-3])$/
//0-23, 01-59
/^(\d|1\d|2[0-3])[0-5]\d$/
//colon in-between
/^(\d|1\d|2[0-3]):[0-5]\d$/
//accommodating 00-09 hour patterns
/^(\d|[01]\d|2[0-3]):[0-5]\d$/
TimeRegex=`/^(\d|[01]\d|2[0-3]):[0-5]\d$/`Telephone Number Validator We will validate the international phone number format. It is usually a + sign followed by 7-15 numbers.
//+ sign
/^\+$/
//and any seven digits
/^\+\d{7}$/
//option for up to eight extra digits
/^\+\d{7}(\d{1,8})?$/
telephoneRegex=`/^\+\d{7}(\d{1,8})?$/`Email Validator
With more email providers coming up daily, the search for the perfect email validator is still ongoing, with no end in sight. However, our regex will try to match the most common email patterns, which usually look something like this:
username@domainname.extension.extraextension.
//Username should be alphanumeric (lowercase) with options to include dots and hyphens
/^[a-z\d\.\-]$/
//Domain names are the same as usernames but without the option for a dot
/^([a-z\d\.\-])[a-z\d\-]$/
//@ should separate username and domain name
/^([a-z\d\.\-])@([a-z\d\-])$/
//Extension should be any alphabets (lowercase) preceded by a dot
/^([a-z\d\.\-])@([a-z\d\-]).([a-z])$/
//Extraextension is same as extension but optional
/^([a-z\d\.\-])@([a-z\d\-])(\.[a-z])(\.[a-z])?$/
//Most emails have extensions between 2-5 characters long
/^([a-z\d\.\-])@([a-z\d\-])(\.[a-z]{2,5})(\.[a-z]{2,5})?$/
emailRegex= `/^([a-z\d\.\-]+)@([a-z\d\-]+)(\.[a-z]{2,5})(\.[a-z]{2,5})?$/`Password Strength Validator We will validate a password to contain at least eight characters, with a capital letter, a symbol, a number and no spaces. Here, we must validate each criterion separately since we do not know the order a user might arrange their alphabet symbols and numbers for a password; because of this, we will also not use a start/end pattern.
//At least eight characters long with no spaces
/\S{8}+/
//Must contain a capital letter
/[A-Z]/
//Must contain a number
/\d/
//Must contain a symbol
/\W/
passwordRegex= `[/(\S{8})+/, /[A-Z]/,/\d/,/\W/]`Calculator Input Validator.
We will validate our input to match only valid basic mathematical expressions that a calculator can evaluate.
The pattern formed by basic mathematical expressions looks like this: 1+23-45×6.78÷9.
//It begins with a number (which can be infinitely long);
/^\d+$/
//grows by adding a basic mathematical operator (+-×÷) and another number.
/^\d+[\+\-×÷]\d+$/
//A number may optionally have a decimal point, but the decimal point must be between two digits
/^\d+ (\.\d+)?[\+\-×÷]\d(\.\d+)?+$/
calcRegex=`/^\d+((\.\d+)?[\+\-×÷]\d+(\.\d+)?)+$/g`Note: There are few edge cases with this pattern, but to reduce complexity, this should suffice.
Validations The code block below explains how to validate inputs using the seven regex patterns we have just defined.
<html>
<head>
<title>Regex</title>
<style>
input {
margin: 10px;
display: block;
}
</style>
</head>
<body>
<form>
<label for="max">Enter a maximum of 10 characters</label>
<input id="max" />
<label for="minMax">Enter a value between 120-500</label>
<input id="minMax" />
<label for="telephone">Enter an international phone number</label>
<input id="telephone" />
<label for="time">Enter the time in hh/mm format</label>
<input id="time" />
<label for="email">Enter email</label>
<input id="email" />
<label for="password"
>Enter a password.At least 8 characters,with a capital letter,a symbol,a
number and no spaces</label
>
<input id="password" />
<label for="calc"
>Enter a valid mathematical expression that will work in a simple
calculator
</label>
<input id="calc" />
<button>Submit</button>
</form>
<script>
const form = document.querySelector("form");
const maxInput = document.querySelector("#max");
const minMaxInput = document.querySelector("#minMax");
const telephoneInput = document.querySelector("#telephone");
const timeInput = document.querySelector("#time");
const emailInput = document.querySelector("#email");
const passwordInput = document.querySelector("#password");
const calcInput = document.querySelector("#calc");
//Our Regex
const maxRegex = /^\w\w{0,9}$/;
const minMaxRegex = /^(1[2-9]\d)|([2-4]\d\d)|500$/;
const telephoneRegex = /^\+\d{7}(\d{1,8})?$/;
const timeRegex = /^(\d|[01]\d|2[0-3]):[0-5]\d$/;
const emailRegex =
/^([a-z\d\.-]+)@([a-z\d-]+)(\.[a-z]{2,5})(\.[a-z]{2,5})?$/;
const calcRegex = /^\d+((\.\d+)?[\+\-×÷]\d+(\.\d+)?)+$/;
//array containing each separate regex for our password validation
const passwordRegex = [/(\S{8})+/, /[A-Z]/, /\d/, /\W/];
//Validate user input by preventing form submission until the input matches the regex pattern
const validateWithRegex = (input, regex) => {
form.addEventListener("submit", (e) => {
if (regex.test(input.value)) {
input.style.border = "3px solid green";
} else {
e.preventDefault();
input.style.border = "3px solid red";
}
});
};
validateWithRegex(maxInput, maxRegex);
validateWithRegex(minMaxInput, minMaxRegex);
validateWithRegex(telephoneInput, telephoneRegex);
validateWithRegex(timeInput, timeRegex);
validateWithRegex(emailInput, emailRegex);
validateWithRegex(calcInput, calcRegex);
//Validate password input separately since it uses an array of regex
const passwordValidate = (input, regex = []) => {
form.addEventListener("submit", (e) => {
if (
regex[0].test(input.value) &&
regex[1].test(input.value) &&
regex[2].test(input.value) &&
regex[3].test(input.value)
) {
input.style.border = "3px solid green";
} else {
e.preventDefault();
input.style.border = "3px solid red";
}
});
};
passwordValidate(passwordInput, passwordRegex);
</script>
</body>
</html>Sample Output
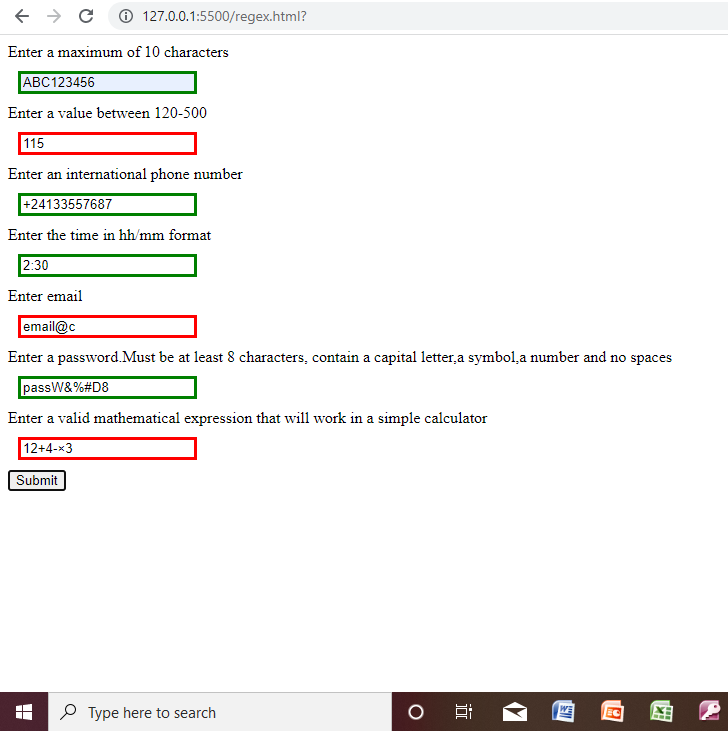
Resources
To practice more regex, check out:
- Regex 101 https://regex101.com/ (REPL for testing regex)
- Regex cheat sheet https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions/Cheatsheet
Summary
Regular expressions can be as simple as /abcd/ and as complex as /^\d+((\.\d+)?[\+\-×÷]\d+(\.\d+)?)+$/. If we are ever in a situation where we need to find a unique text or match a seemingly complex text pattern, using a regex might be a good idea. However, we must remember that the more unique the search, the more complicated the regex.
A TIP FROM THE EDITOR: For more on validation with JavaScript, do read our Form Validation Using JavaScript’s Constraint Validation API article.
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.



