

Data collection, content monitoring, automated tasks, etc., involve web scraping. A variety of frameworks are available for scraping data from websites. Some frameworks are Axios, Puppeteer, Cheerio, JSDOM, etc. but Cheerio and Puppeteer are popular for web scraping in JavaScript because of their flexible APIs and ease of use.
In this article, we will discuss the puppeteer framework and why to use it. We will be looking at installation, the basic structure of Puppeteer, how to navigate to a website and extract data, and at the end, how to interact with dynamic pages such as clicking buttons and scrolling.
What is Puppeteer, and why is it useful?
Puppeteer is a Node.js library. It provides an easy-to-use API for testing web applications, extracting data from web pages, automating tasks, interacting with dynamic web pages, etc.
Puppeteer is a suitable choice for web scraping because:
- Support and Intuitive API: It has an API that is very useful for extracting data from web pages and also valuable for automating most web-related tasks.
- Headless Browsing: You can extract data from a website without opening it. It will extract all the data internally, which makes it faster and more efficient for web scraping.
- Support Modern Web Technologies: Puppeteer supports popular web technologies such as WebSockets and IndexedDB. The user can interact with the site by clicking buttons, scrolling the web pages, etc.
Initialization of Puppeteer
Create a new directory with any name (like puppeteer_scraping).
mkdir puppeteer_scrapingCreate a folder that will contain the Javascript files. Then, navigate to the folder and run the below command to initialize the package.json file.
npm init -yThe last step is to install puppeteer using the npm install command.
npm install puppeteerWait, before proceeding further, head over to package.json and add "type":"module" to handle ES6 features such as template literals, classes, promises, etc.
{
"name": "puppeteer_scraping",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"puppeteer": "^19.6.3"
},
"type": "module"
}Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
Extracting Data from Web Pages
We can either use Wikipedia or the Toscrap website to understand web scraping. But in this article, we will work on the Toscrap site. For beginners or to get started with web scraping, the Toscrap website is very useful and easy to use.
The Toscrap website is a Web Scraping Sandbox containing two projects mainly designed for web scraping. We will only scrape data from Quotes to Scrap.
Initializing the Script:
Create a new file with the name index.js. The script has a function named scrapQuotes() to handle the scraping process.
In the scrapQuotes() function, a new browser instance is launched using puppeteer.launch(). Headless mode is set to false, so you can see the web pages in your browser.
Afterward, use browser.newPage() to create a new page in the browser and pass the webpage URL to the page.goto() function to navigate there.
We will not close the browser now, but we have to close it by calling the browser.close() method at the end of the function.
// Import the Puppeteer module
import puppeteer from "puppeteer";
// Define a function to handle the scraping of data
const scrapQuotes = async () => {
// Launching a new browser instance
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open the new page in the browser
const page = await browser.newPage();
// Navigate to the URL
await page.goto("http://quotes.toscrape.com/");
};
// Call the function
scrapQuotes();After you run the above script using node index.js, the new page will be opened in the browser. You can see the image attached below:
Fetch the First Quote
Scraping web pages requires you to play with the HTML DOM. Whenever a web page is loaded, the browser creates a Document Object Model of the web page.
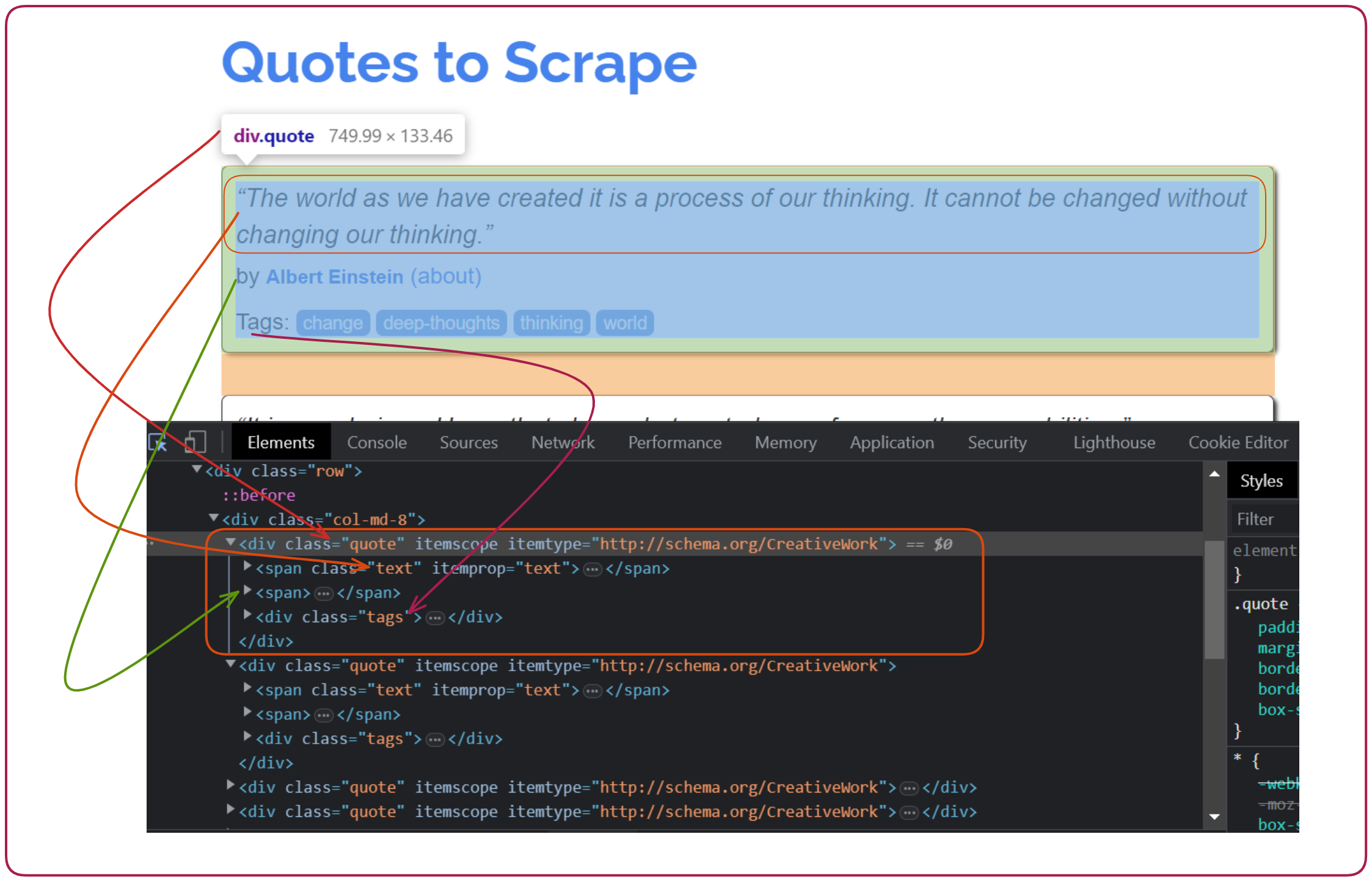
The right way to start scraping text is to inspect the web page and navigate the pointer here and there to scrape the text you need. You can see in the below image that inside the quote class (class="quote"), the text, author, and tags classes are written.
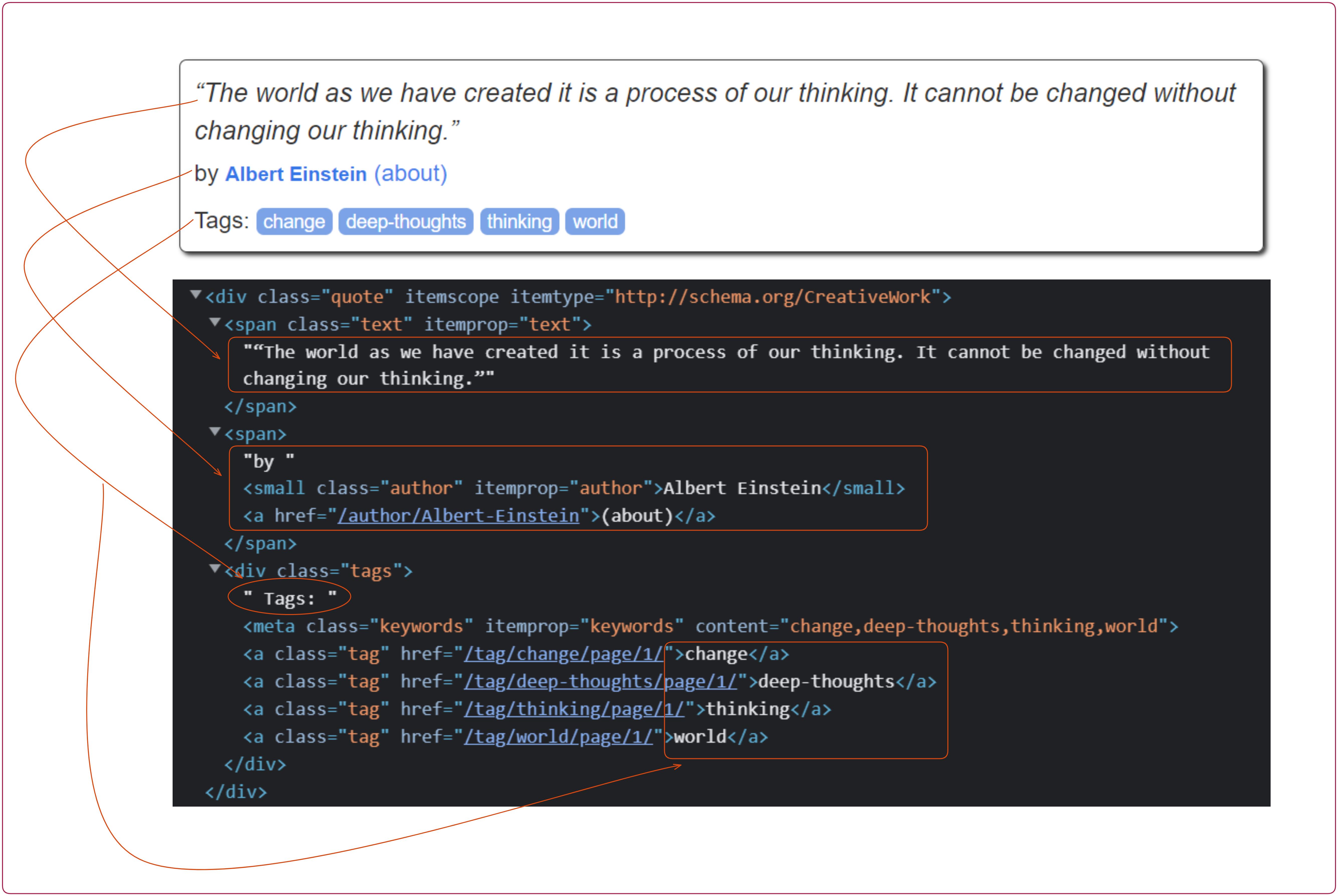
In the image below, you can see the zoomed-in image of the above image. You can see how classes such as text, author, and tags are written inside the <div> container. Inside the container, there are classes like text (class="text"), author (class="author"), and tags (class="tags").
Let’s have a look at the code to scrape our first quote. In the below code, the page.evaluate() function will run the code within the context of the currently loaded page. Then, we will use querySelector() to select an element on the web page based on the .quote class.
After that, we can extract the text and the author by passing .text and .author inside the querySelector() function.
Then, display the entire text and author name and close the browser instance.
// Import the Puppeteer module
import puppeteer from "puppeteer";
// Define a function to handle the scraping of data
const scrapQuotes = async () => {
// Launching a new browser instance
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open the new page in the browser
const page = await browser.newPage();
// Navigate to the URL
await page.goto("http://quotes.toscrape.com/");
// Fetch the page data
const quotes = await page.evaluate(() => {
// Use querySelector to select an element on the web page based on its CSS selector
const quote = document.querySelector(".quote");
// Extracting the text
const text = quote.querySelector(".text").innerText;
// Extracting the author
const author = quote.querySelector(".author").innerText;
return { text, author };
});
// Print the Quotes
console.log(quotes);
// Close the browser instance
await browser.close();
};
// Call the function
scrapQuotes();The result is:
{
text: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
author: 'Albert Einstein'
}As you can see in the above result, we have fetched the first quote from the website with the author’s name.
Fetch all Quotes on a Web Page
To fetch all the quotes on a current page, you need the querySelectorAll() function instead of querySelector().
In the below image, you can see ten quotes on the current page.
Pass the class name (quote) inside the querySelectorAll() function to extract all the quotes.
This function would return the NodeList of elements; then, you must convert it to an array of elements.
Ultimately, you can loop through this array of quotes and fetch all the content, like text and author.
// Import the Puppeteer module
import puppeteer from "puppeteer";
// Define a function to handle the scraping of data
const scrapQuotes = async () => {
// Launching a new browser instance
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null,
});
// Open the new page in the browser
const page = await browser.newPage();
// Navigate to the URL
await page.goto("http://quotes.toscrape.com/");
// Fetch the page data
const quotes = await page.evaluate(() => {
// Fetching all the elements of .quote class.
const quotesArray = document.querySelectorAll(".quote");
// Convert NodeList of quotes to an array &
// use map to extract text and author of each quote
return Array.from(quotesArray).map((quote) => {
const text = quote.querySelector(".text").innerText;
const author = quote.querySelector(".author").innerText;
return { text, author };
});
});
// Print the Quotes
console.log(quotes);
// Close the browser instance
await browser.close();
};
// Call the function
scrapQuotes();Navigate to the Next Page:
The click() method can be used to click the button. The next button is located within the ul > li > a in the following image.
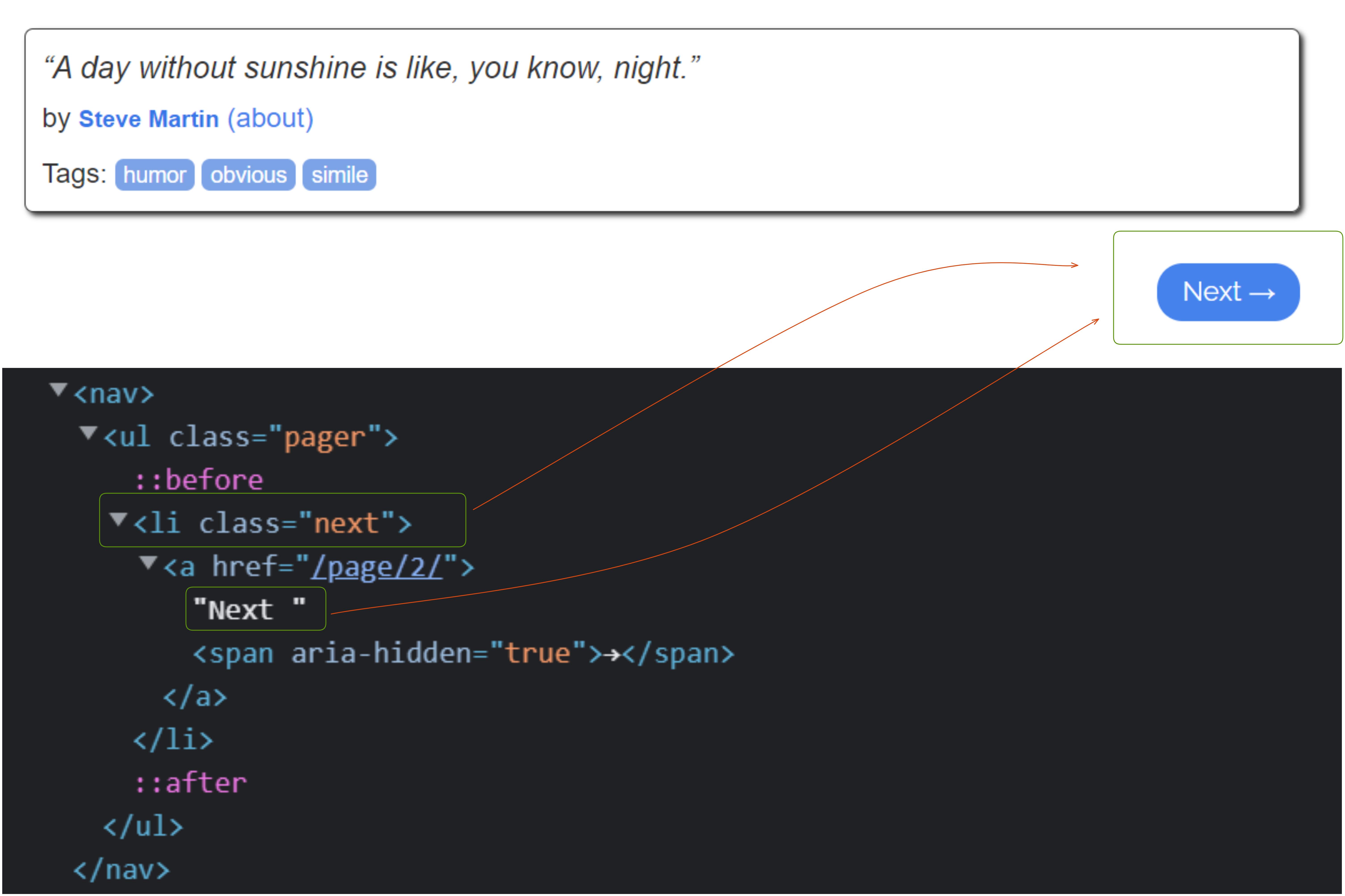
In the click() method, you have to pass .next > a because <a> is inside the next class which is also inside the pager class. You can also pass .pager > .next > a for the safe side. The browser.close() function is commented out in the code so that the next page appears. If you uncomment it, the page will close instantly, and you will not be able to see it.
// Print the Quotes
console.log(quotes);
// Click on the Next button
const searchResult = ".next > a";
await page.waitForSelector(searchResult);
await page.click(searchResult);
// Close the browser instance
// await browser.close();The result is:
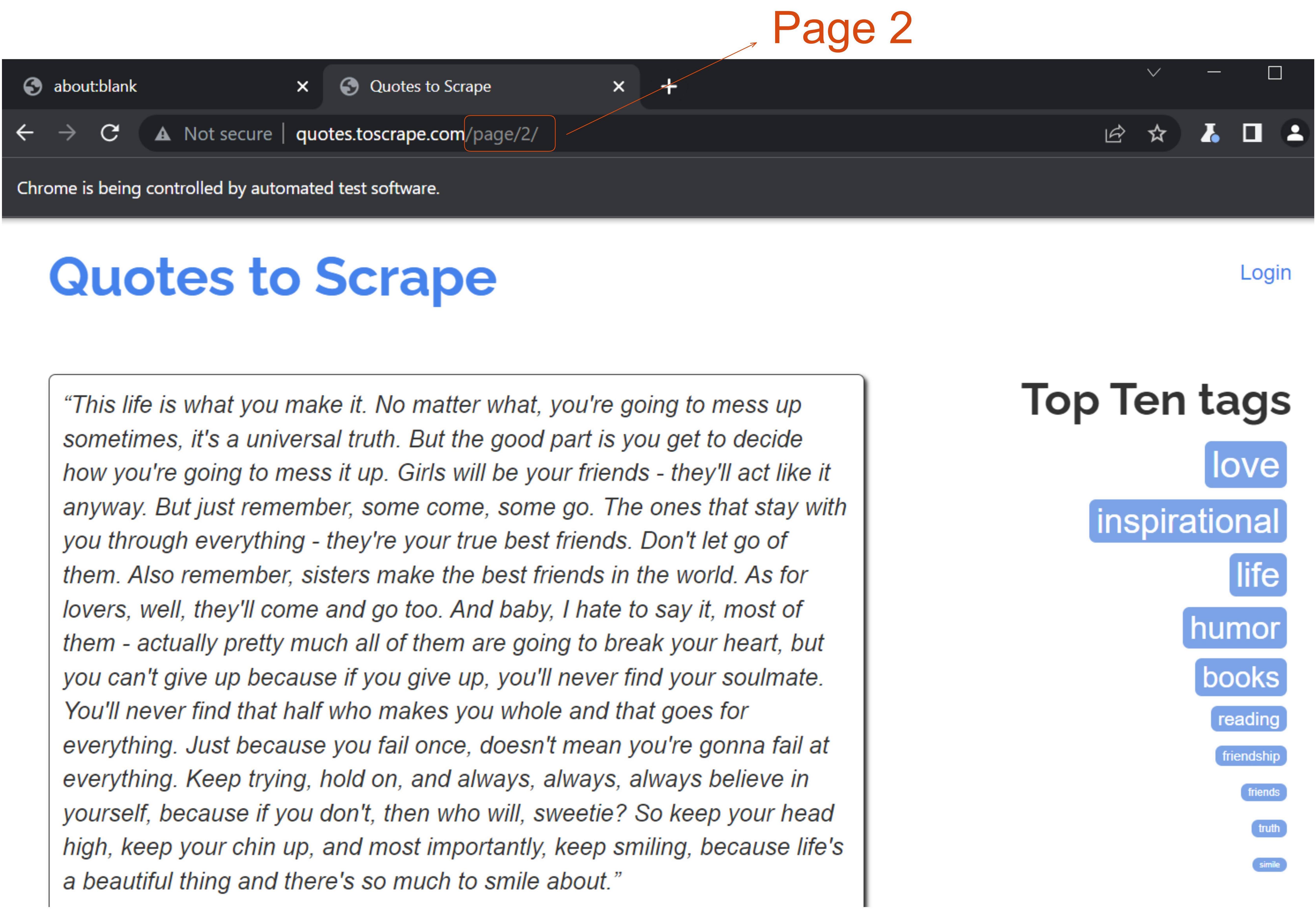
Tip: You can do a lot more with web scraping. You could scrape some e-commerce websites to get the price of the items, ratings, etc.
In our case, you can perform many more experiments, such as fetching all the tags and removing duplicates. You can navigate between the pages using the Next and Previous buttons, and clicking on the about link will provide you with some biographical information about the author.
Conclusion
In this article, we look at how to scrape web pages using Puppeteer. We learned about the basics of Puppeteer, how to navigate to a website and extract information, interact with dynamic web pages, etc.
It is a popular tool for web scraping since it offers a simple and efficient way to extract data from websites. Puppeteer is an excellent choice for web scraping projects due to its ability to run headless browsing and its simple and intuitive API.
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.



