
What is a CI/CD pipeline?


What’s the importance of Continuous Integration (CI) and Continuous Deployment (CD) pipelines, and why should you use them for software development? This article will provide you with the answers to that question, and more.
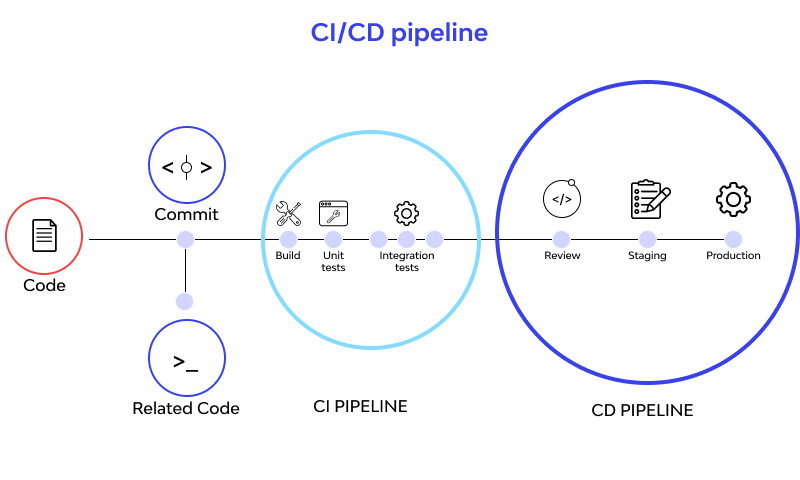
Continuous Integration (CI) and Continuous Deployment (CD) pipelines are a series of steps that should be done to deliver a new version of the software. Furthermore, CI/CD pipelines are a practice focused on boosting software delivery throughout the development life cycle through automation.
Organizations could develop higher-quality code faster by automating CI/CD throughout the development, testing, production, and monitoring stages of the SDLC. The real value of CI/CD pipelines is realized through automation.
Benefits of implementing CI/CD Pipelines
The pipeline implementation groundwork could take time and involve a steep learning curve. The benefits, however, outweigh the effort, time, and cost spent on the endeavor. Check out the benefits of implementing a CI/CD pipeline and why many organizations shifted to this approach.
Lesser risk
Finding and fixing bugs later in the development process is not only time-consuming but expensive as well. This is particularly true if issues with features occur that have been released to production already. With a CI/CD pipeline, you can test and deploy code regularly, allowing testers to detect issues as soon as they come out and fix them instantly.
Put simply, implementing a pipeline means mitigating risks in real time.
Faster delivery
Organizations want to release features several times a day, which is no easy task. Companies like Amazon, Netflix, and Facebook are among the few companies that have been able to achieve this. However, with a seamless pipeline, multiple releases per day could be made a reality.
The developers could create, test, and automatically deploy features with almost no manual intervention. Frameworks, tools, and systems like Docker, Travis CI, Kubernetes, and LaunchDarkly could help accomplish this.
Less manual effort
From the very beginning, automation is needed to align with the shift-left paradigm. Furthermore, this is also a vital component for a successful CI/CD implementation. When building features and checking in code, tests should be automatically triggered to ascertain that the new code won’t break the existing features and that new features also work correctly.
After tests are run, the code is deployed to various environments, such as quality assurance, staging, and production. There are constant notifications throughout the process via different channels, providing plenty of information regarding the build, test, and deploy cycles.
Extensive logs generation
One of the biggest aspects of CI/CD and DevOps integration is observability. When something goes awry, it’s important to understand why it happens. You also have to study the system in production over time and determine the major performance metrics. As a technical solution, observability helps.
One key to observability is logging information. Furthermore, logs are a rich source of information to understand what is happening beneath the User Interface and study the application’s behavior. A piece of comprehensive logging information is generated in each development phase with a pipeline. There are several tools that you can use for effective logs analysis and get instant feedback regarding the system.
Easy rollbacks
One of the biggest advantages of a CI/CD pipeline is the rapid rollback of changes. If a new code change breaks the production app, you can return it to its previous state immediately. Typically, the last successful build gets deployed to immediately prevent production outages.
As the world is moving toward rapid release cycles, CI/CD pipelines have accelerated that release rate. With thorough planning and implementation, this pipeline could help find defects faster, boost overall customer satisfaction, and implement fixes immediately.
Phases of CI/CD pipelines
Now, let’s see more about the different CI/CD Pipeline phases.
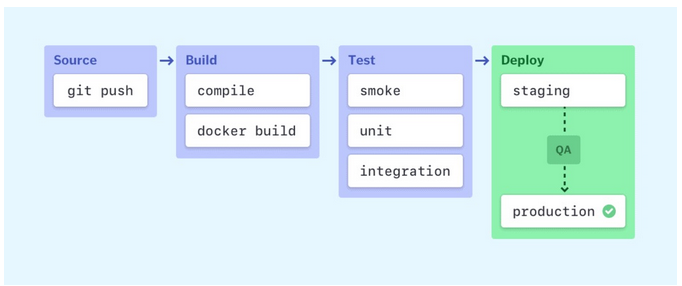
Image Source - Semaphoreci
Source Stage
In this stage, an organization maintains the source code in a centralized repository system. This could also be called a version control system, such as GitHub, GitLab, and others. This stage and the tools are essential for developers to track and coordinate who is doing what.
This stage also serves as a collaboration booster as different teams check in code, do reviews on the code, and approve it for further steps. IDEs, such as Visual Code Studio could be done to automate version control.
Build Stage
In this stage, developers push a code to a version control system. When a developer pushes code to the control version system of an organization, it triggers the continuous integration tool or system. The code then goes through the tests that the developer prescribed.
Code is compiled in this phase, dependencies are sorted out, and artifacts are created and stored in a repository, such as Jfrog. The software packages are all set for deployment. Furthermore, there could be war files, for instance, files that get deployed on WebLogic and Tomcat. Also, in this phase, environments are built using infrastructure as code, containers are created, which run on different pods, and pre-baked images to be rolled out are stored.
Test Stage
Focusing on a consistent, continuous, and faster feedback testing loop is important in this stage. Testing pipelines should aim at facilitating continuous and early testing. Unfortunately, this is still one of the biggest hindrances that companies struggle with.
Breaking it down to see what it takes to build a CI/CD helps to do testing more efficiently.
Testing data is one of the biggest challenges wherein teams cannot carry out testing without the historical data built. Without automating data requirements, it isn’t possible for not possible for organizations to have a fully automated CI/CD pipeline. Data testing requires creation, management, and maintenance. In addition, it’s necessary to drive the culture of creating and managing data as code. Managing and maintaining data helps to:
- Accelerate continuous integration and continuous deployment
- Drive immutability
- Security and data governance
- Boosts scrum team productivity
Deploy Stage
This stage is where it is all set to be deployed to QA, pre-production, or production environment as per the organization’s plans. Software deployment could be automated via continuous deployment. This is the phase where organizations prefer deployment strategies, including canary, rolling, blue/green, etc.
Building CI/CD pipelines with Jenkins
Ensure that Jenkins is configured properly with the required dependencies before starting. Also, you would want a basic understanding of the concepts of Jenkins. Let’s build a pipeline with Jenkins configured in a Windows environment.
- Step One. Install Log in to Jenkins and click Create a job.
- Step Two. Name the pipeline. Choose the ‘pipeline’ option from the menu, provide a pipeline name, and click ‘OK’.
- Step Three. Pipeline Configuration A pipeline could be configured in the pipeline configuration screen. From there, you can set build triggers and other pipeline options. The Pipeline Definition section is the most important, and this is where you get to define the pipeline stages. Pipeline supports both declarative and scripted syntaxes. Here we’re going with a direct pipeline script, but you will get another option to retrieve the Jenkins file from SCM.
Sample Jenkins pipeline Code that is used here for a demo:
pipeline {
agent any
stages {
stage('Stage 1') {
steps {
echo 'This is CI/CD Pipeline demo from Jenna.'
}
}
}
}Below is the snapshot from Jenkins where you can add the above script and save the configuration.
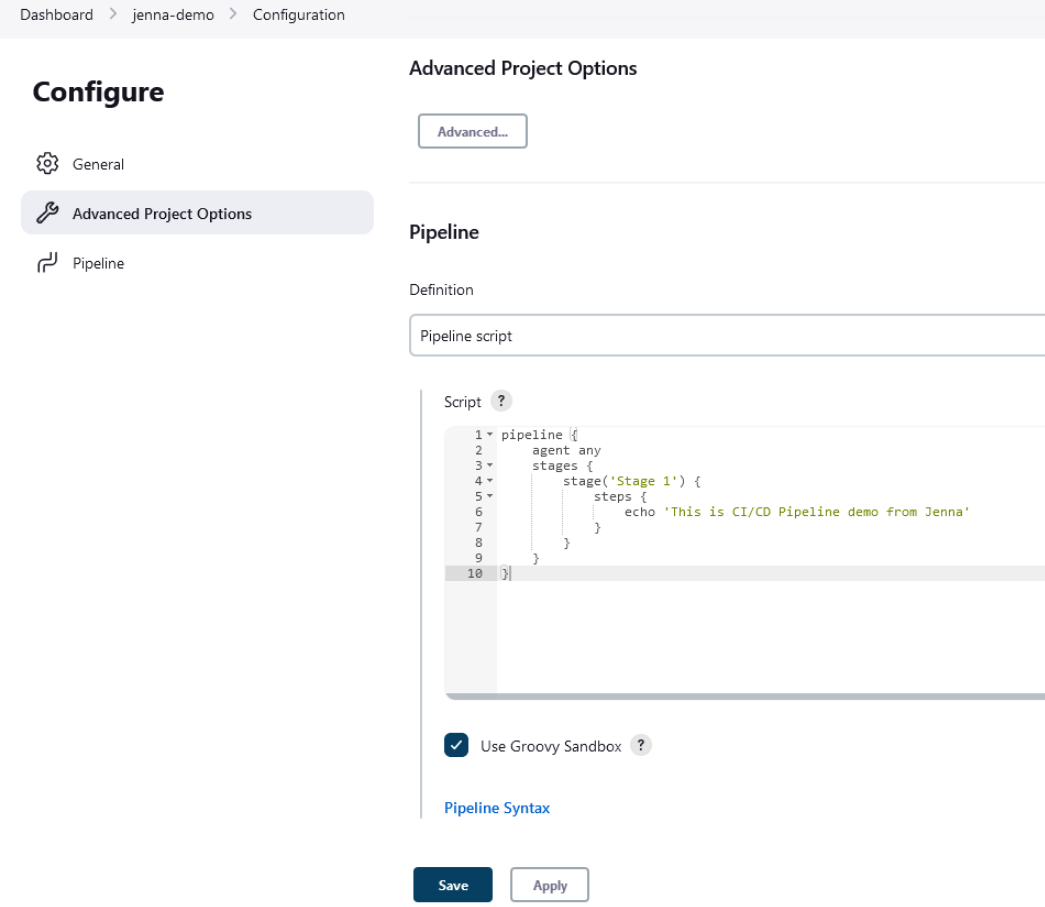
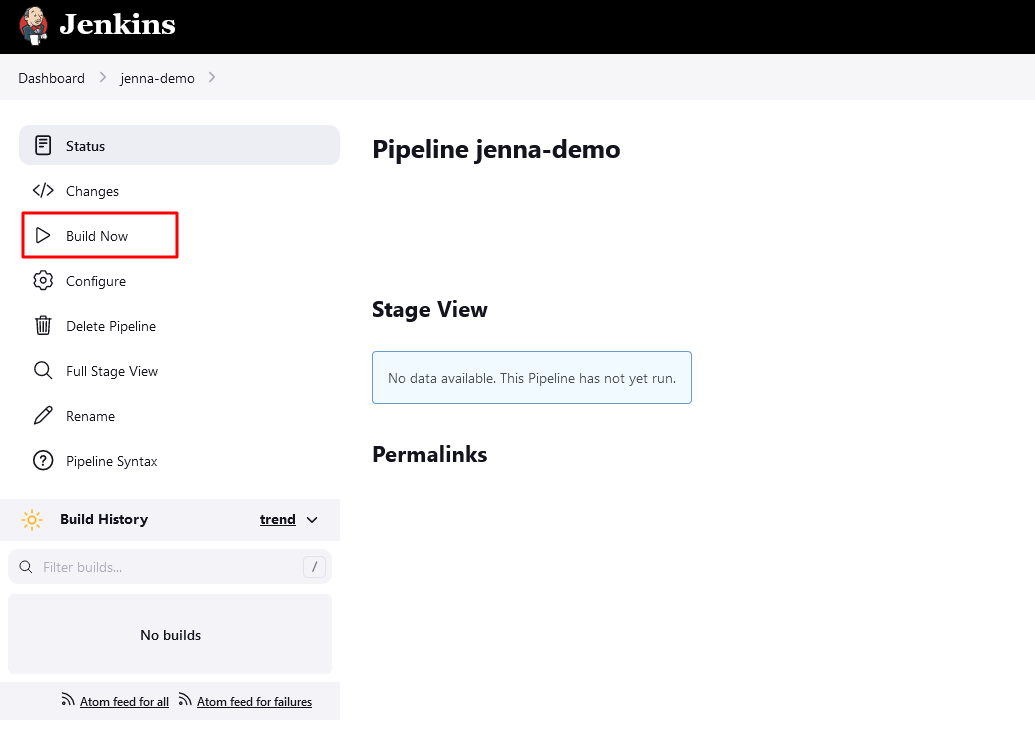
- Step Four. Pipeline Execution By clicking on ‘Build Now’, you can execute the pipeline.
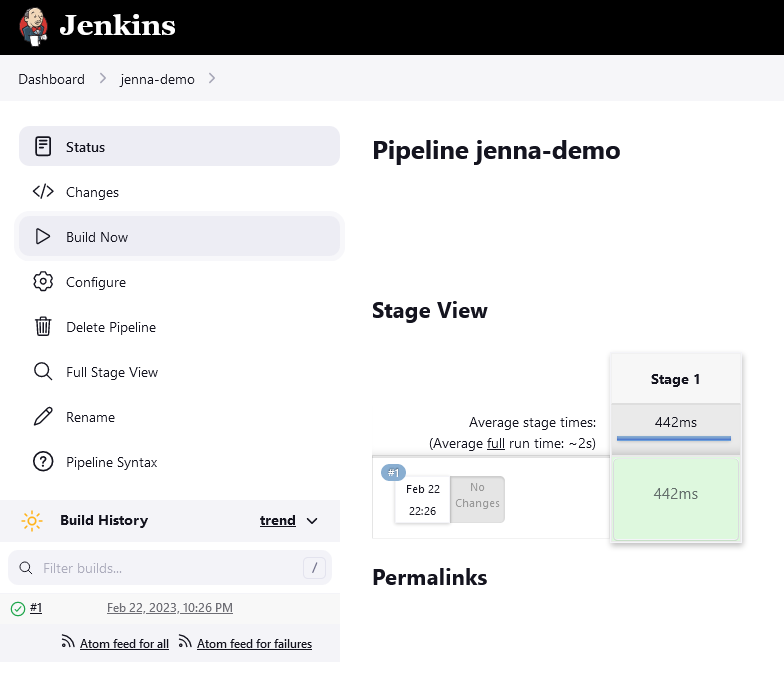
- Step Five. The result is displayed in the ‘Stage View’ section.
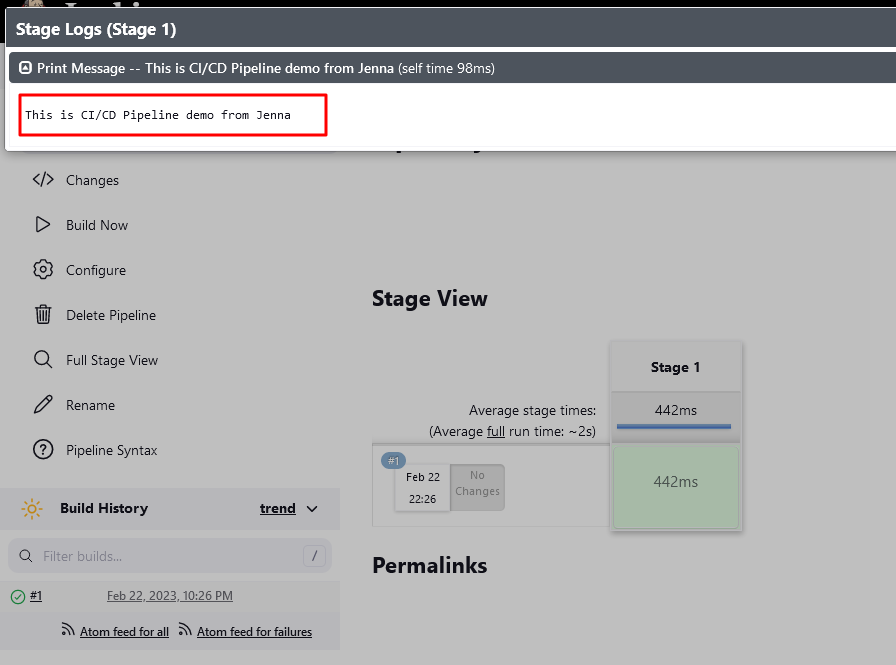
- To check if the pipeline is executed successfully, check the console output for the build process.
Session Replay for Developers
Uncover frustrations, understand bugs and fix slowdowns like never before with OpenReplay — an open-source session replay tool for developers. Self-host it in minutes, and have complete control over your customer data. Check our GitHub repo and join the thousands of developers in our community.
Best Practices for CI/CD pipelines
Building a CI/CD pipeline should not be a fire-and-forget endeavor. Like the software under development, it’s important to take an iterative approach to the CI/CD practices.
Streamline your tests
The purpose of CI/CD, after all, is to provide rapid feedback and deliver valuable software to users faster. This means there should be a balance struck between test coverage and performance. If getting test results takes longer, people will look for ways and reasons to circumvent the process.
To get feedback as early as possible, run tests that complete the fastest. You can only invest in longer tests once you have confidence in the build. Given the dependency on the team being able to do those tests and the time involved in manual testing, it’s best to limit this phase until all automated tests have been completed.
Typically, the first layer of automated tests is unit tests, which could provide wide coverage and alert you if there are obvious issues with the latest change. After unit tests, you may have an automated integration layer or component tests that test interactions between various parts of the code.
CI/CD security
The need for security in a world where vulnerabilities and breaches continue to escalate could not be emphasized enough. Since the CI/CD pipeline offers access to the codebase and credentials to deploy in different environments, it’s often the main target. Keep in mind that it’s not unusual for credentials to be stored in private repositories for automation.
That is why it’s important to consider isolating the CI/CD systems and putting them in secure internal networks. A robust two-factor authentication, VPNS, and identity and access management systems help restrict exposure to threats. For instance, you can containerize agents and put them on secure networks.
Furthermore, ensure that security is baked into the process of development, from beginning to end, which is commonly known as DevSecOps.
Build once, test many times
Each CI pipeline starts with a build phase wherein the artifact is built. In this phase, we:
- Download all dependencies and compile or assemble an executable file.
- Run unit, end-to-end, and integration tests, as well as other relevant tests.
- Apply liners as well as other quality-checking tools to a code.
What is important is that the process of building happens only once. The resulting artifact is saved and used in all tests later. Running all tests on the same artifact ascertains accurate and consistent results. Afterward, when all tests pass, the artifact will be released. Where to store the artifact built once depends on its nature. Executables and compiled binaries could be stored in an artifact store and published when ready. Container images, however, typically go to registries, such as Docker Hub.
CI/CD platform
CI or Continuous Integration is the software development industry standard since it allows developers to release features at a sustainable and predictable rate. By adhering to the best CI practices, developers merge their changes into the main branch several times in a day, thus the ‘continuous’ in CI.
Every code push will initiate an automatic build and test phase, which:
- Informs developers about the code quality
- Verifies that the app is still in a buildable phase
- Detects errors fast, enabling the developer to fix them in just minutes or revert the change and try again later
The process of continuous integration could be extended with continuous delivery. Continuous delivery builds deployable artifacts to be deployed or released. The task of continuous delivery is to confirm that the app is always in a releasable phase.
Monitor and measure your pipeline
Like the software you’re releasing, the CI/CD pipeline also benefits from a feedback loop. By analyzing the metrics gathered by the CI/CD tool, you can identify potential problems and areas for improvement. Comparing the number of builds triggered per hour, day, or week provides useful insight into how the pipeline infrastructure is used.
Furthermore, it also determines whether you need to scale it up or down and when the peak load occurs. Keeping track of the deployment speed over time and monitoring whether they tend to take longer could indicate if it’s time to invest in performance optimizations.
Automated test statistics could help determine areas that benefit from parallelization. Test results review could help find those that are routinely ignored and could identify the potential for simplifying the test coverage.
Conclusion
A CI/CD pipeline enables a significantly faster time to market for new product features. This creates happier customers as well as decreases the strain and stress in software development.
Gain Debugging Superpowers
Unleash the power of session replay to reproduce bugs and track user frustrations. Get complete visibility into your frontend with OpenReplay, the most advanced open-source session replay tool for developers.
