
Relational Database Design Basics

Most database problems aren’t caused by bad queries — they’re caused by a bad schema. If your tables are poorly structured from the start, no amount of clever SQL will fully compensate. This article covers the core principles of relational database design: how to structure tables, define keys, model relationships, and use constraints to keep your data reliable.
Key Takeaways
- A relational database stores data in tables linked by keys, not by duplicating information across them
- Primary keys uniquely identify rows; foreign keys express relationships between tables
- One-to-many relationships use a foreign key on the “many” side, while many-to-many relationships require a junction table
- Normalization (1NF, 2NF, 3NF) reduces redundancy and prevents data anomalies, though deliberate denormalization is sometimes warranted
- Database constraints (
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,CHECK) are your last line of defense for data integrity
What a Relational Database Actually Is
A relational database stores data in tables — structured grids of rows and columns. Each table represents a single subject or entity, like users, orders, or products. Each row is one record. Each column is one attribute of that record.
The power of the relational model comes from linking tables together rather than duplicating data across them. The concept originates from the relational model proposed by Edgar F. Codd in 1970, which still forms the theoretical foundation of modern SQL databases.
Primary Keys and Foreign Keys: The Foundation of Relational Schemas
Every table needs a primary key — a column (or combination of columns) that uniquely identifies each row. A good primary key is:
- Unique across all rows
- Never null
- Stable — it shouldn’t change after being assigned
Most modern SQL databases support identity columns (auto-incrementing integers) that generate unique identifiers automatically. Many systems also support UUID-based keys, often generated through built-in database functions or defaults. Both are valid choices depending on your context. Auto-incrementing integers are simple and efficient. UUIDs are better suited for distributed systems where multiple sources generate records independently.
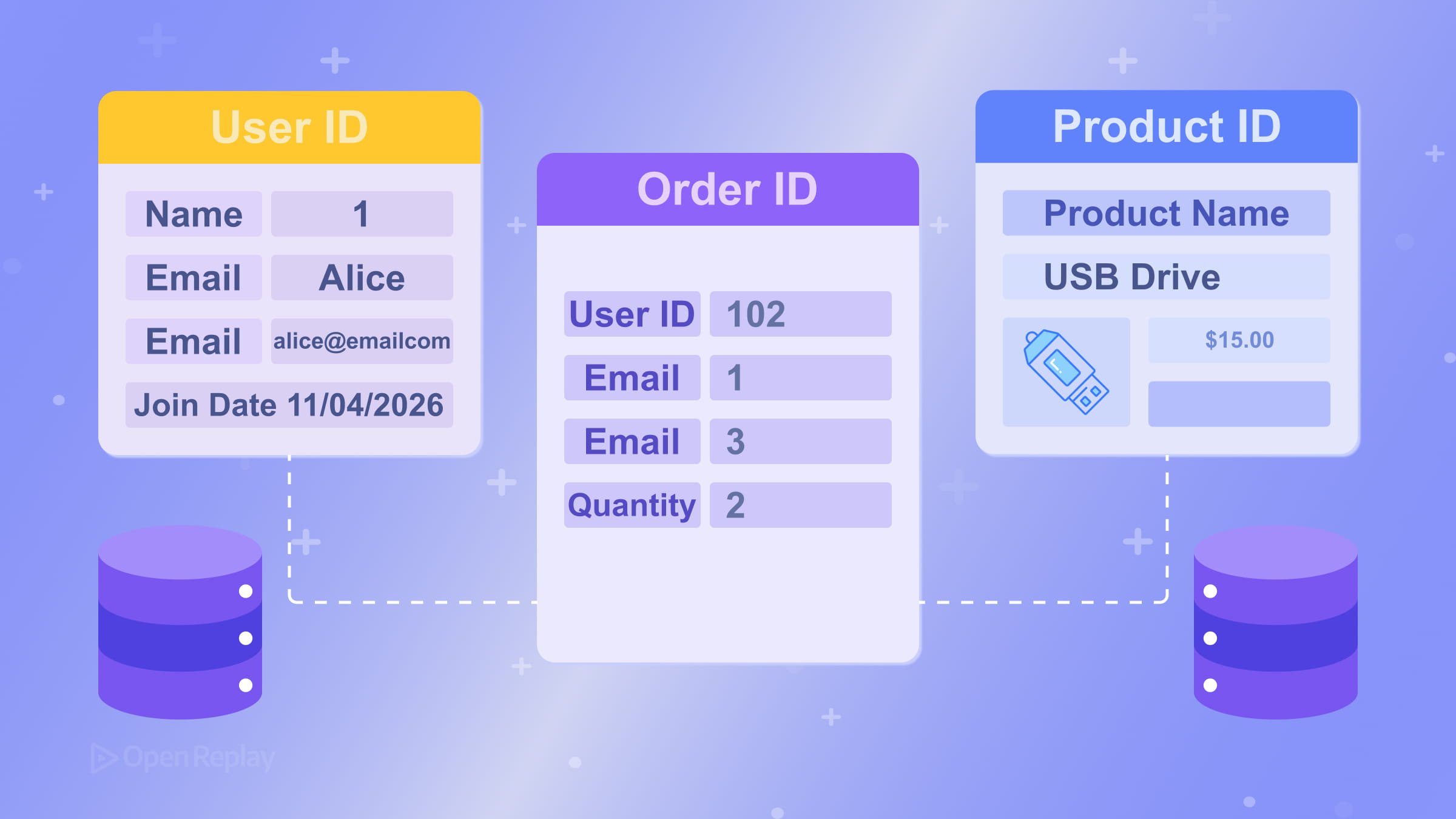
A foreign key is a column in one table that references the primary key of another. This is how relationships between tables are expressed. For example, an orders table might have a customer_id column that references customers.id. The database can enforce this link, preventing orphaned records. See the PostgreSQL documentation on foreign key constraints for a concrete example.
Modeling Relationships: One-to-Many and Many-to-Many
The most common relationship in relational database design is one-to-many: one customer has many orders, one author has many posts. You model this by placing the foreign key on the “many” side.
Many-to-many relationships — like students enrolling in courses — require a junction table (also called an associative or bridge table). Instead of trying to store multiple values in a single column, you create a third table (enrollments) with foreign keys pointing to both students and courses. This keeps the schema clean and queryable.

Discover how at OpenReplay.com.
Database Normalization Explained
Database normalization is the process of structuring tables to reduce redundancy and prevent data anomalies. The three most practical normal forms are:
- 1NF (First Normal Form): Each cell holds one value — no comma-separated lists, no repeating column groups
- 2NF (Second Normal Form): Every non-key column depends on the entire primary key, not just part of it (this mainly applies to tables with composite primary keys)
- 3NF (Third Normal Form): Non-key columns depend only on the primary key — not on each other
Normalization is a guideline, not a law. Heavily normalized schemas are easier to maintain but can require more joins. Some teams intentionally denormalize specific tables for read-heavy workloads. The right balance depends on your query patterns and performance requirements. A more detailed overview of the theory behind database normalization is available on Wikipedia.
Enforcing Integrity with Constraints
Application-level validation alone isn’t enough. If multiple services write to your database, or someone runs a direct SQL query, your app-side checks are bypassed entirely. Database constraints are your last line of defense:
PRIMARY KEY— enforces uniqueness and non-null on the identifierFOREIGN KEY— ensures referenced rows actually existUNIQUE— prevents duplicate values in a column (useful for emails, usernames)NOT NULL— prevents missing values where a field is requiredCHECK— validates that a value meets a condition (e.g.,price > 0)
Most modern SQL databases also support generated columns — values computed automatically from other columns — which can reduce redundant logic in your application layer. Implementations vary across engines (PostgreSQL, MySQL, SQL Server each handle these differently), but the concept is broadly available. For example, PostgreSQL documents generated columns in its official documentation.
A Practical Schema Example
CREATE TABLE customers (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
email VARCHAR(255) NOT NULL UNIQUE,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
customer_id INT NOT NULL REFERENCES customers(id),
total NUMERIC(10, 2) CHECK (total >= 0),
created_at TIMESTAMP NOT NULL DEFAULT now()
);This example uses PostgreSQL-style SQL syntax. It enforces referential integrity, prevents null emails, and validates that order totals are non-negative — all at the database level.
Note that GENERATED ALWAYS AS IDENTITY is standard SQL (supported in PostgreSQL 10+, Oracle 12c+, and DB2). If you’re using MySQL, you would use AUTO_INCREMENT instead. In SQL Server, the equivalent is IDENTITY(1,1). See the PostgreSQL documentation on identity columns for details.
Conclusion
Good relational database design comes down to one idea: each table should represent one thing, and each piece of data should live in exactly one place. Apply that consistently, use constraints to enforce what the data must look like, and your schema will stay maintainable as your application grows. The principles covered here — primary and foreign keys, normalization, relationship modeling, and constraint enforcement — form the foundation that every reliable database is built on.
FAQs
Use UUIDs when records are generated across multiple databases or services that need to merge without key collisions. Auto-incrementing integers are simpler, smaller in storage, and faster for indexing. For most single-database applications, integers work well. Choose UUIDs when you need globally unique identifiers in distributed or multi-tenant architectures.
Start with third normal form (3NF) as your baseline. If every non-key column depends solely on the primary key and you have no repeated data across rows, you are in good shape. If queries become too slow due to excessive joins, consider selective denormalization on specific read-heavy tables rather than abandoning normalization entirely.
Without foreign key constraints, the database cannot prevent orphaned records. You might end up with orders referencing customers that no longer exist, or enrollment rows pointing to deleted courses. Application code can miss edge cases, especially when multiple services or manual queries modify data. Foreign keys catch these problems at the database level.
Yes, deliberate denormalization is a common and valid practice for read-heavy workloads. The key is to do it intentionally and document the trade-offs. Denormalized tables are faster to query but harder to maintain because updates must propagate to duplicated data. Use it selectively where query performance demands it, not as a default design choice.
Truly understand users experience
See every user interaction, feel every frustration and track all hesitations with OpenReplay — the open-source digital experience platform. It can be self-hosted in minutes, giving you complete control over your customer data. . Check our GitHub repo and join the thousands of developers in our community..


