Five Practical Use Cases for Regular Expressions
See practical situations in which regular expressions are the solution


Certain technologies in the wide field of computer programming possess the capability to revolutionize how we manipulate and extract information from textual content. Regular expressions emerge as a fundamental and indispensable component of every developer’s arsenal among these powerful tools. Regular expressions, commonly called
RegEx, offer programmers an efficient and versatile solution for various programming applications. This tutorial will explore their importance and show five practical use cases for them, including data validation, data extraction, log parsing, search and replace, and Data Cleaning.

Discover how at OpenReplay.com.
Regular expressions, commonly referred to as RegEx, are robust patterns utilized for searching, matching, and manipulating text data. RegEx plays a vital role in performing validation and text extraction operations. It offers powerful functionality to efficiently search for and replace specific patterns within a text string.
With Regex, you can process log files, extract specific data from text documents, redirect URLs, and validate user input text in web forms, among other applications.
How does a RegEx work?
RegEx operates by defining a pattern that represents a specific set of characters or sequences. This pattern is then applied to a target text to identify matches or perform transformations. Here’s a brief overview of regex syntax, with the basic components and operations most frequently used:
-
Literals: Regular expressions can consist of literal characters that match themselves exactly. For example, the pattern “hello” would match the string “hello” in the target text.
-
Metacharacters: Metacharacters are special characters with a special meaning within a regular expression. Examples include:
.(dot): Matches any character except a newline character.*(asterisk): matches one or more instances of any character.+(plus): Matches one or more occurrences of the preceding character.?(question mark): Matches zero or one occurrence of the preceding character.[](square brackets): Define a character class, matching any character within the brackets.()(parentheses): Creates a capture group for capturing matched subpatterns.
- Modifiers: Modifiers specify additional rules for matching. Common modifiers include:
i: Case-insensitive matching.g: Global matching (matches all occurrences rather than stopping at the first match).m: Multiline matching.
- Anchors: Anchors are used to specify the position of a match within the text. Examples include:
^(caret): Matches the start of a line.$(dollar sign): Matches the end of a line.
Combining these components and operations allows you to create intricate and powerful patterns to search, validate, and transform text data using regular expressions.
In the following sections, we will delve into five practical use cases that demonstrate the versatility and effectiveness of regular expressions (RegEx).
Data validation
Data validation is the process of using RegEx patterns to determine if the input string data matches the desired format or criteria. Data validation ensures that data entered or imported is accurate and consistent and conforms to predefined rules. By doing so, it prevent errors and upholds the integrity of data. Now, let’s explore two practical examples of data validation:
- Email Validation
Email Validation is a way of confirming the legality and correctness of an email address. It entails determining whether the email address is properly formatted or exists. Email validation ensures that the email addresses obtained or submitted are valid and useful for communication.
- Password Validation Password validation is one of the important use cases for Regular expression. With RegEx, you can create a simple application and enforce a pattern on password verification, and if it doesn’t meet the requirement, it won’t log the user in.
Let’s create a simple application that will give you a thorough grasp of how Email and Password Validation work. Paste the following code into an HTML file.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Validated Registration Form</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="container">
<h2 class="label">User Details</h2>
<div class="Reg_form" action="login.html" method="post" name="Login-form">
<label class="Fname">Email $ Phone No</label>
<input type="text" name="email" id="mail">
<div id="ERROR">Kindly Fill the correct details</div>
<label id="Fpassword">Password</label>
<input type="text" name="Password" id="Pass">
<div id="InvalidPassword">Note! Input correct Password only</div>
<button type="button" onclick="validated()">Login Here</button>
</div>
</div>
<script src="style.js"></script>
</body>
</html>Let’s add the script file, create Script.js, and add the following code.
function validated() {
var emailInput = document.getElementById('mail').value;
var passwordInput = document.getElementById('Pass').value;
// Regular expressions for email and password validation
var emailRegex = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;
var passwordRegex = /^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,}$/;
if (!emailRegex.test(emailInput)) {
document.getElementById("ERROR").style.display = "block";
document.getElementById("InvalidPassword").style.display = "none";
return false;
} else if (!passwordRegex.test(passwordInput)) {
document.getElementById("ERROR").style.display = "none";
document.getElementById("InvalidPassword").style.display = "block";
return false;
} else {
document.getElementById("ERROR").style.display = "none";
document.getElementById("InvalidPassword").style.display = "none";
window.location.href = "login.html";
return true;
}
}The code lets you input an email and validates its format, including the domain name. It also validates the entered password against specified criteria and displays an error message if the criteria are not met.
We defined two regular expressions, emailRegex and passwordRegex. For emailRegex, the ^ symbol indicates the start of a string. The [^s@]+ pattern represents one or more characters. The @ symbol specifically denotes the username part of the email. The \. matches a literal character, the dot, and finally, the $ symbol indicates the end of the string.
Regarding passwordRegex, the pattern /^(?=.*\d) specifies that at least one digit should be in the password. (?=.*[a-z]) indicates that one or more lowercase letters should be included, while (?=.*[A-Z]) implies that at least one uppercase letter should be included as well. The .{8,}$/ pattern ensures the password has a minimum length of 8 characters. If the string matches all the patterns, it should be considered a valid, strong password; otherwise, it does not meet the requirement. Thus, it logs Incorrect Password.
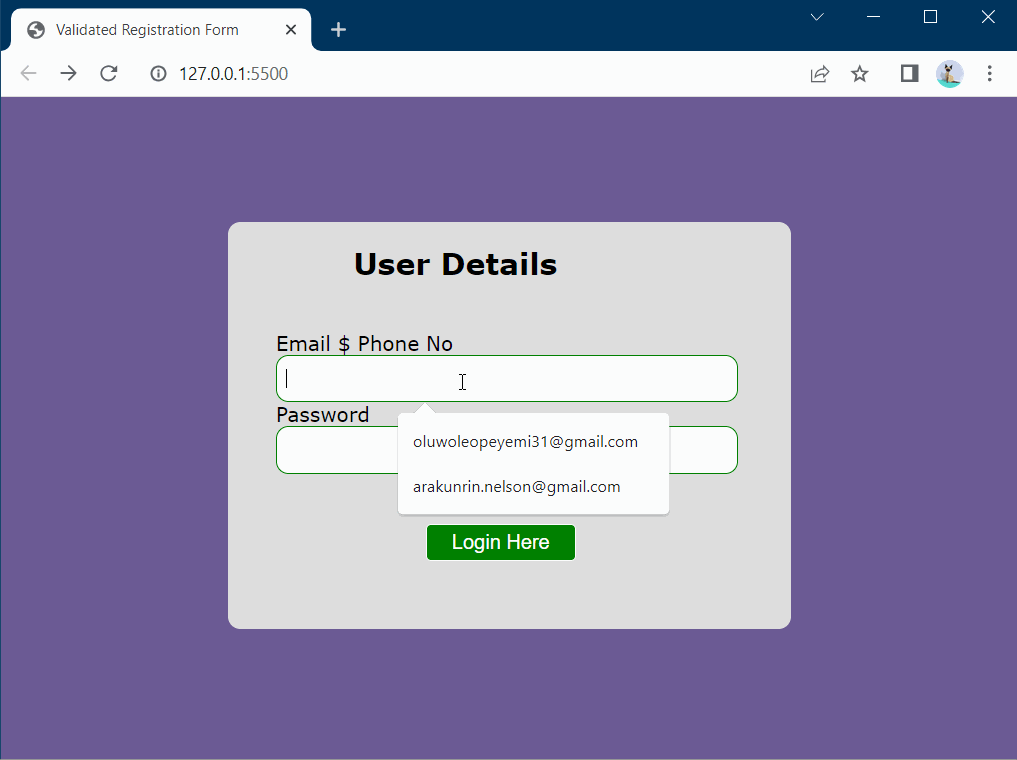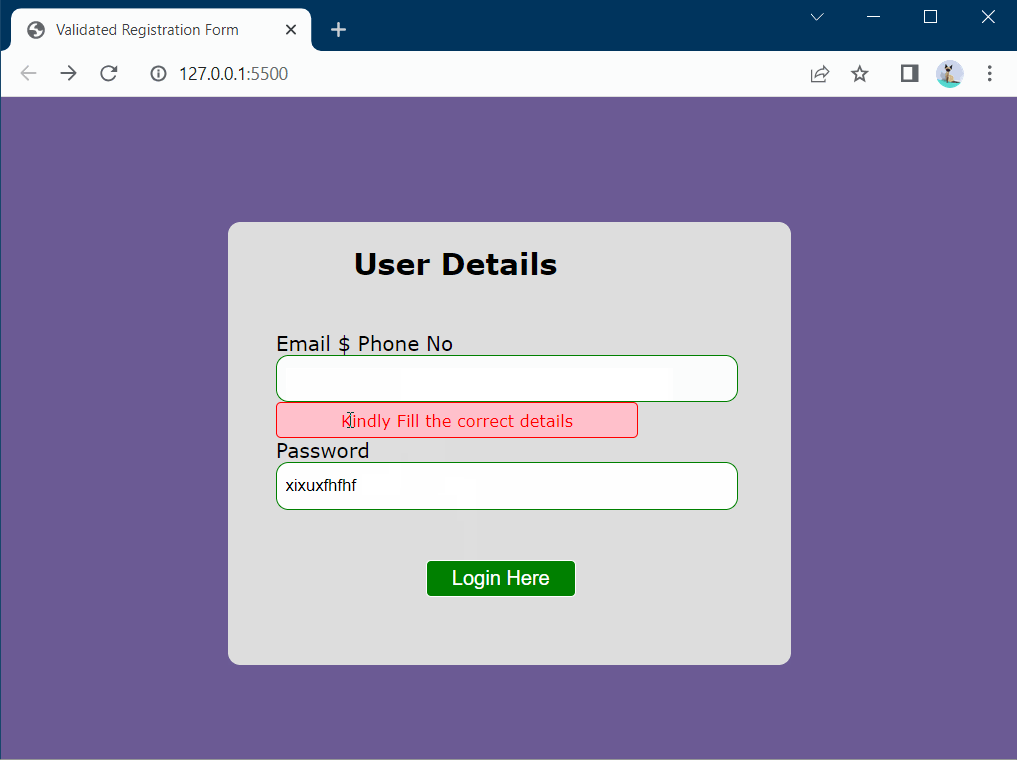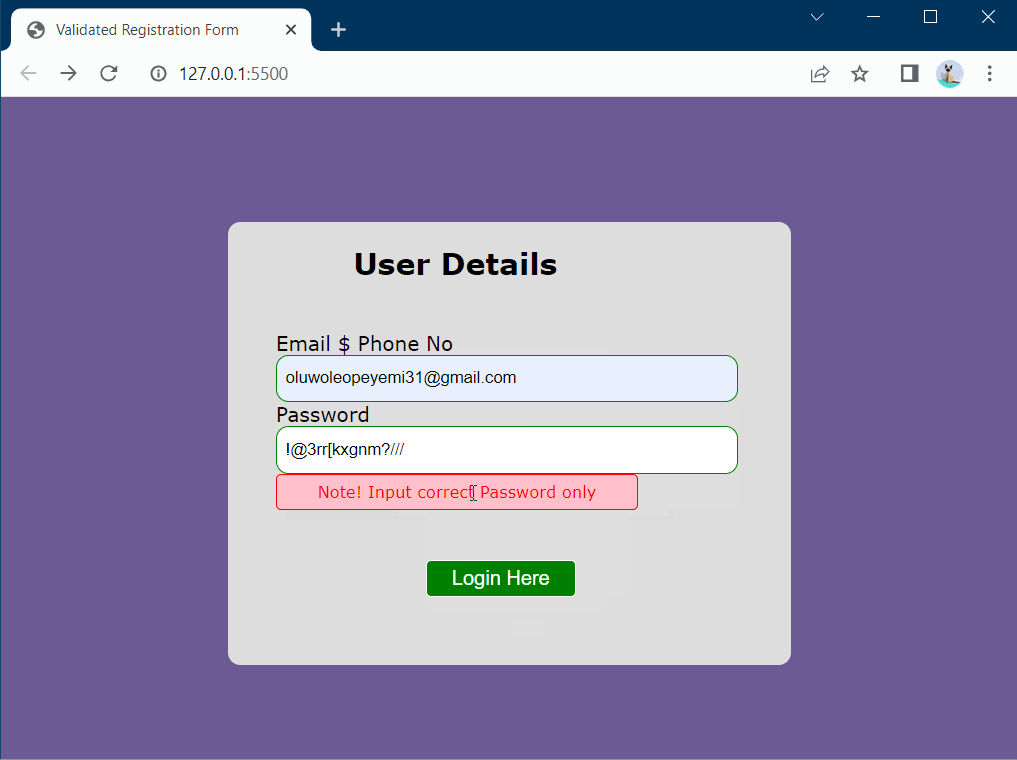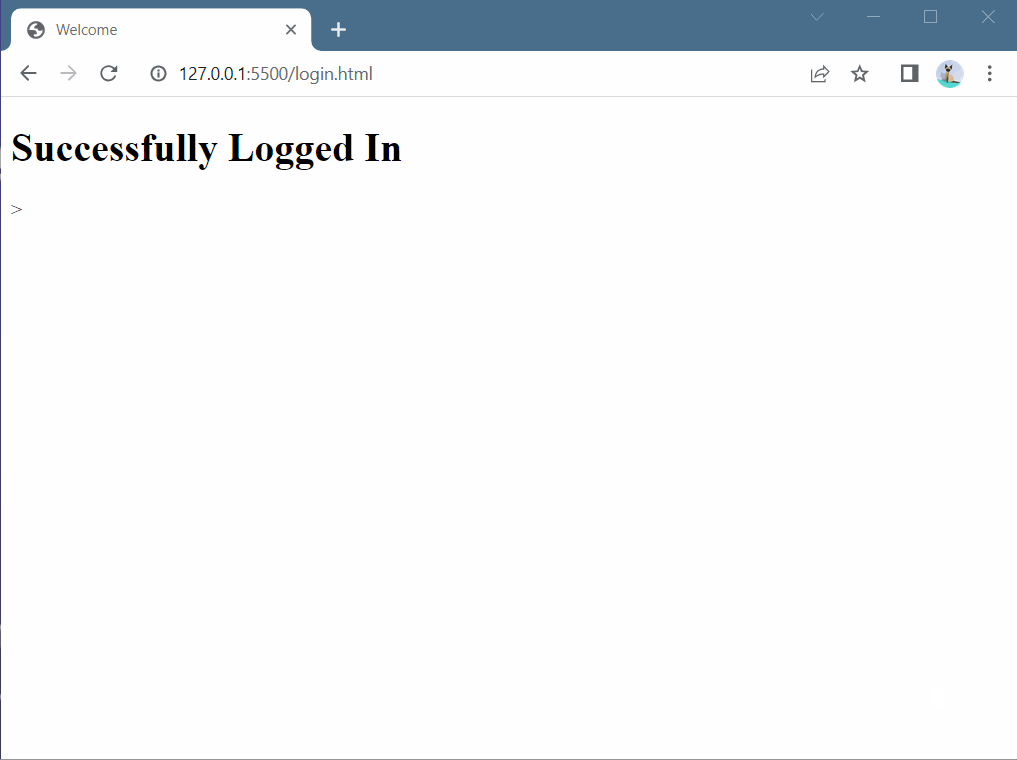
The primary objective of this simple application is to ensure users provide accurate and secure email addresses and passwords. Through validation tests, the application effectively prevents the submission of incorrect or invalid data and promptly notifies users of errors. Providing immediate feedback during the input process promotes data integrity, enhances data security, and improves the overall user experience. Don’t forget to specify the exact URL of the redirect page you want users to be directed to upon successful login.
In the context of email and password validation, RegEx ensures security by enforcing specific criteria. For instance, in the password section of the above code, we set requirements such as a minimum length, including uppercase and lowercase letters, digits, or special characters. This allows us to create strong and secure passwords.
Similarly, email addresses have a specific structure that must be followed to be considered valid. RegEx allows us to define a pattern that represents the valid format of an email address. These patterns check for essential components like the ”@” symbol to ensure correct email formatting and maintain the integrity of your contact information.
Search and Replace
Search and replace is another practical use case for regular expressions. It allows you to find specific patterns within a text and replace them with desired content.
const text = "Hello, [name]! How are you, [name]?";
const namePattern = /\[name\]/g;
const replacement = "John";
const replacedText = text.replace(namePattern, replacement);
console.log(replacedText);
// Hello, John! How are you, John?In the code above, we define a text variable with a sample sentence containing the pattern [name] twice. The namePattern variable is the regular expression pattern \[name\] that matches the exact string “[name]”. The g flag is added to perform a global search and replace.
The words “search” and “replace” in this example relate to utilizing regular expressions to find a certain pattern in the text variable and then replacing that pattern with the content supplied in the replacement variable.
We set the replacement variable as “John” to replace the matched pattern. Using the replace() method on the text string with namePattern and replacement as arguments, we obtain a new string with the matched patterns replaced.
So, Contextually, “search” refers to using the regular expression namePattern to identify all occurrences of the [name] pattern in the text variable, and “replace” refers to replacing all these occurrences with the content specified in the replacement variable, which is “John” in this example.
Data Extraction
Data extraction is a common use case for regular expressions, especially in web scraping or text analysis applications. Regular expressions allow us to efficiently extract specific information from a larger text based on defined patterns. Let’s consider a real-world example of extracting URLs from text using regular expressions in JavaScript.
const text = "Visit our website at https://www.example.com for more information. For online shopping, go to https://shop.example.com.";
const urlPattern = /https?:\/\/[^\s]+/g;
const extractedURLs = text.match(urlPattern);
console.log("Extracted URLs:");
console.log(extractedURLs);In the above example, we have a text variable that contains a sample text with URLs embedded within it. We define the urlPattern variable as the regular expression pattern to match URLs. The pattern https?:\/\/[^\s]+ matches URLs starting with “http://” or “https://” and captures all non-whitespace characters after that.
Using the match() method on the text string with the urlPattern, we can extract all the URLs in the text. The method returns an array extractedURLs containing the extracted URLs.
In this case, the output will be:
Extracted URLs:
[
'https://www.example.com',
'https://shop.example.com'
]This example showcases how regular expressions enable us to efficiently extract URLs from text.
Log parsing
In simple terms, log parsing refers to the process of taking information out of a log so that the values can be processed and utilized as input for another logging operation. This information may include User activities, TimeStamps, and error messages. One good advantage of log parsing is that it is useful to identify security threats and troubleshoot problems.
If, for example, we have a log with the following data structure:
[2023-07-01 15:30:20] INFO: Application started.
[2023-07-01 15:32:45] ERROR: Database connection failed.
[2023-07-01 15:34:12] INFO: User logged in (username: john_doe).
[2023-07-01 15:40:03] WARNING: Disk space low, consider freeing up space.
[2023-07-01 15:45:18] ERROR: Request timed out (url: /api/data).… that was saved in a file named sample.log, and we’re trying to access lines with the “ERROR” label using regular expressions, we can utilize Node.js with the built-in fs module to read the log file and filter out the relevant log entries.
Here’s an improved JavaScript code to achieve this using RegEx:
const fs = require('fs');
const logFilePath = 'sample.log';
fs.readFile(logFilePath, 'utf8', (err, data) => {
if (err) {
console.error(`Error reading ${logFilePath}: ${err.message}`);
return;
}
const errorLines = data.match(/^\[.*\] ERROR:.*/gm);
console.log('Log entries with "ERROR" label:');
console.log(errorLines.join('\n'));
});In the code above, we read the contents of the sample.log file using fs.readFile() as before. We then use the match() method on the data string with the RegEx pattern ^\[.*\] ERROR.* to find and extract the lines that start with a timestamp as a bracket expression ([...]) and have the “ERROR” label. The gm flags match multiple occurrences and treat the input as a multi-line string.
The match() method returns an array errorLines containing all the log entries that match the pattern.
Finally, we print the log entries with the “ERROR” label to the console. The output will display only the log lines with the “ERROR” label.
Data Cleaning
To ensure consistency and remove irrelevant characters or formatting from text data, Data cleaning is an important step in the preprocessing of data. By enabling effective pattern-based transformations, regular expressions play a crucial part in this process. Let’s look at a real-world JavaScript example of data cleansing using regular expressions.
Suppose we have a dataset containing product descriptions, but some of the descriptions include unnecessary special characters or symbols. We want to clean the data by removing these unwanted characters.
const dataset = [
"Product A - $99.99",
"Product B: 50% off!",
"Product C - *Limited Stock*",
"Product D (New Arrival)"
];
const cleanPattern = /[^a-zA-Z0-9\s]/g;
const cleanedData = dataset.map(description => description.replace(cleanPattern, ""));
console.log("Cleaned Data:");
console.log(cleanedData);The dataset array in the aforementioned example contains sample product descriptions. We declare the cleanPattern variable as the regular expression pattern that matches any characters other than alphabetic, numeric, and whitespace to clean the data. Any undesirable special character (any symbol that isn’t an alphanumeric character) will be captured by the pattern [^a-zA-Z0-9s].
We again iterate through each description using the map() method on the ‘dataset’ array. Then we use the replace() method and the cleanPattern to replace the undesirable characters with an empty string.
The output will be:
Cleaned Data:
[
"Product A 99.99",
"Product B 50 off",
"Product C Limited Stock",
"Product D New Arrival"
]Conclusion
Regular expressions are a versatile programming tool for various tasks such as Data cleaning, log parsing, data validation, extraction, and search and replace. They enable complex patterns to be easily matched and provide a flexible and efficient way to handle text-based operations.
Regular expressions help us to automate and streamline processes when working with large datasets, user inputs, or text-based applications. By utilizing the power of regular expressions, you may enhance the precision and effectiveness of your code and provide better results in less time.